

编者按:数据稀缺是目前限制通用机器人操作大模型进展的重要因素之一。基于遥操的机器人轨迹获取成本高、多样性不足、本体多变,难以获得支撑大模型预训练的海量数据。在人形机器人的发展路径中,人类可被视为最重要的参考形态之一。因此,直接使用真实的人类数据进行预训练,比用机器人数据具有更大的潜力。因为人类的形态和动作模式更稳定、通用,人类数据规模大、多样化且易于获取,更可能达到规模化,以提升模型的泛化能力。
基于这一理念,微软亚洲研究院的研究员们提出了一套全自动方法 VITRA,能够将无标注的真实的人类活动视频转化为与机器人训练数据格式完全对齐的数据。这一方法不仅破解了机器人模型训练数据匮乏的难题,更为 VLA 模型的预训练开辟了一种可规模化、可扩展的新范式。
当你看到机器人开始参加跑步比赛、在舞台上扭秧歌时,或许也曾畅想过这样的未来:只需通过自然语言向机器人下达指令,它便能帮忙收拾桌面、打扫卫生,甚至端茶倒水。
要让机器人真正“听懂人话”、“看懂世界”,并把理解转化为准确的动作,关键在于它是否拥有一个能够连接视觉、语言与行动的“大脑”,也就是视觉-语言-动作模型(Vision-Language-Action, VLA)——一种能够理解任意人类语言指令,并在真实世界中执行复杂任务的智能模型。
为了让 VLA 模型能够高效学习人类的行为模式,微软亚洲研究院提出了 VITRA 预训练方法。该方法创新性地将非结构化的、真实的人类视频自动转化为与现有机器人数据一致的结构化 VLA 格式。得益于这种自动化、可扩展的方法,研究员们训练出的 VLA 模型在从未见过的环境中展现出了更强的零样本预测能力,并能在真实任务中通过少量机器人数据进行高效微调,且在新物体与新环境上表现出更强的泛化能力。
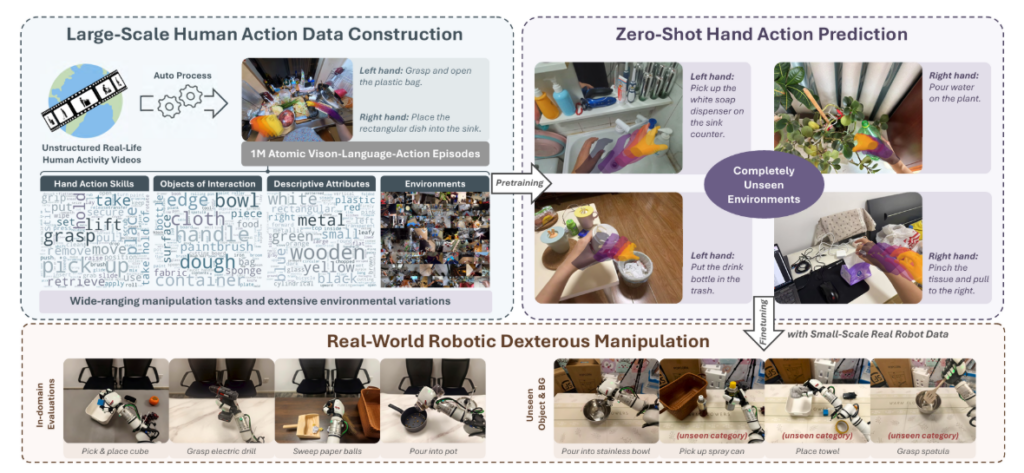
图1:全新的机器人 VLA 模型预训练方法 VITRA,可将非结构化的人类视频转换为与现有机器人数据一致的结构化 VLA 格式。
“自产自销”的机器人数据采集方法面临多重瓶颈
大语言模型的成功,离不开互联网上万亿级的文本数据。同样,若想让 VLA 模型具备强大的泛化能力,也需要海量且多样化的训练数据。然而,传统机器人这种“自产自销”式的数据采集,几乎等同于一场高成本的“数据淘金”。
这类方法通常依赖两种途径:一是在实验室中由人工摇操机器人执行任务并记录数据,二是通过仿真环境生成合成数据。前者受限于设备部署和人力投入,后者则难以真实还原现实世界的物理交互与环境复杂性。
此外,这些方式还存在以下三个主要问题:
- 高成本:部署和维护机器人、雇佣大量操作员进行遥操训练的费用惊人。
- 低效率:数据采集速度缓慢,难以像互联网数据那样实现指数级规模的扩展。
- 多样性不足:受资源限制,数据集中涵盖的物体类型、操作技能和场景变化极为有限,难以覆盖真实世界中的复杂情境,严重制约了模型的泛化能力。
“我们发现,其实一个巨大的数据宝库就在我们身边——那就是互联网上海量的人类活动视频。”微软亚洲研究院高级研究员邓誉指出,“从烹饪教学到家装维修,从手工艺制作到日常家务,这些视频记录了人类在各种真实环境中的动作与经验。”
研究员们认为,既然当前人形机器人的发展目标是接近人类的能力,那么人类数据就是训练机器人的最佳教材。
“为什么不直接让 VLA 模型从人类视频中学习呢?”邓誉提出,“我们可以把视频中的人类视作机器人,把他们的双手看作机器人的末端执行器。通过将这些无结构、未标注的人类视频自动转换为与机器人数据格式完全一致的轨迹数据,我们就能在规模、质量与多样性上,将机器人训练数据提升到前所未有的水平。”
三步将非结构化人类视频转换为机器人可用的结构化数据
