
Natural language understanding (NLU) is one of the longest running goals in AI, and SuperGLUE is currently among the most challenging benchmarks for evaluating NLU models. The benchmark consists of a wide range of NLU tasks, including question answering, natural language inference, co-reference resolution, word sense disambiguation, and others. Take the causal reasoning task (COPA in Figure 1) as an example. Given the premise “the child became immune to the disease” and the question “what’s the cause for this?,” the model is asked to choose an answer from two plausible candidates: 1) “he avoided exposure to the disease” and 2) “he received the vaccine for the disease.” While it is easy for a human to choose the right answer, it is challenging for an AI model. To get the right answer, the model needs to understand the causal relationship between the premise and those plausible options.
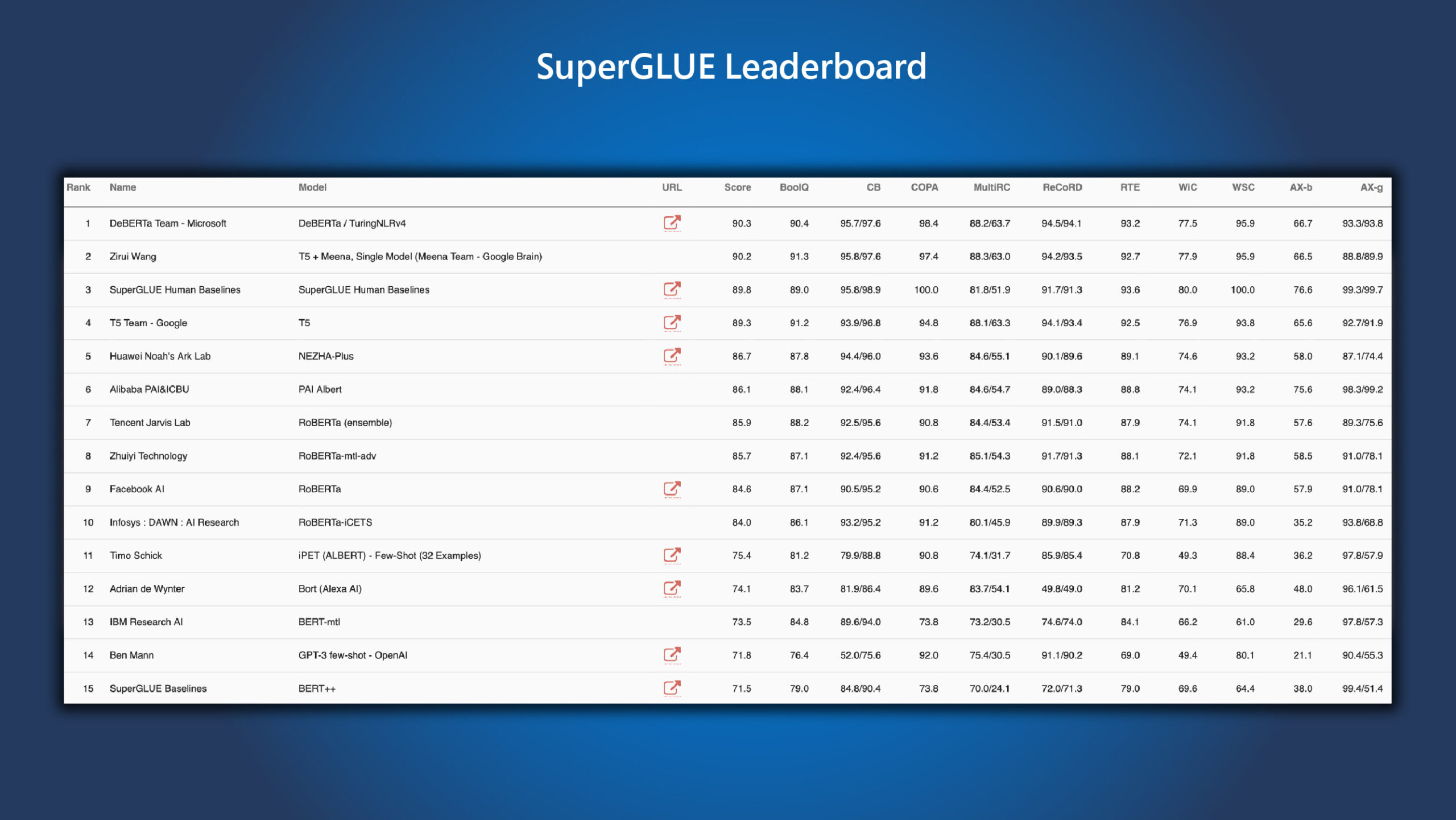
Since its release in 2019, top research teams around the world have been developing large-scale pretrained language models (PLMs) that have driven striking performance improvement on the SuperGLUE benchmark. Microsoft recently updated the DeBERTa model by training a larger version that consists of 48 Transformer layers with 1.5 billion parameters. The significant performance boost makes the single DeBERTa model surpass the human performance on SuperGLUE for the first time in terms of macro-average score (89.9 versus 89.8), and the ensemble DeBERTa model sits atop the SuperGLUE benchmark rankings, outperforming the human baseline by a decent margin (90.3 versus 89.8). The model also sits at the top of the GLUE benchmark rankings with a macro-average score of 90.8.
