

编者按:检索增强生成(RAG)技术因在减少生成幻觉和虚构信息方面的显著效果,以及对知识及时更新能力的改善,正逐渐成为大语言模型系统的主流架构之一。随着 RAG 技术的广泛应用,其核心组件——向量数据库,也开始受到越来越多的关注,成为大模型中不可或缺的外挂知识库。
然而,向量数据库与传统关系型数据库有着显著区别,这给数据的统一管理、查询和更新带来了诸多不便。为此,微软亚洲研究院开发了 VBase 复杂数据库查询系统,为统一化数据库奠定了基础,并推出了有助于向量索引实时更新的 SPFresh 方案,以及可对稀疏向量索引与稠密向量索引统一化查询的 OneSparse 系统。
如今大语言模型(LLMs)已成为内容创作、语言理解和智能对话等领域中的关键技术,但这些模型都是基于固定训练数据中观察到的规律和模式来生成回答的,可能会产生幻觉和虚构信息,并在实时的知识更新方面存在困难。检索增强生成(RAG)技术可以将最新的外挂知识库与大语言模型有机结合,把相关的精确知识放入上下文中,来引导回答的生产过程,增强大语言模型的性能与可靠性。
然而,RAG 的核心组件之一——向量数据库,在存储、查询等机制上与传统的关系型数据库存在显著区别。这给日益丰富和不同模态知识的统一管理带来了挑战。在这种背景下,微软亚洲研究院系统与网络组的研究员们认为,一种能够有效管理丰富属性和模态的外部知识的统一化数据库,将成为大语言模型广泛应用和可靠性保证的关键。
“随着大模型能力的不断增强,文字、图像、视频等各种形式的数据都可以通过机器学习技术编码成高维向量,将知识的细节属性,如图片的类型、用户的偏好等,转换为不同维度的数据。但是,多样化的知识表示方式给复杂向量数据和标量数据的有效管理带来了挑战,如何在这些混合信息中实现高效且准确的查询也变得更加困难。这就需要一种统一化的数据库来管理这些外部知识,为大语言模型提供更坚实的知识支持。”微软亚洲研究院(温哥华)首席研究员陈琪表示。
以医疗辅助诊断场景为例,医生可能需要在患者记录数据库中进行如下查询:“在60岁以上的患者中,某些X光图像类似的病例,患有不同疾病的概率是多少?”这样的操作不仅需要从标量数据库中查询年龄、性别、诊断结果等标量数据,也需要从向量数据库中查询X光图像和实验室结果等高维向量数据。由于两种数据库的存储和查询机制截然不同,所以只有通过更高级的标量—向量混合数据分析技术,才可以将向量数据库与传统数据库进行有效统一。

VBase复杂查询系统:为向量索引和标量索引扫描提供统一化基石
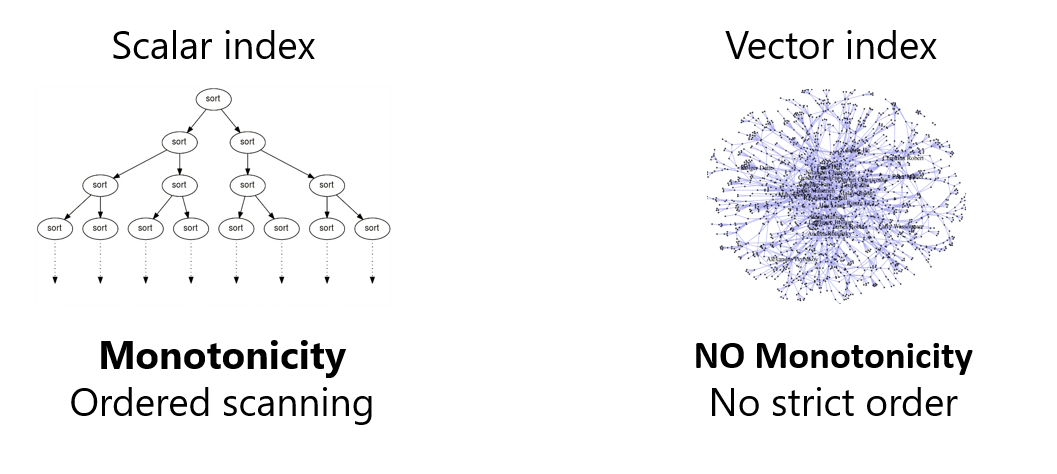
向量数据库与标量数据库具有不同的索引扫描模式,缺乏统一的基础,这是构建统一化数据库首先要解决的问题。
标量数据库索引基于数值顺序构建,索引扫描具有严格的单调性(strict monotonicity),这也是关系型数据库能够高效执行查询的原因。例如,在购物平台上搜索价格在100到200元之间的衣服,系统会从价格100元开始扫描,一旦价格超过200元,查询就会终止。显然这种基于单调性的标量查询具有很高的效率。
相比之下,向量索引是基于高维空间中的接近性构建的,索引遍历无法遵循严格的顺序,因此缺乏单调性。向量索引仅为查询提供近似的空间导航,以近似地接近最近的子空间。为了实现提前终止,向量索引扫描过程依赖 TopK 算法来预测 K 值的临时顺序。换言之,由于没有明确的起点,在高维向量空间中寻找与目标距离最近的向量时,尽管可以利用顺序来提前终止执行,但这种方法效率很低。