标准的 VLA 机器人数据通常由一些原子级任务组成,例如:“拿起物体并放到指定位置”、“打开或关闭容器”、或“推/拉”等动作。每一条 VLA 数据包括三部分:机器人本体操作时的视频、人类编写的语言指令,以及机器人执行动作时各关节的三维运动信息,如位移、旋转和灵巧手状态变化。
那么,如何让海量、杂乱、无标注的人类视频,变成结构化的机器人训练数据?研究员们将整个流程分为三步:
第一步:看清动作——3D 重建视频轨迹,还原真实空间动作
大多数人类视频由单个摄像头拍摄,仅能呈现手部的二维图像,无法直接反映其在三维空间中的真实位置。
为此,研究员们采用最新的 3D 视觉技术(如深度估计、相机姿态追踪、三维人手重建等),先判断摄像头是静止还是移动的,再自动校准相机参数,最终重建出每一帧中人手的 3D 姿态。这其中不仅包括手腕在空间中的位置与旋转角度,还包含每根手指关节的弯曲程度,以及摄像头本身的运动轨迹。这样,VLA 模型就不再只是“看视频”,而是能够真正理解人手在三维空间中的动作。
第二步:原子级动作切分——基于运动规律,自动将长动作拆解为短任务
人类操作往往是连续进行的,例如“从冰箱拿菜→洗菜→把菜放到厨房台面上→切菜”。但机器人训练需要的是原子级的短任务片段,如单独的“把菜放到厨房台面上”。在研究过程中,研究员们发现,人类在真实生活场景中的动作模式存在类似“呼吸”一样的节奏规律:不同动作切换之间,手的运动模式也有明显的变化,此时运动速度会出现瞬间的极小值。例如,在抓取杯子前手会减速对准,放下杯子后会短暂停顿,再执行下一个动作。
利用这个规律,研究员们以 3D 轨迹中的速度最小值为“切割点”,自动将长视频切分成多个短片段。这种方法无需依赖预定义的动作类别,让每个片段只包含一个原子级动作,正好匹配机器人训练所需的“短任务”粒度。
第三步:理解动作——融合 3D 轨迹,生成精准语言指令
切分后的视频片段还需要配上准确的语言指令才能用于训练。研究员们希望通过视觉语言模型来完成这项工作,但真实场景的复杂性会对模型的判断造成一定的困扰。直接把原始视频片段输入模型可能导致模型错误判断人手的动作和交互对象,例如将“拿勺子”误判成“拿叉子”。
为此,研究员们将重建的 3D 手部轨迹叠加到视频帧上,像在画布上描绘“动作路线图”一样,让模型可以清楚地“看见”人手的运动轨迹。这样,模型便可生成更符合机器人训练需求的语言指令,大幅提升了标注的准确率。
通过这套全自动数据转化流程,研究员们构建了一个大规模的 VLA 数据集。该数据集训练基于多个公开的第一人称视角视频数据集(如 Ego4D、EPIC-KITCHENS 等),经过处理后包含超100万段动作片段和3000万帧画面,覆盖厨房烹饪、家庭清洁、手工制作、建筑维修等多种场景。“这几乎涵盖了人类日常生活和专业工作中的各类操作,远超现有机器人数据的多样性与规模,为训练具备通用灵巧操作能力的机器人提供了一种可扩展、可持续的新范式。”邓誉介绍道。
适配真人数据的VLA模型暗藏两处“小巧思”
有了高质量的人类行为数据集,还需要一个能够充分理解这些数据的 VLA 模型。研究员们在主流的 VLA 架构基础上,针对人类视频数据的特点做了两项关键优化,使模型能够更准确地学习人类真实的操作行为,为后续向实体机器人迁移做好准备。
首先,加入更多参数让模型更“懂镜头”。人类视频的拍摄设备五花八门,手机、单反相机、运动相机……它们的焦距、视场角各不相同。同一个动作,长焦镜头看起来更近,广角镜头则显得更远。如果模型不理解这些差异,就可能误判动作在真实三维空间中的尺度与距离。
为此,研究员们将相机的焦距、视场角等参数作为额外输入“喂”给模型,帮助模型自动校正对画面的空间感知,避免了模型因拍摄设备不同而产生的认知偏差,从而能够生成更合理的 3D 动作预测。
