

编者按:在人工智能领域,尤其是“文本-视频”(Text-to-Video, T2V)模型的研究中,如何高效生成具有丰富动态和时间一致性的长视频一直是一个挑战。尽管 Transformer 架构和扩散模型在视频生成方面取得了显著进展,但在高分辨率视频的训练成本、基于文本条件的去噪过程的复杂性、长视频生成中的一致性问题等方面仍存在重大挑战。对此,微软亚洲研究院提出了 ARLON 框架,旨在通过结合自回归(AR)模型和扩散变换器(DiT),实现利用文本提示,合成高质量、个性化的长视频。
近年来人工智能技术的飞速发展,不断推动着“文本-视频”生成(Text-to-Video,T2V)技术的边界。T2V 技术的持续优化与创新,为人们提供了丰富、便捷的视频内容创作体验。相关的研究成果在娱乐、教育以及多媒体交流等多个领域都有着广泛的应用前景。
传统的 T2V 系统受限于数据和计算资源的缺乏,难以高效生成具有丰富动态和时间一致性的长视频。在长视频生成任务中,保持视频内容的连贯性和动态性,同时提高生成效率,成为了该领域亟待解决的问题。
对此,微软亚洲研究院的研究员们尝试将自回归(AR)模型与扩散模型(DiT)技术相结合,构建了 ARLON 框架。通过潜在向量量化变分自编码器(VQ-VAE)技术,ARLON 能够将 T2V 任务中的高维输入特征有效地压缩、量化,从而在保持信息密度的同时,降低模型的学习复杂性。只需文本提示,ARLON 即可合成具有丰富动态和时间连贯性的高质量视频。
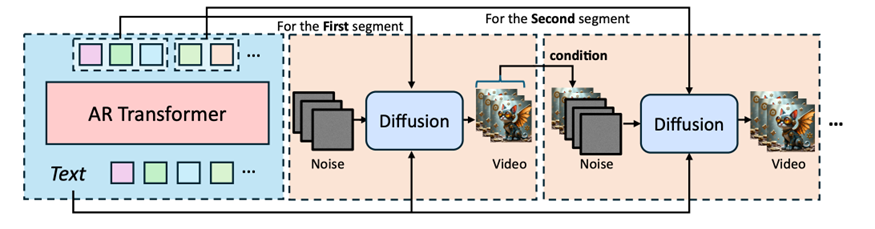
随后,研究员们又进一步优化了 ARLON 框架,通过引入适应性语义注入模块和不确定性采样策略,显著提升了模型对噪声的鲁棒性,并提高了视频生成的效率。其中,适应性语义注入模块利用门控自适应归一化机制,将粗略的语义信息有效地注入到视频生成过程中。而不确定性采样策略则模拟了 AR 预测中的方差,通过从原始粗略潜在特征的分布中采样噪声,增强模型对不同输入条件的适应能力。
ARLON 在视频的稳健性、自然度和动态一致性方面显著超过了以往的视频生成模型。即便是面对复杂度较高或场景重复性强等极具挑战性的内容,ARLON 也能一致地合成高质量视频。在 VBench 视频生成基准测试中,ARLON 超越了现有的基线模型,并在多个评估指标上取得了突破性进展。ARLON 框架的成功不仅展示了结合不同模型优势解决复杂问题的巨大潜力,而且为未来长视频生成技术的发展提供了新的方向。