例如,假设用户有一张衣服的图片,想要在购物平台上找到相似且价格低于200元的商品,传统的方法是先进行大规模的相似性查询,然后根据价格进行过滤。比如,为了找到最相似且价格合适的前10个结果,可以先将搜索范围设定为1000个候选项,并通过价格条件逐一筛选,直到找到10个符合条件的结果为止,如果结果不足,则进一步扩大搜索范围到2000或者3000个,直到满足要求。
这种方法的核心思想是将向量数据的检索结果,转换成遵循严格单调性的标量数据库,再进行标量查询。TopK 算法被用于收集 K 个最接近的向量结果,并根据与目标向量的距离进行排序,从而创建一个具有单调性的临时索引,然后对这个临时索引数据库进行过滤。
这种方法的问题在于,无法保证返回的 K 个结果能满足最终的过滤查询需求。因此,为了确保过滤结果满足要求,要么 TopK 需要执行更广泛的相似性查询,返回更多的 K;要么在 K 不足时,重复执行 TopK 查询,但这两种做法都会导致次优的查询性能。
研究员们通过分析大量向量索引发现,向量索引查询提前终止并不需要严格的单调性,而是表现出一种放松单调性(Relaxed Monotonicity),标量索引只是这种放松单调性的特殊情况。
基于这一发现,研究员们开发了 VBase 复杂查询系统,该系统为向量索引和标量索引的高效扫描提供了统一化基石,使得各类索引的扫描遵循相同的接口和提前终止条件。这一创新使得向量数据库在执行复杂查询时的性能提升了10至1000倍,同时提高了查询的精确度。
VBase 使得构建能够执行各类复杂关系型向量和标量混合查询的统一化数据库成为可能。目前,基于 VBase 系统,一家开源数据库平台成功构建了自己的多模态向量数据库。
论文链接:
SPFresh:首次实现向量索引的实时就地增量更新
以向量数据库检索为基础的 RAG 技术显著提高了大语言模型生成结果的准确性。但这一优势的实现有一个关键前提:向量数据库中的数据需要保持更新,也就是说向量索引需要即时更新。对于具有成百上千维度的向量来说,更新工作并非易事——重构向量索引的时间成本需要以天来计算。
标量数据库通常使用 B 树或 B+树方法,通过二分查找定位到指定位置后直接插入信息即可完成更新。然而,向量数据库的更新要复杂得多。
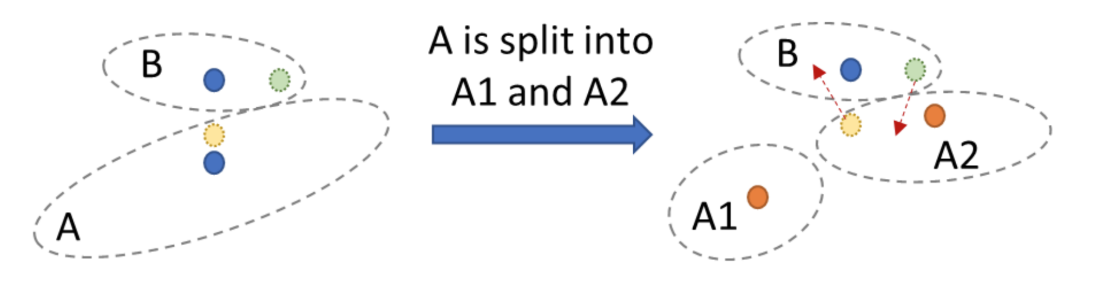
以目前流行的细粒度基于图的向量索引和粗粒度基于集群的向量索引为例。在细粒度图向量索引插入或删除向量时,都需要进行大规模的图扫描以找到适当的距离进行插入,这对计算资源的要求非常高,而且删除不当还会导致性能和准确性下降。在粗粒度的集群索引更新中,虽然插入或删除向量只涉及对分区的修改,成本较低,但随着分区更新的累积,数据分布会变得不平衡,从而影响查询延迟和准确性,使索引质量下降。
现有的向量索引更新方法依赖于周期性的全局重建,这种方法速度慢且资源消耗大。尽管重建后性能和准确性会立即得到刷新,但在两次重建之间,性能和准确性会逐渐下降。此外,全局重建成本非常高,其所需的资源是传统索引的10倍以上,甚至超过索引服务的成本。
为解决这些问题,研究员们提出了 SPFresh 解决方案,该方案首次实现了向量索引的实时就地增量更新,为统一化数据库的更新提供了一种高效的方法。SPFresh 的核心是 LIRE——一种轻量级的增量再平衡协议,用于分割向量分区并重新分配分区中的向量以适应数据分布的变化。LIRE 通过仅在分区边界处重新分配向量,实现了低资源消耗的向量更新。
