

编者按:当大模型的规模不断突破极限,AI 训练的算力需求也在以指数级攀升。传统 GPU 已难以兼顾性能与能效,异构 AI 芯片逐渐成为新趋势。但如何让不同计算单元“协同作战”,仍是编译领域的一大难题。北京大学、微软亚洲研究院、帝国理工学院与上海交通大学联合团队研发的 PipeThreader 系统,旨在解决这一核心挑战。PipeThreader 首次提出“流水线导向编译”理念,让编译器能够像“流水线设计师”一样,为异构芯片自动规划最优执行方案。实验表明,PipeThreader 在 Transformer、FlashAttention、Mamba 等模型上均取得显著加速效果,最高可实现近两倍性能提升,并能轻松迁移至不同硬件平台。这一成果不仅突破了传统手工调度的瓶颈,也预示着智能编译的新方向——让编译器理解硬件、自动优化算力。相关论文已被 OSDI 2025 接收。
随着大模型规模的急剧膨胀,AI 训练的计算需求呈指数级上升。传统的 GPU 加速方案已经难以满足效率与能耗的双重要求。如今越来越多的厂商开始设计异构 AI 芯片,它们集成了不同类型的计算单元,如矩阵乘法加速器、向量单元、通用核、DMA 引擎等,以求在性能与能效之间取得平衡。
然而,新的问题随之而来。这些执行单元的计算特性和带宽约束各不相同,如何让它们协同工作、实现高效流水线并行,成为 AI 编译器面临的最大挑战之一。
手工排布算子(operator pipeline)几乎无法应对现代模型的复杂度,每一层、每一个算子,都可能跨越多个异构单元执行,稍有不慎,就可能导致资源浪费或流水线阻塞。目前广泛使用的 FlashAttention-3 算子即为一个典型例证。它通过精心设计的多阶段流水线,在显存访问与计算之间实现了极高的并行效率,但这种“手工调度”的方式往往需要经验丰富的专家,花费大量时间反复试验与调优,不仅开发周期长、可移植性差,还极易出错。
为了解决这一问题,微软亚洲研究院与来自北京大学、帝国理工学院以及上海交通大学的科研人员们合作,提出了一个面向异构 AI 芯片的智能流水线编译与调度系统 PipeThreader。它的目标非常明确:让 AI 编译器能够自动学会在异构硬件上“排兵布阵”,让每个算力单元各司其职、协同高效。相关论文已被 OSDI 2025 收录。
PipeThreader: Software-Defined Pipelining for Efficient DNN Execution
论文链接:https://www.usenix.org/conference/osdi25/presentation/cheng (opens in new tab)
异构执行的“乱麻”困境
当今广泛使用的异构架构 AI 芯片,可能同时拥有多个不同的专有计算单元:专用于矩阵乘法的 Tensor Engine、处理通用计算任务的 General Compute Core 以及进行片上/片外数据搬运的 DMA 单元。
