
How do humans communicate efficiently? The common belief is that the words humans use to communicate – such as dog, for instance – invoke similar understanding of the physical concepts. Indeed, there exists a common conception about the physical appearance of a dog, the sounds dogs make, how they walk or run, and so on. In other words, natural language is tied to how humans interact with their environment. As a result, meaning emerges through grounding natural language in modalities in our environment (for example, images, actions, objects, sounds, and so on). Recent studies in psychology have shown that a baby’s most likely first words are based on its visual experience, laying the foundation for a new theory of infant language acquisition and learning. Now the question researchers are asking is if we can build intelligent agents that can learn to communicate in different modalities as do humans.
Among various multi-modality learning tasks, Vision-Language Navigation (VLN) is a particularly interesting and challenging task because, in order to navigate an agent inside real environments by following natural language instructions, one needs to perform two levels of grounding—grounding an instruction in the local spatial visual scene, and matching the instruction to the global temporary visual trajectory. Recent works in deep neural networks focus on building intelligent agents via bridging visual and natural language understanding through visually-grounded language learning tasks, requiring expertise in machine learning, computer vision, natural language, and other realms. Deep learning in particular is promising for grounding because with deep learning it is possible to learn high-level semantics from low-level sensory data in both computer vision and language. In addition, deep learning models enable fusing different modalities into a single representation. Grounded language acquisition also requires interacting with an external environment; thus, reinforcement learning provides an elegant framework to cover the planning aspect of visually grounded dialogue. All such research advances have made it technically feasible to tackle the challenging VLN task.

Figure 1: Demonstration of the VLN task. The instruction, the local visual scene, and the global trajectories in a top-down view. The agent does not have access to the top-down view. Path A is the demonstration path following the instruction. Path B and C represent two different paths executed by the agent. Figure credit: Wang et al. (2019).
Spotlight: On-demand video

AI Explainer: Foundation models and the next era of AI
Explore how the transformer architecture, larger models and more data, and in-context learning have helped advance AI from perception to creation.
Vision and language researchers at Microsoft Research have been working on different ways to ground natural language and visual interactions and have been dealing with challenges unique to VLN. In “Reinforced Cross-Modal Matching and Self-Supervised Imitation Learning for Vision-Language Navigation” (a joint work by Qiuyuan Huang, Asli Celikyilmaz, Lei Zhang, and Jianfeng Gao of Microsoft Research AI, Xin Wang, Yuan-Feng Wang and William Yang Wang of University of California Santa Barbara, and Dinghan Shen of Duke University) presented this month in Long Beach, California at the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), our VLN research team explored how to address three critical challenges in VLN—cross-modal grounding, ill-posed feedback, and generalization. The results of our efforts are very encouraging.
One of the challenges is learning to reason over visual images and natural language instructions. As demonstrated in Figure 1, to reach the destination (highlighted by a yellow circle), an intelligent agent needs to ground an instruction in the local visual scene, represented as a sequence of words, as well as match the instruction to the visual trajectory in the global temporal space. To remedy this issue, we introduced a novel Reinforced Cross-Modal Matching (RCM) approach that enforces cross-modal grounding both locally and globally via reinforcement learning.
As shown in Figure 2a, the team designed a reasoning navigator equipped with two rewards. The extrinsic reward tells the agent to learn the cross-modal grounding between both the textual instruction and the local visual scene, so that the agent can infer which sub-instruction to focus on and where to look. Meanwhile, from the global perspective, the intrinsic reward, together with a matching critic, evaluates an executed path by the probability of reconstructing the original instruction from it, which we refer to as the cycle-reconstruction reward.
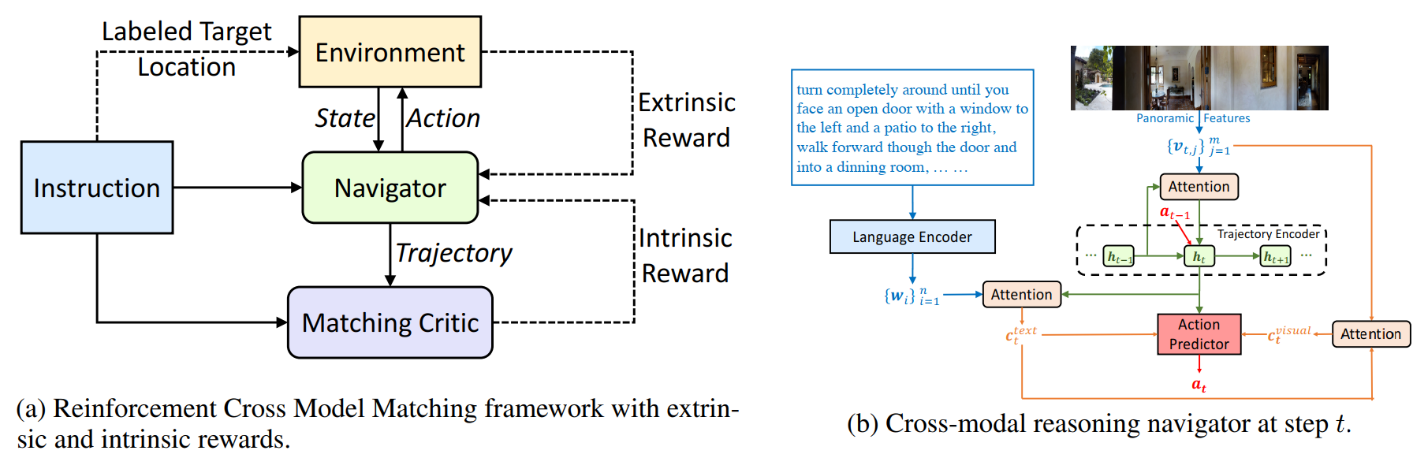
Figure 2: The architecture of the Reinforced Cross model matching framework for grounding natural language instructions to a visual environment. Figure credit: Wang et al. (2019).