与已有的周期性索引重建方法相比,SPFresh 能够大大减少索引重建所需的资源成本,并且能够始终保持稳定的高召回率,低延迟和高查询吞吐量,及时有效地适应数据分布的动态变化。
论文链接:
SPFresh: Incremental In-Place Update for Billion-Scale Vector Search (SOSP 2023)
OneSparse:稀疏向量索引和稠密向量索引的统一化查询
向量数据库广泛应用于自然语言处理、信息检索、推荐系统等领域,为处理非结构化数据提供了高效的解决方案。然而,向量数据的编码方式多种多样,稀疏向量和稠密向量各有优势,适用于不同类型的任务。例如,稀疏向量适用于关键字匹配任务,而稠密向量则更适合提取语义信息。因此,在实际应用中,多索引混合查询被广泛采用,尤其是在混合数据集中,通过结合稀疏和稠密特征的协同过滤技术来查找相似项,这种方法已被证明能够有效提升查询结果的精确度。
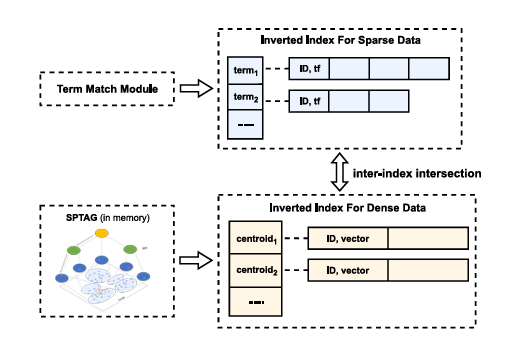
然而,由于向量索引的特殊遍历方式,多个向量索引之间的交集无法直接下推,导致多索引联合检索面临挑战。为此,研究员们提出了稀疏向量索引和稠密向量索引统一化技术 OneSparse,它能够执行多索引混合查询,并实时生成最优的表格合并计划,以实现快速的索引间交集和索引内并集。
OneSparse 将稀疏索引和稠密索引统一为一个倒序排列的索引,并根据文档 ID 重新排列所有发布列表,这样即使在执行语义匹配和关键词匹配的复杂查询时,也能保证高效的执行。相关技术已成功应用于微软必应(Bing)网络搜索和推广搜索中。
论文链接:
OneSparse: A Unified System for Multi-index Vector Search (ACM WEB 2024)
统一化数据库加速大语言模型的发展和硬件创新
早在2018年,微软亚洲研究院就开始了对向量数据系统的深入研究。陈琪表示,“当时,我们意识到向量化将成为深度学习应用的基石。因此,我们陆续开发了 SPTAG 和 SPANN 技术,成功解决了向量索引的泛化和可扩展性问题,并将其应用于微软必应搜索,实现了世界上最大规模的向量语义搜索系统。”
近年来,微软亚洲研究院的研究员们继续深耕向量数据库技术,在放松单调性和 LIRE 协议轻量级更新方法的基础上,构建了一个统一化数据库系统 MSVBASE,并已在 GitHub 上开源。MSVBASE 系统可用于多模态数据的语义分析,为开发人员研究和利用 RAG 机制,设计更复杂的 RAG 检索查询提供了强大的工具。RAG 技术将不仅能够执行基于 TopK 的向量查询,还能够利用更多高维向量数据和属性进行检索,实现更精确的查询结果。
GitHub 链接:
https://github.com/microsoft/MSVBASE (opens in new tab)
在知识大规模增长的今天,统一化数据库为未来多模态数据在模型的训练和推理之间提供了更好的知识传递,这对于支持万亿级别数据的检索查询至关重要。它为大模型提供了无限流的语料支持,并将推动底层硬件的创新,为未来数据增强型人工智能奠定基础。
相关链接:
SPTAG
链接:https://github.com/microsoft/SPTAG (opens in new tab)
SPANN: Highly-efficient Billion-scale Approximate Nearest Neighbor Search