

The goal of Probase is to make machines “aware” of the mental world of human beings, so that machines can better understand human communication. We do this by giving certain general knowledge or certain common sense to machines.
-
h2>News
- Zhongyuan Wang (opens in new tab) (wzhy (AT) outlook. com)
- Haixun Wang
- Wei-Ying Ma
-
This page the data statistics of the taxonomy we build. In addition, proofs of Theorem 1 and 2 in Section 3.6 can be found here (opens in new tab), which are related to the taxonomy construction framework.
General Information
Table 1: Scale comparison of several open domain taxonomies
name # of concepts # of isA pairs Freebase 1,450 24,483,434 WordNet 25,229 283,070 WikiTaxonomy 111,654 105,418 YAGO 352,297 8,277,227 DBPedia 259 1,900,000 ResearchCyc ≈ 120,000 < 5,000,000 KnowItAll N/A < 54,753 TextRunner N/A < 11,000,000 OMCS 173,398 1,030,619 NELL 123 < 242,453 Probase 2,653,872 20,757,545 We extract 326,110,911 sentences from a corpus containing 1,679,189,480 web pages, after sentence deduplication. To the best of our knowledge, the scale of our corpus is one order of magnitude larger than the previously known largest corpus. We then extract 143,328,997 isA pairs from the sentences, with 9,171,015 distinct super-concept labels and 11,256,733 distinct sub-concept labels.
The inferred taxonomy contains 2,653,872 distinct concepts (down from 9.17 million after the extraction phase), 16,218,369 distinct concept-instance pairs, and 4,539,176 distinct concept-subconcept pairs (20,757,545 pairs in total). The number of concept labels decreases since we have changed all labels to lowercases and flatten the concepts with only one instance (and refer to them as instances).
As comparison, Table 1 shows statistics of several well-known open-domain taxonomies in comparison with Probase. For WordNet (opens in new tab), we only count the sub-taxonomy related to nouns in WordNet, and we have converted synsets in WordNet to their lexical form. For Freebase (opens in new tab), the statistics are obtained from a version downloaded in early Match, 2010. More than 3,000 topics in this data source are incorrect and cannot be found on the official Freebase website, and are therefore ignored in our analysis. For ResearchCyc (opens in new tab), the number of isA pairs shown is in fact the number of all the relationships, since the exact numbers are not reported. For YAGO (opens in new tab), the statistics are obtained from its latest version (Dec. 2010), and the number of isA pairs is inferred by summing up the number of SubConceptOf and Type relations reported.
For completeness, in Table 1, we have also included statistics for KnowItAll, TextRunner, OMCS (opens in new tab), and NELL (opens in new tab). However, these frameworks are not intended to build a taxonomy as we desired, but to extract general facts that may indicate various relationships between concepts or entities. Therefore, it is usually hard to tell concepts from entities, and also hard to tell how many isA pairs are among all the pairs, if not reported.
Concept Space
Given that Probase has many more concepts than any other taxonomies, a reasonable question to ask is how many of these concepts are relevant. This question is akin to the precision measure in information retrieval (IR). Here for the purpose of comparison, we define a concept to be relevant, if it appears at least once in web queries. We analyzed Bing (opens in new tab)´s query log from a two-year period, sorted the queries in decreasing order of their frequency (i.e., the number of times they are issued through Bing), and computed the number of relevant concepts in Probase and 4 other general-purposed open-domain taxonomies WordNet (opens in new tab), WikiTaxonomy (opens in new tab), YAGO (opens in new tab), and Freebase (opens in new tab), with respect to the top 50 million queries. Figure 1 shows the result.