The intrinsic reward is particularly crucial to this VLN task; one important challenge faced by the VLN researchers is related to how these intelligent agents are trained and the feedback they receive from the environment. During training, learning to follow expert demonstrations requires frequent feedback so that the agent can stay on track and reach the destination on time. However, in VLN, the feedback is rather coarse, because “Success” feedback is provided only when the agent reaches a target position, completely ignoring whether the agent has followed the instructions (Path A in Figure 1), or followed a random path to reach the destination (Path C in Figure 1). Even a “good” trajectory that matches an instruction can be considered unsuccessful if the agent stops marginally earlier than it should (Path B in Figure 1). An ill-posed feedback can potentially deviate from the optimal policy learning. As shown in Figure 2a and 2b, we proposed to evaluate the agent’s instruction-following capability by locally measuring a cycle-reconstruction reward; this provides a fine-grained intrinsic reward signal to encourage the agent to better understand the language input and penalizes the trajectories that do not match the instructions. For instance, using the proposed reward, Path B is considered better than Path C, as can be seen in Figure 1.
Trained with intrinsic rewards from the matching critic and extrinsic rewards from the environment, our reasoning navigator learned to ground the natural language instruction on both local spatial visual scene and global temporal visual trajectory. Evaluation on a VLN benchmark dataset shows that our RCM model significantly outperforms previous methods by 10% in terms of SPL (success rate weighted by inverse path length), achieving new state-of-the-art performance.
VLN agents’ performance degrades significantly when put in environments unseen at training time. To narrow the gap, we proposed an effective solution to explore unseen environments with self-supervision. With this new technique, we can facilitate lifelong learning and adaption to new environments. For example, domestic robots can explore a new home and iteratively improve the navigation policy by learning from previous experience. Motivated by this fact, we introduced a Self-Supervised Imitation Learning (SIL) method in favor of exploration on unseen environments that do not have labeled data. The agent learns to imitate its own past, positive experiences.
Specifically, in our framework, the navigator performs multiple roll-outs, of which good trajectories (determined by the matching critic) are stored in the replay buffer and later used for the navigator to imitate. In this way, the navigator can approximate its best behavior that leads to a better policy. We were able to demonstrate that SIL can approximate a better and more efficient policy, which tremendously minimizes the success rate performance gap between seen and unseen environments (from 30.7% to 11.7%).
We’re immensely honored that this paper was selected as Best Student Paper at CVPR 2019. In the words of the CVPR 2019 Best Paper Award Committee, “Visual navigation is an important area of computer vision. This paper makes advances in vision-language navigation. Building on previous work in this area, this paper demonstrates exciting results based on self-imitation learning within a cross-modal setting.” Warm congratulations to the authors—Xin Wang, Yuan-Fang Wang and William Yang Wang of University of California Santa Barbara, Qiuyuan Huang, Asli Celikyilmaz, Lei Zhang, and Jianfeng Gao of Microsoft Research AI, and Dinghan Shen of Duke University. Xin Wang’s contributions to this work took place in part while interning at Microsoft Research.
In another CVPR 2019 paper, “Tactical Rewind: Self-Correction via Backtracking in Vision-and-Language Navigation” (a joint work by Xiujun Li and Jianfeng Gao from Microsoft Research AI, Liyiming Ke, Yonatan Bisk, Ari Holtzman, Yejin Choi and Siddhartha Srinivasa of the University of Washington, and Zhe Gan and Jingjing Liu of Microsoft Dynamics AI), we improved the search method of VLN agents by presenting a general framework for action decoding called Fast Navigator that enables agents to compare partial paths with different lengths based on local and global information, and backtrack when making a mistake.
We noticed that VLN tasks share some similarity with text generation; all existing work falls into two main categories: Greedy search – the agent only considers the local information when making a decision at each time step. All the agents suffer from the exposure bias issue, a typical problem in sequence generation tasks; Beam search – the other extreme. The agent roll-outs multiple trajectories and selects the top one. Although this approach improves the success rate, it incurs a cost proportional to the number of trajectories, which can be prohibitively high. No one would likely deploy a household robot that re-navigates an entire house 100 times before executing each command, even if it ultimately arrives at the correct location.
Overall, there are two central questions facing current VLN models. Firstly, should we backtrack? And if so, where should we backtrack to? And secondly, when do we terminate a search? To enable the agent to backtrack when making a mistake, we marry the search with neural decoding; this allows the agent to compare partial paths of different lengths based on local and global information and then backtrack if it discerns a mistake. To determine whether we terminate the search, we use a fusion function that converts local action knowledge and history into an estimated score of progress, which evaluates the agent progress to the goal by modeling how closely our previous actions align with the given text instructions.
We look forward to sharing our findings and ideas with our fellow attendees at CVPR 2019 in Long Beach and hearing what you think. In the meantime, we encourage you to check out the papers for yourself!



