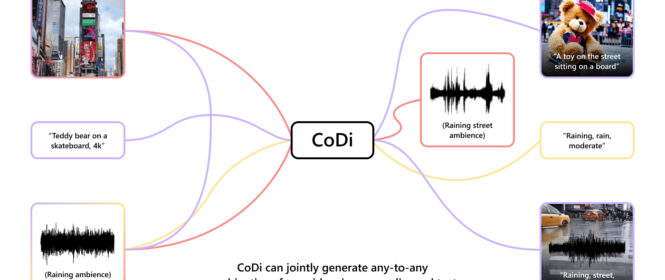
Imagine an AI model that can seamlessly generate high-quality content across text, images, video, and audio, all at once. Such a model would more accurately capture the multimodal nature of the world and human comprehension, seamlessly consolidate information from a wide range of sources, and enable strong immersion in human-AI interactions. This could transform the … Continue reading Breaking cross-modal boundaries in multimodal AI: Introducing CoDi, composable diffusion for any-to-any generation