其次,引入因果注意力机制,解决动作片段不完整问题。真人视频切分后,可能会出现一种特殊情况:有些片段的动作并未完整结束。例如,“拿起杯子”可能第一步只剪切到了“手碰到杯子”的那一刻,而“抬起杯子”的部分已经被裁掉。如果按照传统方法,在片段末尾补上“零动作”(即无动作帧)来对齐序列长度,等于告诉模型“碰到杯子后就该停止”,导致模型学习到错误的动作模式。此外,真实生活中,人在完成一个动作的末尾阶段也可能存在无意义的动作,即“噪声动作”,这些多余的动作也会对整个过程动作的预测产生影响。
为了解决这一问题,研究员们把模型中的动作生成模块改为了因果注意力机制,让模型在预测当前动作时,只能关注序列中前面的帧,而不是看到后面补零的帧以及一些无意义的噪声运动。这种单向注意力结构模拟了真实世界中的时间因果关系,有效防止了未来信息对当前动作预测的干扰,使模型即使面对不完整的动作片段和真实场景的运动噪声,也能正确学习到人类真实的连续操作逻辑。
强大的零样本预测与泛化能力,开启可扩展的VLA新范式
全新的 VLA 模型预训练方法究竟效果如何?
研究员们在人手运动预测和真实灵巧手机器人上进行了验证,结果超出预期:该方法在人类数据上预训练的模型,在人手动作预测上展现出更强的零样本预测能力;在微调后,机器人在真实任务中的执行成功率也显著提升,表现出极强的泛化能力。
人手部动作预测上的零样本表现优异:面对完全未见过的场景,如陌生的厨房、从未接触过的家具,只要给出自然语言指令,例如,“从抽屉里拿取某个物体”,或者“将水倒入某个杯子里”,模型就能预测出合理的人手动作,且表现远超基于实验室数据训练的模型。
通用视觉理解能力的有效“继承”:研究员们进一步发现,使用人手数据进行全参数训练后的 VLA 模型,即便没有额外的训练技巧,仍能够在很大程度保持原有视觉-语言模型(Vision-Language-Model,VLM)的通用视觉理解能力。例如,在给模型几张物体照片并要求其预测抓取其中一张照片的人手动作时,尽管这些概念在 VLA 预训练阶段从未出现过,但模型依然能够准确选出目标照片并生成合理的抓取动作。
真实机器人的微调效率显著:研究员们仅使用1000余条机器人遥操数据对模型进行微调,在灵巧手完成“随机位置摆放的抓取放置”、“功能抓取(如抓杯子把手)”、“倒水”、“扫地”四项任务中的平均成功率,便从无人手预训练模型的30%-40%提升至70%以上,其中“抓取放置”任务成功率超过80%。这相比之前的预训练方法,如利用大规模机器人数据预训练或者人类视频预测、潜动作预训练的方法等都有显著提升。
更强大的泛化能力:面对训练中从未出现过的物体,例如新型保温杯、异形玩具,机器人仍能保持约70%的成功率。即使是完全陌生的物体类别,例如未见过的电脑电源适配器,机器人也能凭借在人类视频中学到的“相似物体抓取逻辑”,完成准确的操作,大幅超越以往预训练方法的泛化能力。模型不仅记住了具体动作,也掌握了“操作逻辑”,具备了应对训练数据之外新情况的能力。这是因为人类数据的多样性远超实验室机器人数据,而且人手和灵巧手的动作模式更相似,知识迁移更为顺畅。
对 VITRA 方法的研究,为可泛化 VLA 模型提供了一种极具前景且可规模化、可扩展的预训练范式。随着机器人硬件的不断进步,真实人类视频数据将成为取之不尽的训练资源,让机器人能够持续学习人类的各种操作技能。也许在不久的将来,我们就能看到真正通用的机器人助手走进日常生活。
正如邓誉所说,“人类是目前人形机器人想要达到的终极形态。”通过让机器人“观看”并“理解”真实的人类行为,将加速这一愿景从设想走向现实。
VITRA相关链接:



