In the news | SiliconAngle
Microsoft open-sources AI algorithms for optimizing farm operations
Microsoft Corp. today open-sourced FarmVibes.AI, a collection of artificial intelligence models that farm operators can use to perform tasks such as planting crops more efficiently. FarmVibes.AI is one of several technologies that Microsoft has developed as part of an initiative…
In the news | MICROSOFT AZURE BLOG
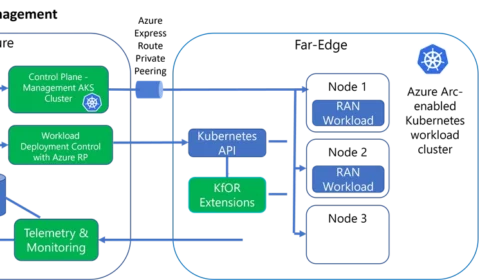
Scalable management of virtualized RAN with Kubernetes
At Microsoft, we believe our Azure system and network management tools and expertise can be repurposed to manage and optimize telecommunication infrastructure as well. Here we describe some of the more interesting technologies that fit into the management of a…
In the news | Microsoft on the Issues - LinkedIn
Tech Issues Explained: Broadband Access
Take a minute and think: How you do your banking, get updates from friends, submit school assignments or even do your job? For billions of people, the answer is “through the internet.” Or in other words, with a fast broadband internet…

Research Focus: Week of September 26, 2022
Research Focus highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
Paper (opens in new tab) / Code (opens in new tab) / Demo (opens in new tab) / Docs (opens in new tab) Modern machine learning models are known to fail in ways that aren’t anticipated during training these models. These…

Pushing the limit of semi-supervised learning with the Unified Semi-supervised Learning Benchmark
Neural models give competitive results when trained with supervised learning using sufficient high-quality labeled data. For example, according to statistics from the Paperswithcode website, recent traditional supervised learning methods can achieve an accuracy of over 88% on the ImageNet dataset,…

AI+生物医药,如何双向赋能?
编者按:近年来,人工智能的深入发展助力生物医学研究取得了重大突破。“AI+生物医药”成为了学术界和产业界都非常关注的热门赛道。在后疫情时代, “AI+生物医药”能否保持强劲的发展态势,又将面临哪些机遇与挑战? 在世界人工智能大会2022的上海生物计算论坛上,微软杰出首席科学家、微软研究院科学智能中心亚洲区负责人、微软亚洲研究院副院长刘铁岩与上海市生物医药促进中心副主任唐军,华深智药创始人兼CEO彭...
USB:首个将视觉、语言和音频分类任务进行统一的半监督分类学习基准
作者:王一栋、王晋东 编者按:当前,半监督学习的发展如火如荼。但是现有的半监督学习基准大多局限于计算机视觉分类任务,排除了对自然语言处理、音频处理等分类任务的一致和多样化评估。此外,大部分半监督论文由大型机构发表,学术界的实验室往往由于计算资源的限制而很难参与到推动该领域的发展中。为此,微软亚洲研究院的研究员们联合西湖大学、东京工业大学、卡内基梅隆大学、马克斯-普朗克研究所等机构的科研人员提出了...
An “event-based” A/B test is a method used to test two or more variables during a limited duration. We can use what we learn to increase user engagement, satisfaction, or retention of a product, while also applying our insights to…