

编者按:当“更大、更快、更高效”的 AI 计算成为业界追求的方向,在硬件革新之外,系统软件层的突破同样关键。微软亚洲研究院与爱丁堡大学联合提出的 WaferLLM 正是这一探索的重要尝试。该研究聚焦于晶圆级 AI 计算平台的系统软件优化,从架构原理到推理性能全面重构,为 AI 计算的未来提供新的视角。相关论文已被 OSDI 2025 接收。
随着 AI 模型规模持续膨胀、计算复杂度急剧上升,传统芯片架构的性能与能效正在逼近极限。要突破这一瓶颈,业界开始探索更大尺度、更紧密集成的计算形态:晶圆级 AI 计算(Wafer-Scale AI Compute)。它可将上百万个计算核心与海量片上存储整合在一整片硅晶圆上,让数据在晶圆内部流动,大幅减少跨芯片通信的成本。
但硬件创新只是开始。要想真正释放晶圆级 AI 芯片的潜力,系统软件必须同步重构。为此,来自爱丁堡大学和微软亚洲研究院的研究员们提出了面向晶圆级平台的大语言模型(LLMs)推理系统 WaferLLM。它实现了每 token 亚毫秒级(<1ms)延迟,展示了晶圆级计算在 AI scaling 上的巨大潜力。相关论文已被 OSDI 2025 接收。
WaferLLM: Large Language Model Inference at Wafer Scale
论文链接:https://www.usenix.org/conference/osdi25/presentation/he (opens in new tab)
GitHub 链接:https://github.com/MeshInfra/WaferLLM (opens in new tab)
从AI规模法则到晶圆级计算
在过去几年中,AI 规模法则(Scaling Laws)被多次验证:更大的模型和更强的算力往往能够带来更高的精度与“涌现能力”。这让业界不断追求更大规模的计算平台。
然而,多 GPU 集群在扩展时会遭遇通信瓶颈,跨芯片数据传输的延迟和能耗极高,抵消了算力扩展所带来的收益。为了解决这些问题,硬件厂商开始探索“晶圆级集成(System-on-Wafer, SoW)”技术,也就是在同一片晶圆上集成更多核心与内存,使数据能够在片上局部传输。
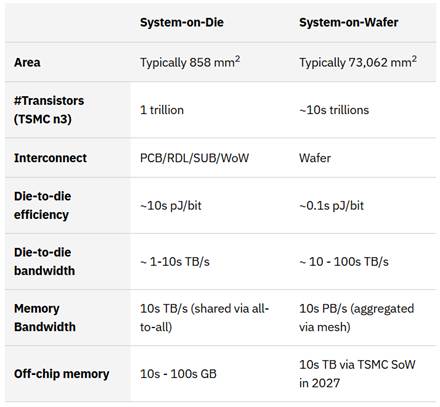
近年的半导体工艺进展让这一愿景变得可行。得益于先进的封装、更小的制程节点以及高效的散热技术,晶圆级架构能够安全稳定地工作。以台积电(TSMC)的 SoW 技术为例,其可将芯片面积扩展至整片晶圆,是传统芯片的数十倍。片上通信的能效比板级互连高出10到100倍,更适合高带宽、低延迟的 AI 推理任务。
目前,NVIDIA、AMD 等公司都在推动更大尺寸的芯片和晶圆级方案。业界预测,晶圆级计算将成为下一代 AI 基础设施的重要方向。与此同时,很多企业也开始尝试在晶圆级系统上运行大语言模型。
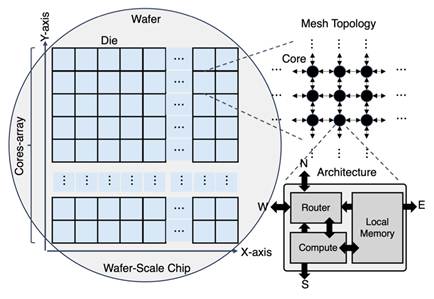
晶圆级带来的软件挑战与PLMR模型
晶圆级系统在规模与结构上与传统 GPU 完全不同。晶圆级平台虽然在物理结构上突破了限制,但在系统软件层面带来了全新的复杂性。
为了系统性刻画这些特征,研究员们提出了 PLMR 模型,从四个维度总结了晶圆级 AI 芯片的软件挑战:
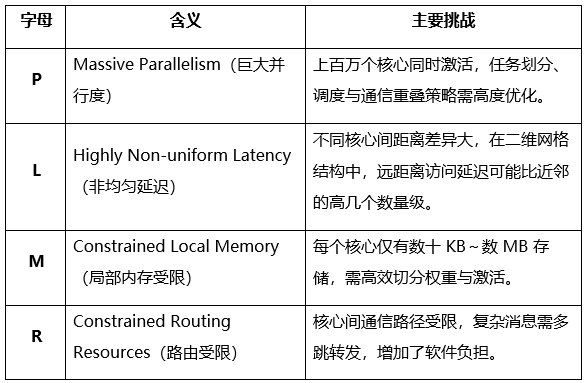
若要在晶圆级平台上编写高性能 AI 软件,必须遵守“PLMR 原则”:
- 计算与数据划分应兼顾 P、M:合理分布负载、避免越界。
- 通信设计要尊重 L:减少远距离传输、优先局部访问。
- 消息路由与邻域通信要符合 R 的限制:降低多跳通信带来的开销。
直接套用传统的 GPU 集群框架(如 MPI),则会出现通信开销过大、内存失衡或同步延迟等问题。