这些单元的性能差异极大,如果编译器直接照搬“静态算子图”的执行顺序,往往会出现部分模块空转、数据阻塞的情况,最终导致整体性能严重下滑。
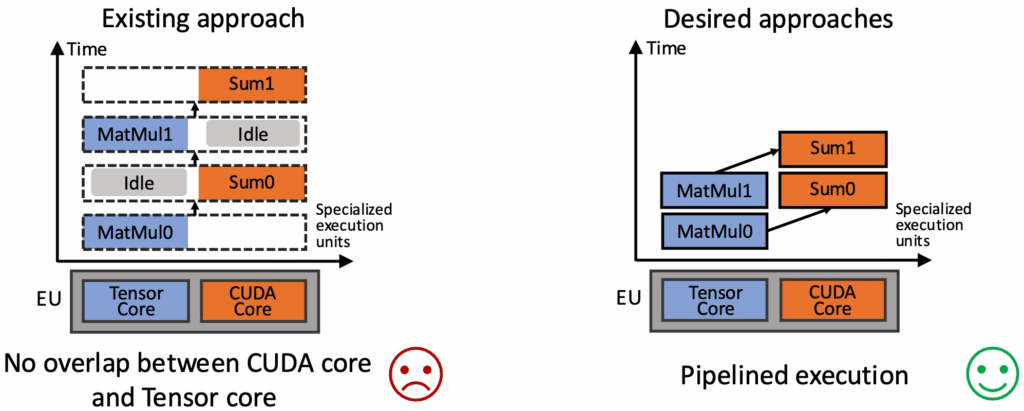
传统“以算子为中心”的编译思路已经无法适应这种碎片化的算力格局。针对这一情况,PipeThreader 重新定义了 AI 编译的目标——从算子编译转向流水线编译(pipeline-oriented compilation)。
PipeThreader 让编译器成为流水线设计师
PipeThreader 的设计灵感来自于硬件流水线与操作系统线程调度的结合。研究员们将模型执行过程抽象为一组“专有执行任务”(specialized task),并为每个专有执行任务分配一个“异构执行单元”(specialized execution unit)。这一看似简单的重新抽象,却带来了质的飞跃。
PipeThreader 不再单独关注每个算子的执行方案,而是从更高的层面进行整体规划:在这些异构执行单元上,哪些任务可以并行执行、哪些数据通路会形成瓶颈、如何在异构单元间平衡负载。
为了在复杂的异构硬件上实现高效的流水线执行,PipeThreader 提出了三个关键抽象:sTask、sGraph 和 sEU。这三者构成了系统的核心语义层,使编译器能够从任务、依赖关系和硬件资源三个维度统一理解整个计算过程。
- sEU(specialized execution unit):抽象出硬件层面的执行资源,包括不同类型的加速单元、带宽约束与存储特性,为任务分配提供精确的硬件视角。
- sTask(specialized task):表示可独立执行的计算任务,是流水线中的基本工作块。每个 sTask 对应模型中的一段计算逻辑,可以在不同的执行单元上灵活调度。
- sTask-graph(specialized graph):用于描述 sTask 之间的依赖关系与数据流向。通过将模型计算图转化为 sTask-graph,PipeThreader 能够清晰地捕捉 sTask-graph 间的并行性与流水线潜力。
在这三种抽象的基础上,PipeThreader 结合了一套自动搜索算法(auto search engine),能够在庞大的任务映射空间中快速探索最优的流水线排布方案。该算法会综合考虑执行延迟、数据传输开销以及各异构单元的并行度,通过代价建模与启发式优化,自动找到最平衡的调度策略,实现性能与能效的协同最优。
凭借这种“抽象+搜索”的设计,PipeThreader 不仅摆脱了手工调度的复杂性,还让编译器具备了在多芯片、多算子场景下的自适应能力,为自动化异构计算优化奠定了坚实基础。
从手工优化到自动流水线排布:性能的飞跃
在实验中,研究团队将 PipeThreader 部署到目前广泛使用的 AI 芯片上,并与主流 AI 编译框架和库(如 TVM、TensorRT)进行了对比,结果显示 PipeThreader 在多模型测试中表现出显著优势。
