

TechWiese Blog
Der Status Quo des Chaos Engineerings
12. März 2021

Josef Fuchshuber
Dieser Blogbeitrag ist ein Repost und stammt im Original aus dem Know-how-Bereich von TechWiese, dessen Artikel in diesem Blog aufgegangen sind.
Dieser Artikel zeigt den aktuellen Stand der Chaos-Engineering Ritualen, Prozessen und Werkzeuge für das Cloud-Native-Ökosystem. Das Wichtigste vorweg. Chaos Engineering bedeutet nicht, Chaos zu erzeugen, sondern Chaos im IT-Betrieb zu vermeiden. Der zweite Teil des Artikels demonstriert die Verwendung und Funktionsweise des quelloffenen Chaos Engineering Werkzeuges Chaos Toolkit anhand zwei Beispielen.
Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production. [^1]
Wobei hilft uns Chaos Engineering?
Cloud Native hat viele Vorteile. Allerdings gibt es immer einen negativen Punkt: Die Ausführungskomplexität der Plattformen und unserer Microservices steigt. Unsere Architekturen setzen sich in der Laufzeitsicht aus vielen Bausteinen und Ebenen zusammen. Mit Chaos Engineering (Mindset & Prozess) und Chaos Testing (Tooling) können wir diese Herausforderung in den Griff bekommen, resilientere Anwendungen bauen und Vertrauen in unsere komplexen Anwendungen aufbauen.
Der Faktor Mensch ist beim Chaos Engineering fast noch zentraler als unsere Anwendungen. Wie oben beschrieben, ist es sehr wichtig, dass wir das Verhalten unserer Cloud-nativen Architekturen kennen und damit Vertrauen aufbauen. Der zweite Aspekt sind unsere Ops Prozesse. Funktioniert unser Monitoring und Alerting? Haben alle On-Call Kollegen das Know How, um Probleme schnell zu analysieren und zu beheben?
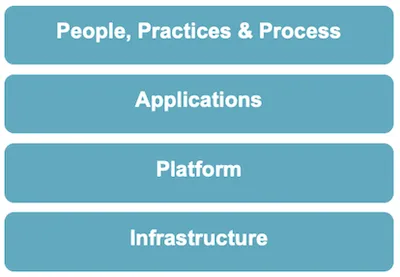
Beim Chaos Engineering kann das Was wird getestet in vier Kategorien eingeteilt werden:
- Infrastructure: Hierbei geht es um unsere virtuelle Infrastruktur bei unseren Cloud Providern. Wir können testen, ob unser Infrastructure-as-Code Tooling alles korrekt angelegt hat und ob z.B. die High-Availability VPN Verbindung ins eigene Datacenter wirklich hochverfügbar und ausfallsicher ist.
- Platform: In der nächsten Ebene kommen unsere Plattformkomponenten ins Spiel - Kubernetes, DevOps Deployment Tooling, Observability Tooling. Beispiele für Fragen, die Test auf dieser Ebene beantworten können sind: Funktioniert die Selbstheilung ein Node-Pools falls ein Node ausfällt? Was passiert, wenn die zentrale Container Registry ausfällt und im Cluster neue Pods gestartet werden müssen?
- Application: Auf diesem Level wird das Verhalten unserer Anwendungen im Zusammenspiel der Microservices untereinander und mit den Plattformkomponenten getestet: Stimmt das Exception Handling? Sind alle Circuit Breaker und Connection Pools mit ihren Timeouts und Retries korrekt konfiguriert? Wir ein (Teil-)Ausfall eines Service an den Healthchecks korrekt und schnell genug erkannt?
- People, Practices & Process: In diesem Level geht es weniger um Tooling, sondern um die Menschen im Team. Stimmen in einem Notfall die Kommunikationswege und werden die richtigen Menschen zur richtigen Zeit informiert? Haben die Kollegen alle relevanten Permissions um Analysen und Fehlerbehebungen durchführen zu können? Haben sie das Know-How um die MTTR[^2] nicht zu gefährden.
Fasst man die Ebenen und ihre Fragestellungen zusammen, so kann man als Team bei diesen Aufgaben mit Chaos Engineering starten:
- Battle Test für neue Infrastruktur und Services
- Quality Review: Kontinuierlich die Robustheit von Anwendungen verbessern
- Post Mortem: Reproduktion von Ausfällen
- On-Call Training
Der leichtgewichtigste Start von Chaos Engineering sind Game Days. Am Game Day führt das komplette Team (Dev, Ops, QA, Product Owner, …) Experimente aus. Dabei steht das Tooling zuerst im Hintergrund. In erster Linie geht es darum, dass das gesamte Team das Chaos Engineering Mindeset verinnerlicht und dabei Anomalien entdeckt und behoben werden.