WaferLLM:晶圆级平台上的高速LLMs推理系统
基于 PLMR 模型,研究员们开发了 WaferLLM——一个为晶圆级平台(如 Cerebras WSE-2)量身定制的 LLMs 推理系统。它在并行策略、通信算子和缓存管理上进行了全面重构,实现了每 token 小于1毫秒的延迟。
在实现晶圆级 LLMs 推理的过程中,WaferLLM 针对架构特点进行了系统性的优化设计。首先,在并行策略上,研究员们提出了更适配晶圆级架构的分布方案。通常,大语言模型的推理可分为两个阶段:Prefill 阶段负责加载模型权重并执行大规模矩阵乘法(GEMM),而 Decode 阶段则在生成每个 token 时执行矩阵向量乘法(GEMV)并访问 KV 缓存。
WaferLLM 针对这两个阶段采用了不同的优化策略。在 Prefill 阶段,对激活与权重矩阵进行二维划分;在 Decode 阶段,使用复制与切分相结合的方式,使计算与数据更均匀地分布在各个核心上。此外,系统还在预处理阶段完成了矩阵转置,以避免运行时的高延迟通信。
针对晶圆级芯片独特的网格互连结构,WaferLLM 设计了两种高效算子:
- MeshGEMM:通过循环移位 (cyclic-shifting) 与交错 (interleaving) 策略缩短通信路径,使通信开销降低2至5倍,整体性能提升1.3至2倍。
- MeshGEMV:用 K-tree Allreduce 机制缩短关键通信路径,使通信开销减少1.5至6倍,整体加速可达2.5至3倍。
在缓存管理方面,WaferLLM 提出了基于移位(shift)的 KV 缓存重分布方法。该策略允许相邻核心并行调整缓存布局,从而平衡内存使用,避免显存溢出(OOM),并支持更长的上下文推理。
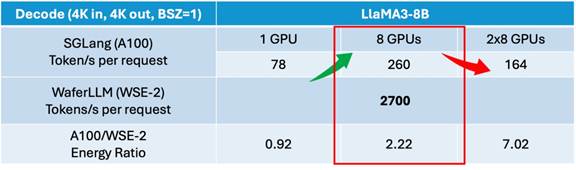
在真实的 Cerebras WSE-2 晶圆级芯片测试中,WaferLLM 展现出了显著的优势。当 SGLang 或 vLLM 从单张 A100 扩展到8张 A100 GPU 时,解码速率从78提升至约260 tokens/s,虽然提升明显,但仍未达到理想的8倍扩展。随着集群规模进一步扩大,跨节点通信的成本甚至超过了计算收益,整体性能开始下降。相比之下,WaferLLM 在晶圆级芯片上避免了这种通信瓶颈,推理速度达到2700 tokens/s,即每个 token 的延迟低于1毫秒。
在单卡规模下,WaferLLM 的能量效率与 A100 相当(能量比约为0.92)。当系统扩展至更大规模时,WaferLLM 的能量比提升到2.22,说明晶圆级架构在高并行度场景下能实现更优的性能与能耗平衡。
总体来看,晶圆级计算在超大规模、低延迟推理任务中展现出强劲的潜力,特别适合需要快速生成和高实时性的 test-time scaling 场景。
AI系统堆栈的“晶圆级重构”
WaferLLM 只是一个起点。要让晶圆级 AI 计算真正走向成熟,还需要多个层面协同创新:
- 模型架构与硬件协同
未来模型的设计应更紧密地结合硬件特性,在训练阶段纳入通信和分布策略的优化,以充分发挥晶圆级架构所提供的高并行度和高带宽优势。
- 系统软件与编程模型革新
传统 MPI 或线程模型难以适应面向数百万核的异步分布式系统,需要重新设计运行时、调度与内存管理机制。一个“晶圆原生(wafer-native)”的编程范式或将成为突破口。
- 硬件拓扑与网络创新
当前主流的二维网格拓扑在部分通信模式(如 All-Reduce)下并不理想。未来可能出现混合或可重构的 NoC 结构, 以支持更灵活的模型架构和通讯需求。
晶圆级 AI 计算正在重新定义算力的边界。它既是一场硬件革命,也是系统软件与模型协同设计的范式转变。未来,计算的极限将不再由芯片面积决定,而取决于系统与智能的共生演化。



