
Slide %{start} of %{total}. %{slideTitle}



全新
Surface Laptop,Windows 11 AI PC
这款功能异常强大的超薄笔记本电脑开启了新的 AI 时代,帮助你充分过好每一天。
使用 Microsoft 365 充分利用每一天
只要购买一项计划,即可享受在线保护、安全的云存储空间和多款创新应用,满足你的各种需求。

Xbox Series X
目前为止最疾如闪电、超群出众的 Xbox。

Xbox Series S
目前为止拥有下一代性能的最小 Xbox。

商业版

全新
Surface Laptop 6 商用版
在 13.5 英寸或 15 英寸设计中获得卓越的动力、更好的性能、和 AI 驱动的工具。

Windows 11 AI PC 商用版
借助 Surface Pro 商用版 和 Surface Laptop 商用版 提高生产力、更快地解决问题并开启 AI 新时代。
全新产品
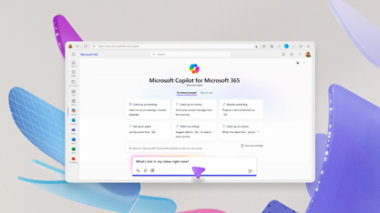
Copilot for Microsoft 365
使用 Microsoft 365 商业版中的 AI 功能,节省时间并专注于最为重要的工作。

面向企业的 Windows 11
专为混合办公而设计。为员工提供强大支持。为 IT 提供一致体验。全面的安全保障。
关注 Microsoft