ARLON 论文:https://arxiv.org/abs/2410.20502 (opens in new tab)
ARLON 项目页面:http://aka.ms/arlon (opens in new tab)
ARLON:提升长视频生成效率与质量的新框架
ARLON 框架由三个主要组件组成:潜在 VQ-VAE 压缩、自回归建模和语义感知条件生成。给定一个文本提示,自回归模型会预测粗略的视觉潜在标记,这些标记是由 3D VAE 编码器和基于目标视频的潜在 VQ-VAE 编码器构建的。预测的视觉潜在标记包含了粗略的空间信息和一致的语义信息。基于这些标记,潜在 VQ-VAE 解码器会生成连续的潜在特征,并作为语义条件通过语义注入模块,引入 DiT 模型。
ARLON 框架的三个组件:
潜在 VQ-VAE 压缩(Latent VQ-VAE Compression)是 ARLON 框架中的关键步骤,用于将高维输入特征映射到紧凑且离散的潜在空间。这一过程通过以下数学表达式实现:
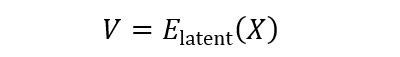
其中,X∈R^(T×H×W×C) 表示输入特征,E_”latent” 是由 3D 卷积神经网络块和残差注意力块组成的编码器,V∈R^(T/r×H/o×W/o×h) 是编码后的潜在嵌入。每个嵌入向量 v∈R^h 会被量化到最近的码本 C∈R^(K×m) 中的条目 c∈R^m,形成离散的潜在嵌入 (Q):
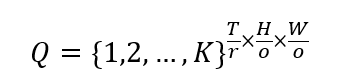
解码过程则是给定视频标记的索引,利用码本 (C) 检索相应的条目 (c),然后使用潜在 VQ-VAE 解码器重建视频嵌入 (F):
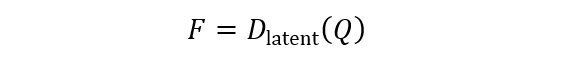
自回归建模(Autoregressive Modeling)利用因果 Transformer 解码器作为语言模型,将文本条件 (Y) 和视觉标记的索引 (Q) 结合成为模型的输入,以自回归的方式生成视频内容。这一过程可以用以下概率模型描述:
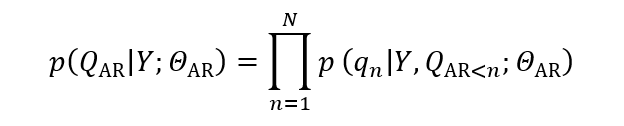