Wie kann man starten?
Chaos Engineering without observability … is just chaos[^3]
Jeder kennt wahrscheinlich das "This Is Fine" Meme und niemand will so ignorant sein, wie unser kleiner Freund aus dem Comic. Man kann Dinge bewusst ignorieren oder man kann sie erst gar nicht ignorieren, weil man sie nicht sieht. Genau das passiert, wenn wir kein ausreichendes Monitoring für unseren Anwendungs- und Plattformkomponenten haben. Aus End-To-End Sicht bietet die RED Methode[^4] zum Beispiel eine gute Sicht auf den Zustand einer Microservice Architektur. Kümmert euch also zuerst um euer Monitoring.
Die häufigste Frage am Anfang ist: In welcher Umgebung führe ich meine ersten Tests auf? Am Anfang sollte man immer in der Umgebung arbeiten, die der Produktion am nächsten ist (keine Mocks, möglichst identische Cloud Infrastruktur), aber nicht die Produktion. Aber: Chaos Engineering Experimente in Produktion sollen das Ziel sein, denn nur dort findet ihr die Realität. Wenn ihr in einer Testumgebung startet, muss euch bewusst sein, dass ihr während der Experimente keine echte Kundenlast habt. Ihr braucht Lastgeneratoren oder Akzeptanztests, über die ihr prüfen könnt, ob euer System so reagiert wie ihr glaubt. Falls es diese noch nicht gibt, müsst ihr diese vor dem ersten Experiment bauen. Keine Angst, manchmal reicht auch schon ein kleines Shell-Skript oder euer Chaos Testing Tooling bringt bereits eine Möglichkeit zur Validierung der Experimentergebnisse gleich mit.
Nachdem wir jetzt eine Umgebung und Monitoring haben, können wir mit den ersten Experimenten starten. Dabei hilft uns dieses Bild:
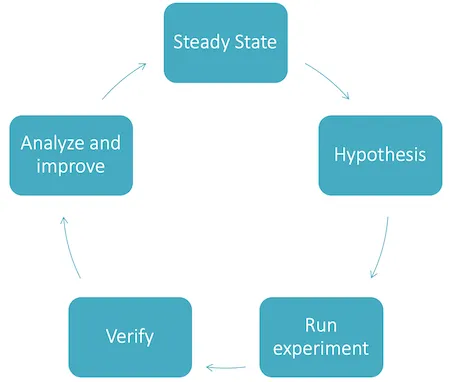
Die Phasen des Chaos Engineerings können als zyklischen Prozess dargestellt werden. Ein Zyklus startet und endet im Steady State.
- Steady State: Der wichtigste Status des Chaos-Engineerings. Denn dieser beschreibt das Verhalten des Systems unter normalen Bedingungen.
- Hypothesis: In dieser Phase stellen wir eine Hypothese auf. Wir designen also unser Experiment indem wir eine Action ausführen (z.B. den Ausfall einer Datenbank) und das erwartete Ergebnis beschreiben (z.B. Fehlerseite in der Web-UI wird angezeigt, HTTP-Status 200 und nicht 500).
- Run Experiment: Wir führen die definierte Aktion aus. In einem Game Day kann man dies manuell (z.B. CLI Tooling der Cloudprovider,
kubectl) oder automatisiert über ein geeignetes Chaos Test Tooling. - Verify: In dieser Phase validieren wir, ob das erwartete Ergebnis eingetreten ist. Dazu gehört das Verhalten der Anwendung, aber auch das gemessene Verhalten in unseren Monitoring- und Alarmierungstools.
- Analyze and Improve: Falls das erwartete Ergebnis nicht eingetreten ist, analysieren wir die Ursache und beheben diese.
Nach einem erfolgreichen Test muss das System wieder im Steady State sein. Das ist entweder der Fall, wenn die ausgeführte Aktion den Steady State nicht ändert (z.B. Das Cluster erkennt eine Anomalie automatisch und kann sich selbst heilen) oder ein Rollback durchgeführt wird (z.B. Datenbank wird wieder hochgefahren).