Figure 1: Number of relevant concepts in taxonomies
In total, 664,775 concepts are considered relevant in Probase, compared to 70,656 in YAGO. This reflects the well-known long-tail phenomena of user queries. While a small number of basic concepts (e.g., company, city, country) representing common sense knowledge appear very frequently in user queries, Web users do mention other less well-known concepts. Probase does a better job at capturing these concepts in the long tail and hence has a better chance of understanding these user queries.
We next measure the taxonomy coverage of queries by Probase, which is akin to the recall measure in IR. A query is said to be covered by a taxonomy if the query contains at least one concept or instance within the taxonomy. Figure 2 compares the coverage of queries by Probase taxonomy against the other four aforementioned taxonomies. Probase outperforms all the other taxonomies on the coverage of top 10 million to top 50 million queries. In all, Probase covers 40,517,506 (or, 81.04%) of the top 50 million queries.
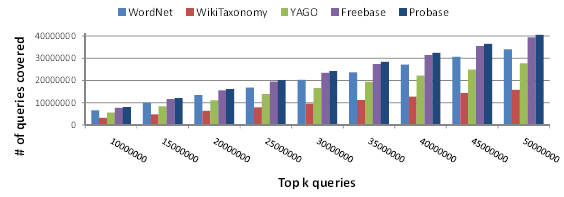
Figure 2: Taxonomy coverage of the top 50 million queries
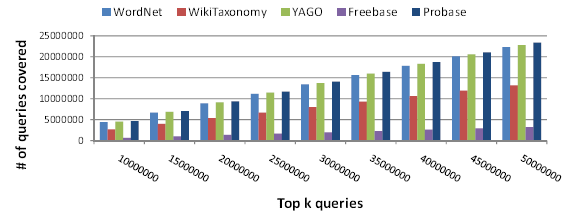
Figure 3: Concept coverage of the top 50 million queries
We further measure concept coverage, which is the number of queries containing at least one concept in the taxonomy. Figure 3 compares the concept coverage by Probase against the other four taxonomies. Again, Probase outperforms all the others. Note that, although Freebase presents comparable taxonomy coverage with Probase in Figure 2, its concept coverage is much smaller.
isA Relationship Space
There are two kinds of isA relationships in Probase: the concept-subconcept relationship which are the edges connecting internal nodes in the hierarchy, and the concept-instance relationship which are the edges connecting a leaf node.
Table 2 compares the concept-subconcept relationship space of Probase with the other taxonomies. The level of a concept is defined to be one plus the length of the longest path from it to a leaf concept (i.e., concept without any subconcepts/children). All leaf concepts thus receive a level of 1. Table 1 shows that even with an order of magnitude larger number of concepts, Probase still has a similar hierachical complexity to the other taxonomies. The exception is Freebase which exhibits trivial values on these measured metrics because it has no isA relationship among its concepts at all.
Table 2: The concept-subconcept relationship space
# of isA pairs Avg # of children Avg # of parents Avg level WordNet 283,070 11.0 2.4 1.265 WikiTaxonomy 90,739 3.7 1.4 1.483 YAGO 366,450 23.8 1.04 1.063 Freebase 0 0 0 1 Probase 4,539,176 7.53 2.33 1.086 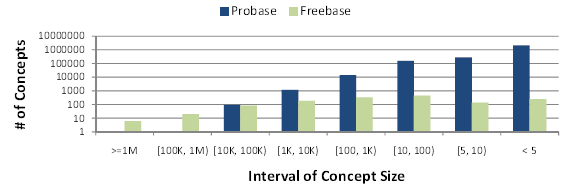
Figure 4: Concept size distributions in Probase and Freebase
We also compare Probase and Freebase on the concept-instance relationships. We choose Freebase since it is the only existing taxonomy with comparable scale on instance space (24,483,434 concept-instance pairs, see Table 1). We define concept size to be the number of instances directly under a concept node. Figure 4 (logarithmic scale on the Y-axis) compares distributions of concept sizes in Probase and Freebase. While Freebase focuses on a few very popular concepts like track and book which include over two million instances, Probase has many more medium to small size concepts. In fact, the top 10 concepts in Freebase contain 17,174,891 concept-instance pairs, or 70% of all the pairs it has. In contrast, the top 10 concepts in Probase only contains 727,136 pairs, or 4.5% of its total. Therefore, Probase provides a much broader coverage on diverse topics, while Freebase is more informative on specific topics. On the other hand, the instances of large concepts in Freebase like book are mostly from specific websites like Amazon, which could be easily merged into Probase using the integration framework we proposed.
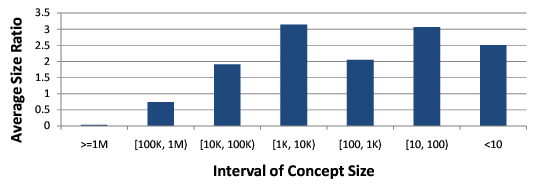
Figure 5: Relative size of sample concepts to Freebase
Moreover, due to the transitivity nature of the isA relationship, we can assume that all instances in a subconcept conceptually also belong to its superconcept. Freebase, however, lacks such concept-subconcept information and the pairs it contains are merely concept-instance pairs. So if we propagate all instances up through the taxonomy, the number of instances in each concept becomes much larger. If we take all the distinct classes in Probase which also exist in Freebase and divide them into 7 groups by their Freebase sizes, or the number of instances in each Freebase class, Figure 5 depicts the relative sizes of Probase classes in these 7 groups, which indicates that Probase clearly contains more instances in medium to smaller classes, but slightly less instances for very large and popular classes.
To estimate the correctness of the isA pairs within Probase, we create a benchmark (opens in new tab) dataset containing 40 concepts in various domains. The concept size varies from 21 instances (for aircraft model) to 85,391 (for company), with a median of 917. Benchmarks with similar number of concepts and domain coverage have also been reported in previous information extraction research. For each concept, we randomly pick up to 50 instances/subconcepts and ask human judge to evaluate their correctness and hence also the precision of the extraction algorithm. Figure 6 shows the result. The average precision of all pairs in benchmark is 92.8%, which outperforms precision frameworks like KnowItAll (64% on average), NELL (74%) and TextRunner (80% on average). It is not fair to directly compare our results with Wikipedia-based frameworks like WikiTaxonomy (86% precision) and YAGO (95% precision), whose data sources are much cleaner. Nevertheless, only YAGO has a better overall precision than Probase.
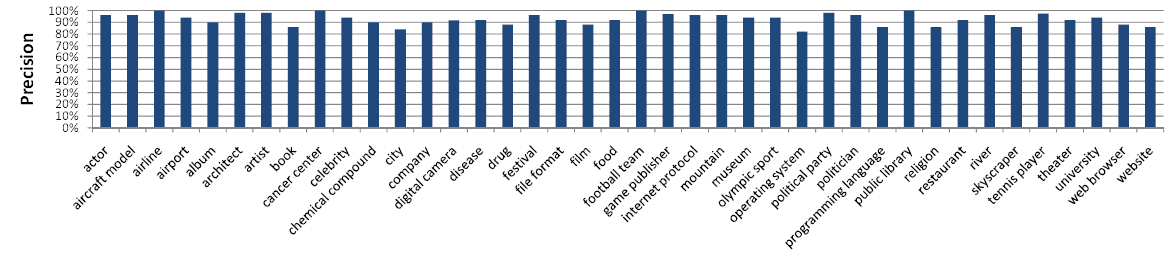
Figure 6: Precision of extracted pairs
Table 3: Precisions of Probase and KnowItAll
concept Probase KnowItAll actor 0.96 0.69 city 0.84 0.71 film 0.88 0.49 As a detailed case study, since KnowItAll also used Hearst’s patterns to extract isA relationships, we compare our precision with that of KnowItAll on actor, city and film, three concepts that are common to both systems. Table 3 shows that Probase has notable advantage in isA extraction precision over KnowItAll.
Taxonomy Scoring
Consensus Score