其中,Q_”AR”=[q_1,q_2,…,q_N] 是视觉标记索引的序列,N 是序列长度,Θ_”AR” 表示模型参数。模型的目标是最大化给定文本条件 (Y) 下的视觉标记索引序列 Q_”AR” 的概率。
在语义感知条件生成(Semantic-aware Condition Generation)阶段,ARLON 框架利用视频 VAE 和潜在 VQ-VAE 将视频压缩到粗略的潜在空间中,并将 AR 模型预测的标记作为训练扩散模型的语义条件。这一过程可以用以下公式表示:
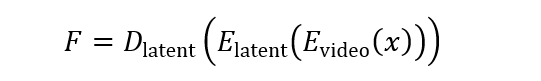
其中, x 是输入视频,E_”video” 是视频编码器,E_”latent” 是潜在 VQ-VAE 编码器,D_”latent” 是潜在 VQ-VAE 解码器, F 是重建的潜在特征,用作语义条件。
语义注入是将粗略的语义信息注入到视频生成过程中,以引导扩散过程。这一过程涉及以下步骤:
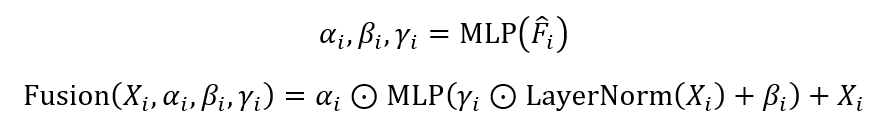
其中,X_i 是输入潜在变量,F ̂_i 是经过不确定性采样处理的条件潜在变量,α_i,β_i,γ_i 是通过 MLP 网络生成的比例、偏移和门控参数,”Fusion” 函数将条件信息注入到原始潜在变量中。
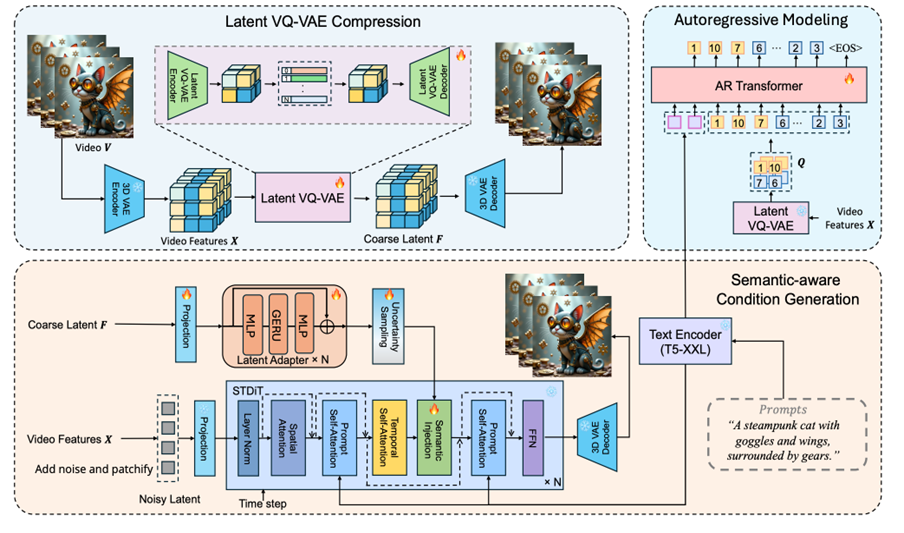
为了减轻 AR 推理过程中不可避免引入的噪声,研究员们在训练阶段采用了两种策略来提高模型对噪声的鲁棒性:
粗略视觉潜在标记:使用两种不同压缩比的潜在 VQ-VAE 来增强扩散过程对噪声AR预测结果的容忍度。
不确定性采样:为了模拟 AR 预测的方差,引入不确定性采样模块。该机制从原始粗略潜在特征 (F_i) 的分布中生成噪声,而不是严格依赖于原始的粗略潜在特征:
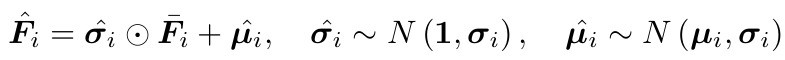
其中,μ_i 和 σ_i 分别是噪声的均值和标准差,F‾_i=(F_i-μ_i)/σ_i 是标准化的特征,σ ̂_i 和 μ ̂_i 是从目标特征均值和方差分布中采样的噪声向量。
实验结果
实验结果表明 ARLON 模型在长视频生成领域达到了目前最先进的性能,并且在推理效率和生成质量上都有显著的提升。