Beim Design und Ausführung des Experiments ist eines der wichtigsten Dinge immer den potenziellen Blast Radius, also die Auswirkung des Fehlers, so minimal wie möglich zu halten und ständig zu beobachten. Dabei ist hilfreich, dass man sich im Vorfeld überlegt, wie das Experiment im Notfall abgebrochen werden kann und wie der Steady State möglichst schnell wieder hergestellt werden kann. Anwendungen, die ein Canary Deployment unterstützten, sind hierbei klar im Vorteil. Denn hierbei kann der User-Strom detailliert auf das Experiment oder die normale Version der Anwendung gelenkt werden.
Jedes Chaos Engineering Experiment erfordert eine detaillierte Planung und muss in irgendeiner Form dokumentiert werden. Beispiel:
| Target | Billing Service |
| Experiment | Schnittstelle zu Paypal steht nicht zur Verfügung |
| Hypothesis | Die Anwendung erkennt den Ausfall automatisch und bietet unseren Kunden die Bezahlart nicht mehr an. Die Kunden können nur noch per Kreditkarte oder Vorkasse bezahlen. Das Monitoring erkennt den Ausfall und erstellt automatisch einen Prio-1 Incident. |
| Steady State | Alle Arten der Bezahlung stehen für die Kunden zur Verfügung |
| Blast Radius | Während dem Experiment steht den Kunden die Bezahlung per Paypal nicht zur Verfügung. Die alternativen Bezahlungswege sind davon nicht beeinträchtigt. |
| Technical information | Wir simulieren den Ausfall der Paypal-API, indem wir den ausgehenden Netzwerkverkehr des Billing Services extrem verlangsamen. Dies können wir über das Service Mesh (Sidecar-Proxies) realisieren. |
Tipp zum Design von Experimenten und Hypothesen: Stellt keine Hypothese auf, von der ihr im Vorfeld schon wisst, dass sie eure Anwendung kaputt macht und somit nicht haltbar ist! Diese Probleme, falls sie wichtig sind, könnt ihr gleich in Angriff nehmen und beheben. Stellt nur Hypothesen über eure Anwendungen auf, von denen ihr glaubt, dass sie belastbar sind. Denn das ist der Sinn eines Experiments.
Chaos Engineering Tooling
Im Tooling für Chaos Tests ist im Moment viel Bewegung. Es kommen ständig neue OpenSource und kommerzielle Produkte hinzu. Eine aktuelle Übersicht über den Markt bietet uns die Cloud Native Landscape der CNCF. Hier gibt es inzwischen eine eigene Chaos Engineering Kategorie[^5].

Die Eigenschaften der Chaos Engineering Tools sind vielfältig:
- API oder Operator basierend: Verwendet das Tool nur die öffentlichen APIs von Cloud Providern oder Kubernetes oder müssen im Cluster invasive Agents / Operatoren installiert werden (z.B. als Sidecars).
- Support des Chaos Engineering Levels: Nicht alle Tools unterstützen alle Levels. Die Hyperscaler Clouds und Kubernetes wird von vielen Tools unterstützt. Cloud Provider oder Plattformen mit weniger Marktdurchdringung sind oft Second-Class-Citizen.
- Zufallsbasiert oder experimentbasiert: Bei Tools die nach dem Zufallsprinzip agieren, lässt sich der Blast Radius viel schwerer abschätzen und auch die vergleichbare Wiederholung in CI/CD-Pipelines ist schwierig. Dafür bringen diese Tools eventuell unbekannte Fehlerquellen zu Tage.
Es gibt momentan leider keinen “One-Stop-Shop”, der alle Teams glücklich macht. Jedes Team muss sich also Gedanken über die eigenen Anforderungen machen und ein oder mehrere Werkzeuge aussuchen.
Chaos Toolkit Demo
Der zweite Teil des Artikels stellt Chaos Toolkit (CTK) als Vertreter eines Chaos Engineering Werkzeuges vor. Mit CTK können Chaos Engineering Experimente mit einer eigenen DSL als JSON- oder YAML-Beschreibung beschrieben werden. CTK ist Open Source (Apache-2.0), in Python implementiert und kann durch Treiber erweitert werden. Einige Treiber werden vom Projekt out-of-the-box bereitgestellt:
- Infrastruktur- und Plattformebene: AWS, Azure, Cloud Foundry, Gandi, Google Cloud Platform, Kubernetes, Service Fabric
- Anwendungsebene: Spring Boot
- Netzwerk: Istio, ToxiProxy, WireMock
- Observability: Dynatrace, Humio, Open Tracing, Prometheus
Zu den Treibern gehören Actions und Probes. Probes werden verwendet, um den Steady State zu validieren, also den Zustand vor und nach den Actions. Die Actions sind der Kern des Experiments. Sie simulieren Ausfälle der Anwendung oder Plattform oder führen eine Verlangsamung des Netzwerkverkehrs durch. CKT führt die Aktionen und Probes immer über die öffentlichen APIs der Plattformen und Anwendungen aus. Das Experiment läuft außerhalb des Clusters und fügt dem Cluster keine zusätzlichen invasive Komponenten (z.B. Service Meshes) hinzu.