Figure 7: Consensus score vs. the actual percentage of true claims
We experimented with the simple model in Equation (1) for computing consensus of a claim using the benchmark concepts. We expect that the consensus scores to be approximately equal to the actual percentage of true claims as the number of evidences grows. This is verified in Figure 7. The average consensus scores matches the actual percentage of true claims (checked by human judges) quite well, except when there is only one evidence. Figure 7 has an uneven scale on the x-axis because the frequency distribution of claims in Probase has a long tail.
Typicality Score

Figure 8: Typicality evaluation results
Please click the following link to view representative instances/child concepts for classes within the benchmark.
- Top 50 instances for selected concepts in the benchmark, ordered by decreasing typicality scores. (opens in new tab)
- Top 20 subconcepts for selected concepts within the benchmark, ordered by decreasing typicality scores. (opens in new tab)
The typicality score a subconcept x of concept c receives is computed with the formula:

Since subconcepts are actually groups of instances of their parent concept, intuitively, if a subconcept contains more representative instances of the parent concept, then its typicality score should be boosted.
We further conduct a user study for this relatively subjective measure. First, we pick 10 concepts, and the top 50 instances for each concept, according to their typicality scores. Then, we invite 4 users to manually score the typicality of the instances (with order shuffled) in their respective concepts, as 3 (very representative), 2 (correct but not very representative), 1 (unknown), and 0 (incorrect).