研究员们对 ARLON 模型与其他开源的文本到长视频生成模型,在动态度、审美质量、成像质量、主题一致性、背景一致性和运动平滑度等指标上进行了评估。结果显示,ARLON 在多个评估指标上表现优异,特别是在动态度和审美质量方面的性能表现尤为突出。
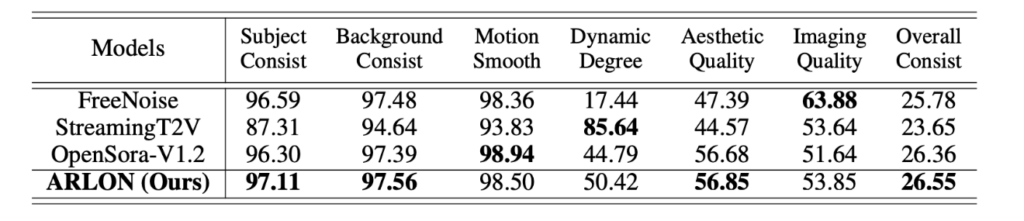
定性结果展示了 ARLON 生成的视频在保持动态和一致性方面的优势。例如,与生成静态或几乎无运动视频的模型相比,ARLON 在动态运动、高水平的时间一致性及自然流畅性之间取得了更好的平衡,生成的视频不仅展现了动态运动,还保持了高度的主体一致性和自然流畅性。



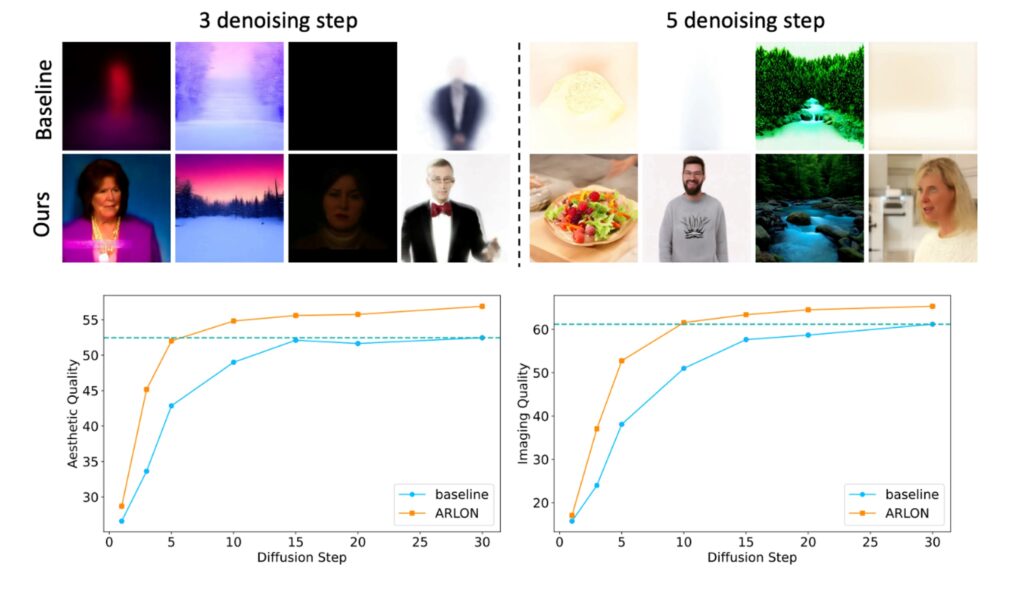
ARLON 通过使用 AR 预测的潜在特征作为有效的初始化,显著加快了 DiT 模型的去噪过程。与需要30步去噪的基线模型相比,ARLON 在5到10步内就达到了相似的性能。
ARLON 还能处理使用渐进式文本提示的长视频生成,这意味着模型能够根据一系列逐步变化的文本提示生成视频,并且在提示转换时能够保持视频内容的连贯性。


注:ARLON 是一个纯粹的研究项目。ARLON 可以合成保持场景动态的长视频,但其相似度和自然度仍取决于视频提示的长度、质量、背景以及其他因素。该模型可能在误用方面存在潜在风险,例如伪造视频内容或冒充特定场景。在视频生成研究中,如果该模型需要推广到现实世界中未见过的场景,应确保与场景相关方达成其同意使用视频内容的协议,同时配备合成视频检测模型。如果您发现 ARLON 被滥用、非法使用或侵犯了您或他人的权利,可以在微软的滥用报告门户网站(https://msrc.microsoft.com/report/)进行举报。
随着人工智能技术的快速发展,确保相关技术能被人们信赖是一个亟需解决的问题。微软主动采取了一系列措施来预判和降低人工智能技术所带来的风险。微软致力于依照以人为本的伦理原则推动人工智能的发展,早在2018年就发布了“公平、包容、可靠与安全、透明、隐私与保障、负责”六个负责任的人工智能原则(Responsible AI Principles),随后又发布了负责任的人工智能标准(Responsible AI Standards)将各项原则实施落地,并设置了治理架构确保各团队把各项原则和标准落实到日常工作中。微软也持续与全球的研究人员和学术机构合作,不断推进负责任的人工智能的实践和技术。