Die beste Eigenschaft von CTK ist, dass man nicht nur Experimente durchführen kann, sondern auch den Steady State als Teil der Testfälle definieren muss. Damit bilden CTK-Tests eine geschlossene Einheit und sind ideal für die Automatisierung in den ständig aktiven CI/CD-Prozessen.
Demo App
Unsere beiden Beispiele werde anhand einer Demo-Anwendung demonstriert. Einer App zur Kontaktverwaltung, die auf einer Microservice Architektur und Kubernetes Runtime basiert. Die Demo-App stammt aus dem Azure Developer College.
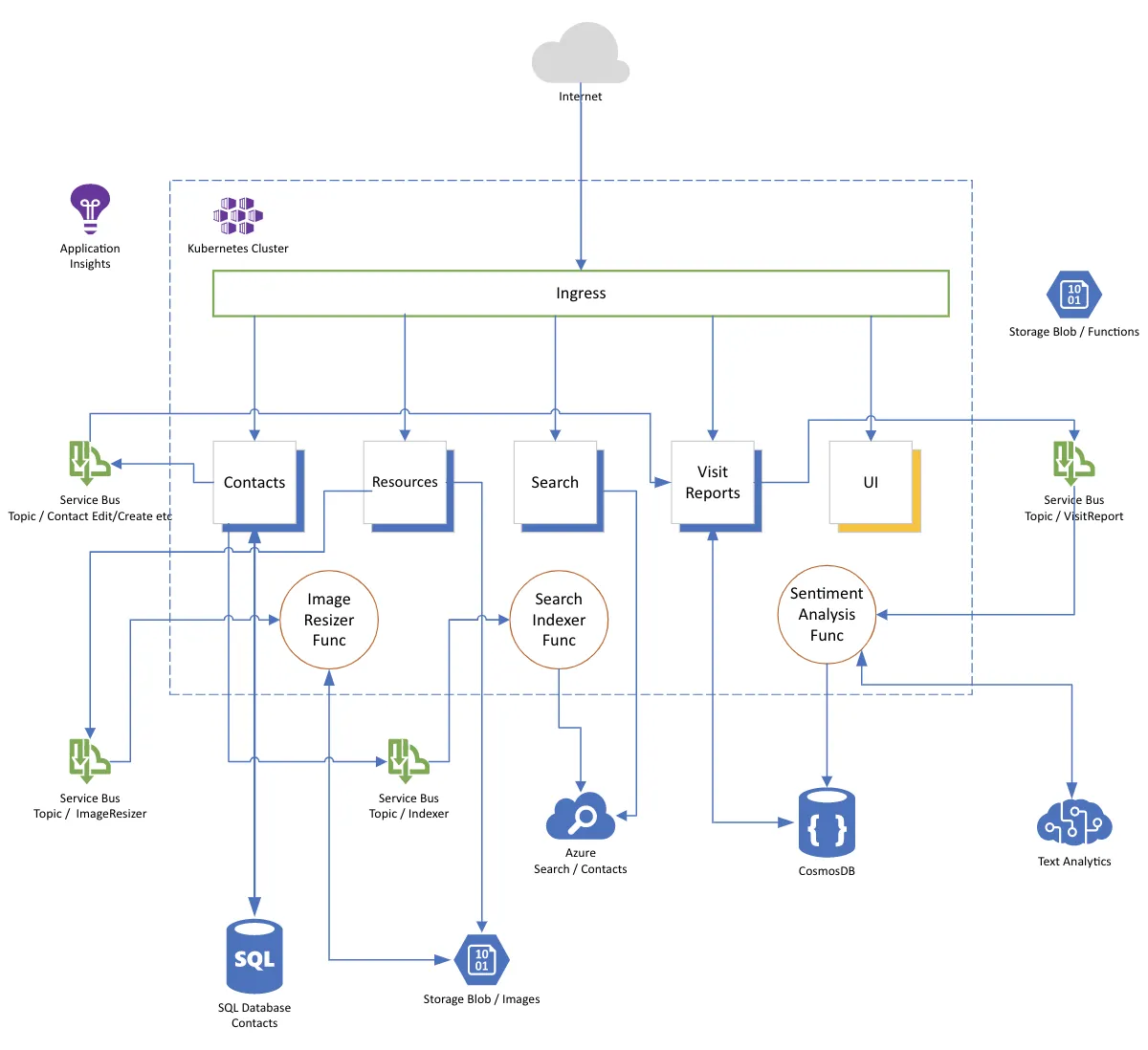
Beispiel #1
Das erste Beispiel ist das Kubernetes "Hallo-Welt" des Chaos Testings. Was passiert, wenn der Pod des Kontaktdienst ausfällt?
Um mit Kubernetes zu interagieren, hat CTK eine eigene Erweiterung [^8]. Das Tool und die Erweiterung können einfach in einer bestehenden Python-Umgebung installiert werden (Installationsdetails).
pip install -U chaostoolkit
pip install chaostoolkit-kubernetesNach der Installation des Tools, können wir unseren ersten "Hallo Welt"-Test schreiben. Für die deklarative Beschreibung können wir zwischen JSON und YAML wählen. JSON sollte allein schon wegen der fehlenden Möglichkeit von Kommentaren vermieden werden.
Der erste Teil des Tests beschreibt den Steady State. Der CTK unterstützt drei verschiedene Probe-Provider in der Basisinstallation: HTTP, Process und Python[^6]. Unser erstes Beispiel verwendet den HTTP-Provider und sendet eine HTTP-Anfrage an den Search-Service und validiert dessen HTTP Response Code.
# define the steady state hypothesis
steady-state-hypothesis:
title: Verifying search api remains healthy
probes:
- type: probe
name: search-api-must-still-respond
tolerance: 200# http response code 200 is expected
provider:
type: http
timeout: 2
url: http://${azure_app_endpoint}/api/search/contacts?phrase=mustermannDer zweite Teil des Tests beschreibt die Action unseres Experiments. Unser Beispiel verwendet dabei den Kubernetes Treiber und terminiert genau einen Pod aus dem "contactsapp"-Namespace der Gruppe der Pods mit dem Label service=searchapi. Der Treiber verwendet Ihren aktuellen kubectl-Kontext (~/.kube/config).
method:
- type: action
name: terminate-pod
provider:
type: python
module: chaosk8s.pod.actions
func: terminate_pods
# Terminates one "searchapi" pod randomly
arguments:
label_selector: service=searchapi
ns: contactsapp
qty: 1
rand: true
grace_period: 0Sobald Kubernetes feststellt, dass ein Pod im Replikat-Set fehlt, wird automatisch ein neuer Pod gestartet. Dies geschieht nicht sofort, sondern dauert einige Sekunden, abhängig von der Kubernetes-Konfiguration und der Anwendung im Pod. Unser Beispiel hat zu Beginn ein Replikat-Set der Größe 1, so dass es beim Terminieren des Pods zu einem kurzen Serviceausfall kommt. Dadurch schlägt die Validierung des Steady State und damit der komplette Chaos Test fehl. Nach dem Erhöhen der Replikas auf zwei Instanzen des Search-Services kann der Test erfolgreich ausgeführt werden. Die folgende Aufzeichnung zeigt das Scheitern der ersten Ausführung, die Behebung durch Reskalierung und anschließend die erfolgreiche Wiederholung des Tests. Erste Zeilen von der Aufnahme der Terminal Session - Chaos Toolkit: Kill Search Pod
CTK führt jedes Experiment nach diesem Schema aus:
- Validate experiment description
- Run Steady State Hypothesis
- Run Method
- Run Steady State Hypothesis
- Run Rollbacks
Wenn einer der Schritte fehlschlägt, wird das Experiment als fehlgeschlagen klassifiziert.
Die Ergebnisse des Experiments werden direkt im Terminal ausgegeben und werden zusätzlich mit weiteren Informationen in der Ausgabedatei journal.json protokolliert. Mit dieser Datei können HTML- oder PDF-Berichte des Experiments erzeugt werden.
chaos report --export-format=html journal.json report.htmlDer komplette Quellcode von diesem Experiment ist auf Github zu finden.
