Swin Transformer supports 3-billion-parameter vision models that can train with higher-resolution images for greater task applicability
| Han Hu and Baining Guo
Early last year, our research team from the Visual Computing Group introduced Swin Transformer, a Transformer-based general-purpose computer vision architecture that for the first time beat convolutional neural networks on the important vision benchmark of COCO object detection (opens in…
In the news | New York Times
Microsoft Plans to Eliminate Face Analysis Tools in Push for ‘Responsible A.I.’
In the news | Microsoft Innovation
Tech Minutes: Swin Transformer
Learn how Swin Transformer surpasses previously dominant CNN (convolutional neural network) architectures in computer vision. Presented by Han Hu, Principal Researcher and Research Manager from Microsoft Research Asia.

As a top international academic conference in the field of natural language processing, ACL attracts paper submissions and conference participation from a large number of scholars every year. This year's ACL conference was held from May 22nd to May 27th.…

夏炎:做科学研究与技术应用的“摆渡人”
编者按:科学研究与技术创新的过程总是充满了不确定性,科研人员无法提前计算创新的周期,也无法预料每个灵感所带来的最终结果。若想将一项研究成果落地并通过产品化的方式让更多人感受到前沿技术所带来的便利,研究工程师的参与尤为重要,他们需要全面掌握终端用户的需求,深入了解技术应用的深度与广度,打通各个环节的流程,有效地将算法模型与产品应用连接起来。然而知易行难,这一过程中的艰辛与技术落地时的成就感也只有亲身...
作者:王婧雯,微软亚洲研究院学术合作经理 倘若在互联网上检索“计算机专业”,与“男孩子读计算机专业有哪些优越性”相对应的,则是“女生能读计算机专业吗”。这体现了一个普遍认知,“计算机”被认为与男性更为相配。 但是,女性真的不适合计算机吗?身边的女性研究员、工程师已经给了我答案,她们都技术扎实、勤勉努力,不断推动整个领域向前进步。与此同时,许多研究也表明,要推动计算机领域的创新与可持续发展,提升性别...
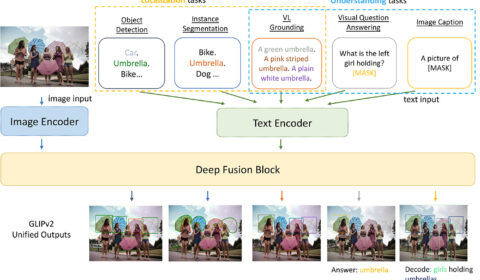
Visual recognition systems are typically trained to predict a fixed set of predetermined object categories in a specific domain, which limits their usability in real-world applications. How to build a model that generalizes to various concepts and domains with minimal…
Awards | PLDI'22
PLDI’22 Distinguished Paper Award
Ryan Beckett (Microsoft), along with coauthors Michael Greenberg (Stevens Institute of Tech) and Eric Campbell (Cornell) received the Distinguished Paper Award at PLDI'22 for their publication Kleene Algebra Modulo Theories: A Framework for Concrete KATs.