Microsoft will release the 1.5-billion-parameter DeBERTa model and the source code (opens in new tab) to the public. In addition, DeBERTa is being integrated into the next version of the Microsoft Turing natural language representation model (Turing NLRv4). Our Turing models converge all language innovation across Microsoft, and they are then trained at large scale to support products like Bing, Office, Dynamics, and Azure Cognitive Services, powering a wide range of scenarios involving human-machine and human-human interactions via natural language (such as chatbot, recommendation, question answering, search, personal assist, customer support automation, content generation, and others) to benefit hundreds of millions of users through the Microsoft AI at Scale initiative.
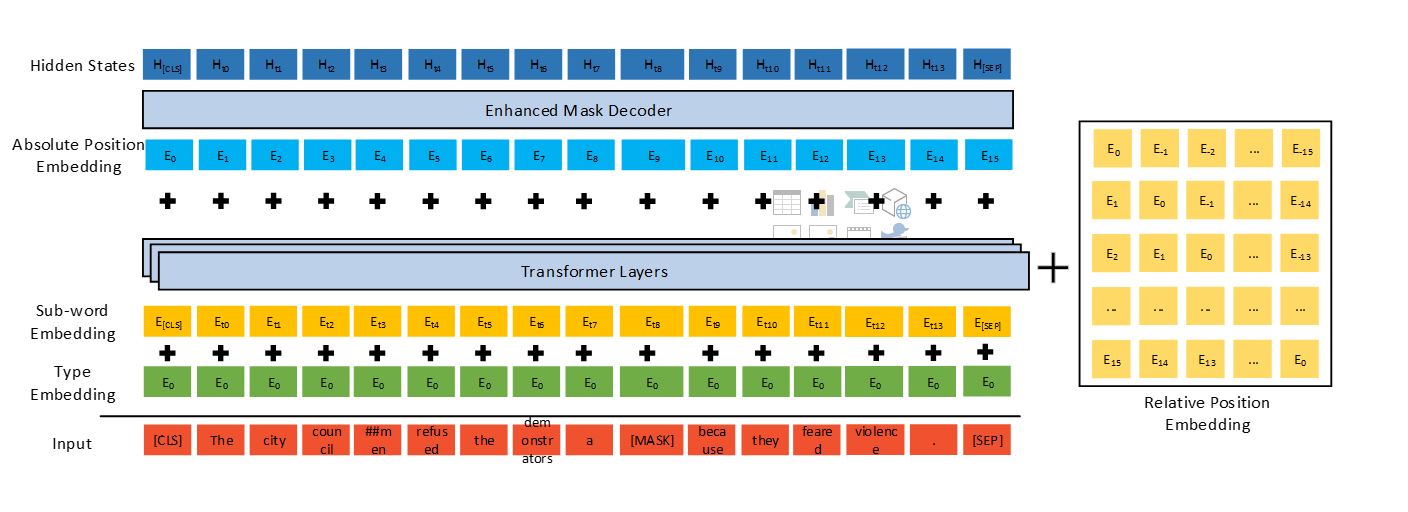
DeBERTa (Decoding-enhanced BERT with disentangled attention) is a Transformer-based neural language model pretrained on large amounts of raw text corpora using self-supervised learning. Like other PLMs, DeBERTa is intended to learn universal language representations that can be adapted to various downstream NLU tasks. DeBERTa improves previous state-of-the-art PLMs (for example, BERT (opens in new tab), RoBERTa (opens in new tab), UniLM) using three novel techniques (illustrated in Figure 2): a disentangled attention mechanism, an enhanced mask decoder, and a virtual adversarial training method for fine-tuning.