以 Transformer 模型为例,PipeThreader 相比 PyTorch-Inductor 实现了平均1.79倍的性能提升。传统方法通常需要工程师手动为每个算子指定执行单元,并依赖经验进行复杂的微调。而 PipeThreader 的自动调度器能够在极短时间内生成优化的流水线排布方案,并可直接迁移到不同模型中使用,大幅降低了编译与调优成本。
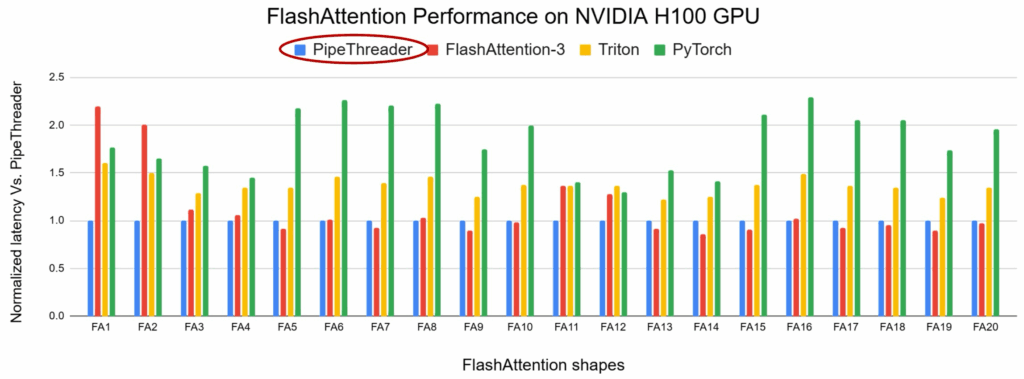
在 FlashAttention 算子上,PipeThreader 还能为每一个不同配置的算子自动生成最优流水线调度方案,在多种配置下均超越人工精调的 FlashAttention-3 实现,展现出更强的适应性与性能潜力。
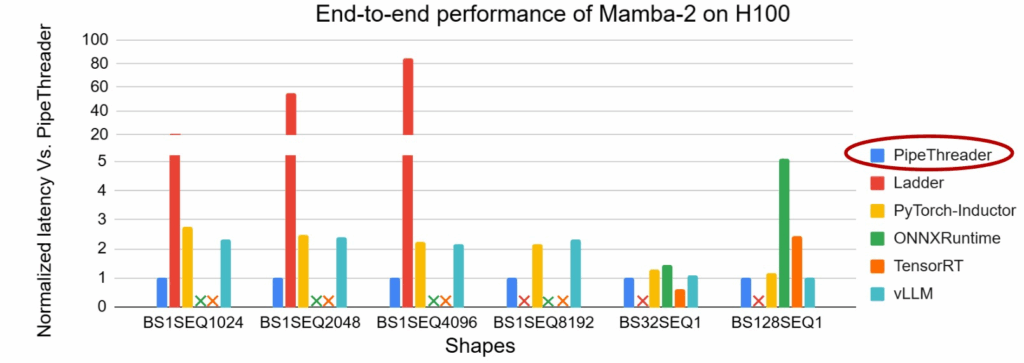
在更前沿的新型算子中,例如 Mamba 系列的 Linear Attention,PipeThreader 能够自动发现优于现有实现的流水线结构,实现了近2倍的加速效果。
更令人印象深刻的是,在一些尚未针对深度学习进行充分优化的硬件平台(例如 AMD GPU)上,PipeThreader 依然能够自动迁移并生成匹配新硬件特性的调度方案,显著提升整体性能。
目前,PipeThreader 已经被集成进开源项目 TileLang,成为其流水线优化的重要核心组件,帮助开发者在构建复杂的定制化算子时实现更高效、更智能的开发流程。
TileLang GitHub 链接:https://github.com/tile-ai/tilelang (opens in new tab)
面向未来:从异构算力到智能编译的新趋势
随着 AI 芯片架构的不断演化,硬件正变得前所未有地复杂。与此同时,模型本身也在快速进化:新型算子(如 FlashAttention、Linear Attention)层出不穷,网络结构更加灵活,数据依赖也愈发动态。
在这样的背景下,如何让编译器在复杂硬件与复杂算子之间实现高效协同,已成为下一代 AI 系统性能提升的关键。传统的静态优化与手工调度方式显然难以应对这种复杂度,而 PipeThreader 正是在这一趋势下迈出的重要一步。
不同于以往从算法层面出发的优化方案,PipeThreader 从硬件特性的角度重新思考了编译过程:它将硬件执行单元的算力、带宽特征与算子时序结构深度结合,通过自动化的流水线调度机制,让系统在底层实现了更高效的资源协同。这种方法不仅带来了显著的性能提升,也展现出一种新的编译方向——让编译器理解硬件特性,并以硬件为导向进行优化。
可以预见,随着异构 AI 芯片和新型算子的持续演进,像 PipeThreader 这样以自动流水线调度为核心的编译系统将愈发重要,为未来的高效 AI 计算开辟新的可能性。