Beispiel #2
Das zweite Beispiel verwendet den Azure Treiber[^9] von CTK. In diesem Beispiel wird ein Knoten aus dem Kubernetes Nodepool, der von Azure AKS[^7] verwaltet wird, vorübergehend heruntergefahren und somit ein Ausfall einer virtuellen Maschine simuliert.
pip install -U chaostoolkit-azureBevor die Erweiterung verwendet werden kann, müssen die Azure Secrets bereitgestellt werden. Dazu sind die Azure CLI und die Permission zur Erstellung von Service-Principals erforderlich (Dokumentation).
az login
az ad sp create-for-rbac --sdk-auth > credentials.jsoncredentials.json:
{
"subscriptionId": "<azure_aubscription_id>",
"tenantId": "<tenant_id>",
"clientId": "<application_id>",
"clientSecret": "<application_secret>",
"activeDirectoryEndpointUrl": "https://login.microsoftonline.com",
"resourceManagerEndpointUrl": "https://management.azure.com/",
"activeDirectoryGraphResourceId": "https://graph.windows.net/",
"sqlManagementEndpointUrl": "https://management.core.windows.net:8443/",
"galleryEndpointUrl": "https://gallery.azure.com/",
"managementEndpointUrl": "https://management.core.windows.net/"
}Der Pfad zu dieser Datei muss in einer Umgebungsvariablen namens AZURE_AUTH_LOCATION gespeichert werden. Wenn dies erledigt ist, kann man mit dem Experiment beginnen. Unser Experiment filtert eine Instanz aus einem Virtual Machine Scale Set (vmss) heraus und stoppt sie. Die Filterung erfolgt über die Ressourcengruppe, den VMSS Namen und der Instanz-ID.
method:
- type: action
name: stop-instace
provider:
type: python
module: chaosazure.vmss.actions
func: stop_vmss
arguments:
filter: where resourceGroup=~'${azure_resource_group}' and name=~'${azure_vmss_name}'
instance_criteria:
- name: ${azure_vmss_instanceId}
pauses:
after: 15Mit diesem Test kann überprüft werden, ob die beiden Instanzen des Search Services auf mehr als einem Kubernetes Node ausgeführt werden, wodurch die Verfügbarkeit des Services auch bei einem Node-Ausfall sichergestellt ist.
Da in diesem Test der Node auch nach der zweiten Steady-State Validierung gestoppt bleibt, muss ein Rollback durchgeführt werden. In unserem Beispiel starten wir den Knoten mit der Funktion restart_vmss neu.
rollbacks:
- type: action
name: restart-instance
provider:
type: python
module: chaosazure.vmss.actions
func: restart_vmss
arguments:
filter: where resourceGroup=~'${azure_resource_group}' and name=~'${azure_vmss_name}'
instance_criteria:
- name: ${azure_vmss_instanceId}Summary
Chaos Engineering ist keine Jobbeschreibung, sondern eine Mindset und Vorgehen, das das komplette Team betrifft. Das wichtigste am Chaos Engineering ist, dass man es macht:
- Regelmäßige Game Days im gesamten Team sollten zum festen Ritual werden.
- Startet in einer produktionsnahen Umgebung und prüft zuerst, ob euer Monitoring ausreichend ist.
Werkzeuge kommen und gehen:
- Die Chaos Engineering Werkzeuge im Cloud Native Ökosystem entwickeln sich weiter.
- Der Kontext eurer Chaos Engineering Experimente wird sich erweitern.
Chaos Toolkit ist ein stabiles Open-Source Werkzeug für das Chaos Testing. Durch die vorhandenen Treibererweiterungen und die Möglichkeit für eigene Erweiterungen, sowie die Möglichkeit eigene Prozesse direkt als Action oder Probe ausführen zu können, ergibt eine große Flexibilität für jegliche Art von Chaostests. Da ein Test immer das komplette Experiment (Steady State & Action) beinhaltet, ist Chaos Toolkit ideal für die automatisierte kontinuierliche Qualitätssicherung.
Hinweis: Dieser Post ist ursprünglich auf Englisch auf dem QAware Software Engineering Blog erschienen.
- [^1]Principles of Chaos Engineering
- [^2]Mean time to recovery(MTTR)
- [^3]Charity Majors, @mipsytipsy CTO @ Honeycomb
- [^4]The RED Method: key metrics for microservices architecture
- [^5]Chaos Engineering Category in CNCF Cloud Native Landscape
- [^6]Chaos Toolkit Probe Provider
- [^7]Azure Kubernetes Service (AKS)
- [^8]chaosk8s Extension
- [^9]Azure Extension