Figure 9: Similarity evaluation results
We divide the 50 instances of each concept into 5 groups by their typicality score ranks (i.e. top 10 instances from each concept go to Group 1, second 10 instances from each concept go to Group 2, and so on), and then compute the average judge scores assigned to instances within each group. Figure 8 shows that the typicality of the instances in their classes, as perceived by human judges, decreases with computed typicality scores, which means our definition of the typicality score is sensible.
Similarity Score
For each concept (which we call host concept) in the benchmark, we pick the five most similar concepts and rank them according to the similarity scores. We thereby form 5 groups of similar concepts in decreasing order of the scores. We then ask the judges to manually rate their proximity to the host concepts on a normalized scale from 0 (least similar) to 1 (most similar). We average these judge scores in each of the 5 groups and present the results in Figure 9, which indicates that the similarity scores match the judges’ perceptions.
ProBase Browser
We have developed a browser that could be used to inspect the taxonomy we built. This page gives some snapshots of it. Example paths within the taxonomy include:
- animals → livestock → sheep …
- animals → reptiles → snakes …
- plants → trees → maples …
- artists → musicians → guitarists …
- places → restaurants → fast foods …
- foods → vegetables → cabbages …
- machines → computers → laptops …
- novels → mysteries → ghosts …
- sports → footballs …
- celebrities → athletes → gymnasts …
Snapshots
Concept search:

Instance search:
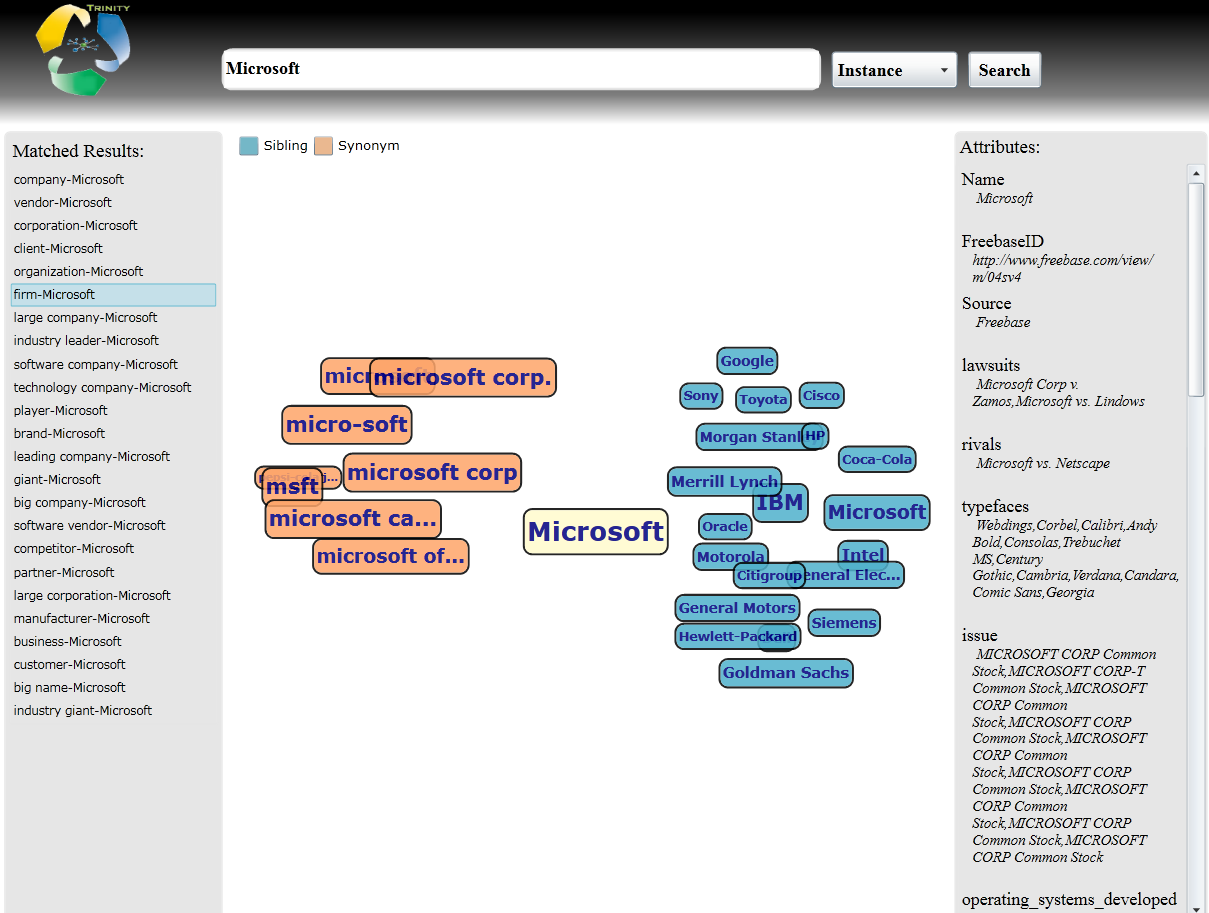
-
ProBase Browser
Probase Viewer shows the backbone of our taxonomy, such as class-subclass, class-instance and class-attribute. It also shows the results of incorporating external knowledge bases, such as freebase.
Topic Search

We present a framework that improves web search experiences through the use of Probase. The framework classifies web queries into different patterns according to the concepts and entities in addition to keywords contained in these queries.
Web Tables

We use Probase to help us interpret and understand tables, which unlocks the wealth of information hidden in web table. Then we build a semantic search engine over tables to demonstrate how much valuable information can be found in Web tables, and how structured data can empower information retrieval on the Web.
Conceptualization

Probase enables machines to conceptualize from a set of words or short text by performing Bayesian analysis based on the typicality and other probabilities. We develop several applications to show with Probase machines can “thinking” like human beings.
Probase Simple Web Interface
For users who want to try our release data, this interface integrates basic data access functions and conceptualization functions based on Probase release package. Users can easily query our knowledge base and get our results without any programming.
[Sept. 2016] Please visit our Microsoft Concept Graph (opens in new tab)release for up-to-date information of this project!
Applications
The goal of Probase to enable machines to better understand human communication. For example, in natural language processing and speech analysis, knowledgebases can help reduce the ambiguities in language. As Probase has a knowledgebase as large as the concept space (of wordly facts) in a human mind, it has unique advantages in these applications.Besides, with the probabilistic knowledge provided by Probase, we build several interesting applications, such as topic search, web table search and document understanding, shown in Figure 3.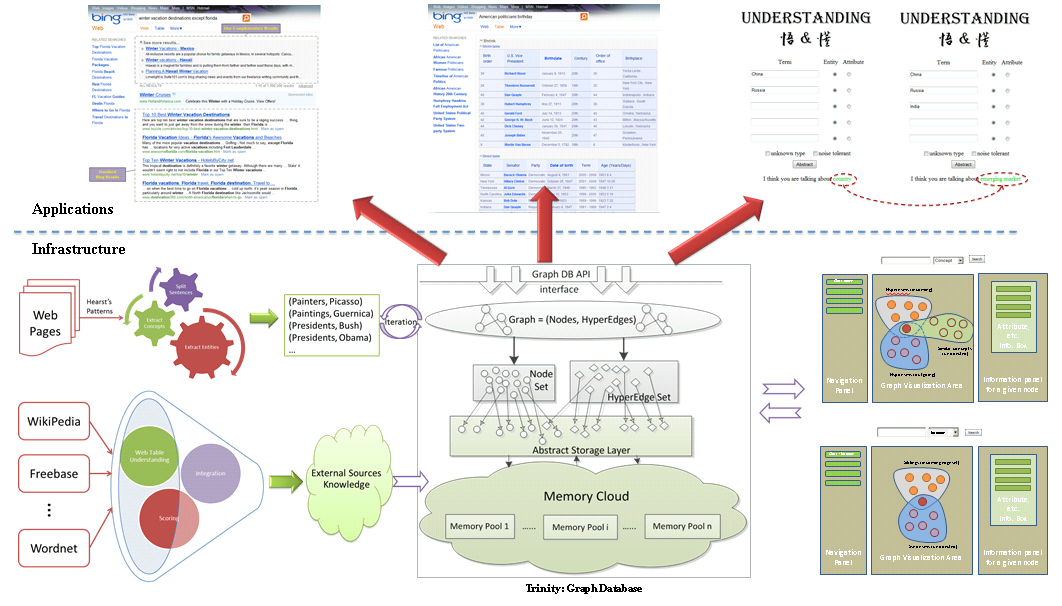
Figure 3: Overview of Probase and Its Applications