Disentangled attention: a two-vector approach to content and position embedding
Unlike BERT, where each word in the input layer is represented using a vector that sums its word (content) embedding and position embedding, each word in DeBERTa is represented using two vectors that encode its content and position, respectively, and the attention weights among words are computed using disentangled matrices based on their contents and relative positions, respectively. This is motivated by the observation that the attention weight (which measures the strength of word-word dependency) of a word pair depends on not only their contents but also their relative positions. For example, the dependency between the words “deep” and “learning” is much stronger when they occur next to each other than when they occur in different sentences.
Enhanced mask decoder accounts for absolute word positions
Like BERT, DeBERTa is pretrained using masked language modeling (MLM). MLM is a fill-in-the-blank task, where a model is taught to use the words surrounding a mask token to predict what the masked word should be. DeBERTa uses the content and position information of the context words for MLM. The disentangled attention mechanism already considers the contents and relative positions of the context words, but not the absolute positions of these words, which in many cases are crucial for the prediction.
Consider the sentence “a new store opened beside the new mall” with the italicized words “store” and “mall” masked for prediction. Although the local contexts of the two words are similar, they play different syntactic roles in the sentence. (Here, the subject of the sentence is “store” not “mall,” for example.) These syntactical nuances depend, to a large degree, upon the words’ absolute positions in the sentence, and so it is important to account for a word’s absolute position in the language modeling process. DeBERTa incorporates absolute word position embeddings right before the softmax layer where the model decodes the masked words based on the aggregated contextual embeddings of word contents and positions.

Azure AI Foundry Labs
Get a glimpse of potential future directions for AI, with these experimental technologies from Microsoft Research.
Scale Invariant Fine-Tuning improves training stability
Virtual adversarial training is a regularization method for improving models’ generalization. It does so by improving a model’s robustness to adversarial examples, which are created by making small perturbations to the input. The model is regularized so that when given a task-specific example, the model produces the same output distribution as it produces on an adversarial perturbation of that example. For NLU tasks, the perturbation is applied to the word embedding instead of the original word sequence. However, the value ranges (norms) of the embedding vectors vary among different words and models. The variance gets larger for bigger models with billions of parameters, leading to some instability of adversarial training. Inspired by layer normalization, to improve the training stability, we developed a Scale-Invariant-Fine-Tuning (SiFT) method where the perturbations are applied to the normalized word embeddings.
Conclusion and looking forward
As shown in the SuperGLUE leaderboard (Figure 1), DeBERTa sets new state of the art on a wide range of NLU tasks by combining the three techniques detailed above. Compared to Google’s T5 model, which consists of 11 billion parameters, the 1.5-billion-parameter DeBERTa is much more energy efficient to train and maintain, and it is easier to compress and deploy to apps of various settings.
DeBERTa surpassing human performance on SuperGLUE marks an important milestone toward general AI. Despite its promising results on SuperGLUE, the model is by no means reaching the human-level intelligence of NLU. Humans are extremely good at leveraging the knowledge learned from different tasks to solve a new task with no or little task-specific demonstration. This is referred to as compositional generalization, the ability to generalize to novel compositions (new tasks) of familiar constituents (subtasks or basic problem-solving skills). Moving forward, it is worth exploring how to make DeBERTa incorporate compositional structures in a more explicit manner, which could allow combining neural and symbolic computation of natural language similar to what humans do.
Acknowledgments
This research was conducted by Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. We thank our collaborators from Bing, Dynamics 365 AI, and Microsoft Research for providing compute resources for large-scale modeling and insightful discussions.