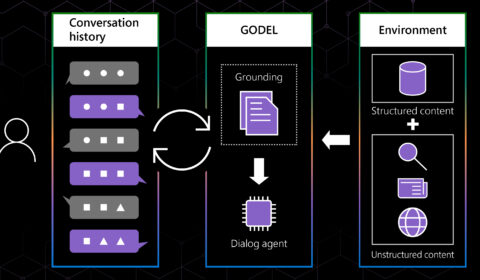
GODEL: Combining goal-oriented dialog with real-world conversations
| Baolin Peng, Michel Galley, Lars Liden, Chris Brockett, Zhou Yu, and Jianfeng Gao
They make restaurant recommendations, help us pay bills, and remind us of appointments. Many people have come to rely on virtual assistants and chatbots to perform a wide range of routine tasks. But what if a single dialog agent, the…
In the news | Analytics India
Interview with the team behind Microsoft’s µTransfer
Recently, researchers – Edward Hu, Greg Yang, Jianfeng Gao from Microsoft, introduced µ-Parametrization, which offers maximal feature learning even in infinite-width limit.
In the news | The Register
Microsoft, OpenAI method could make training large neural networks cheaper
Cost of tuning hyperparameters using μTransfer was 7% of what it would be to pre-train GPT-3. Companies scaling up their neural network models could cut expensive training costs by employing a technique developed by researchers at Microsoft and OpenAI.
In the news | TechRadar
Microsoft, OpenAI may have solved a fundamental AI bottleneck
Microsoft and Open AI have developed a new method for optimizing massive AI models that are too expensive to train multiple times, such as GPT-3. A blog post published by Microsoft Research describes a technique called µ-Parametrization (or µP), which…
µTransfer: A technique for hyperparameter tuning of enormous neural networks
| Edward Hu, Greg Yang, and Jianfeng Gao
Great scientific achievements cannot be made by trial and error alone. Every launch in the space program is underpinned by centuries of fundamental research in aerodynamics, propulsion, and celestial bodies. In the same way, when it comes to building large-scale…
SOLOIST: Pairing transfer learning and machine teaching to advance task bots at scale
| Baolin Peng, Chunyuan Li, Jinchao Li, Lars Liden, and Jianfeng Gao
The increasing use of personal assistants and messaging applications has spurred interest in building task-oriented dialog systems (or task bots) that can communicate with users through natural language to accomplish a wide range of tasks, such as restaurant booking, weather…
HEXA: Self-supervised pretraining with hard examples improves visual representations
| Chunyuan Li, Lei Zhang, and Jianfeng Gao
Humans perceive the world through observing a large number of visual scenes around us and then effectively generalizing—in other words, interpreting and identifying scenes they haven’t encountered before—without heavily relying on labeled annotations for every single scene. One of the…
VinVL: Advancing the state of the art for vision-language models
| Pengchuan Zhang, Lei Zhang, and Jianfeng Gao
Humans understand the world by perceiving and fusing information from multiple channels, such as images viewed by the eyes, voices heard by the ears, and other forms of sensory input. One of the core aspirations in AI is to develop…
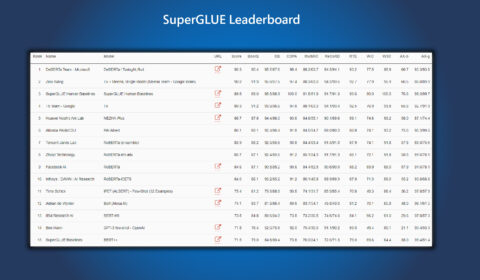
Microsoft DeBERTa surpasses human performance on the SuperGLUE benchmark
| Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen
Natural language understanding (NLU) is one of the longest running goals in AI, and SuperGLUE is currently among the most challenging benchmarks for evaluating NLU models. The benchmark consists of a wide range of NLU tasks, including question answering, natural…