

Efficient AI
Reimagining AI efficiency from GPU kernels to context engineering to power Copilot-scale intelligence.
Our mission
We work to advance efficiency across AI systems by exploring novel designs and optimizations across the full AI stack: models, system design decisions, cloud infrastructure, and hardware. Our goal is to develop methods and systems that radically improve the cost, latency, and reliability of large-scale AI. We take an end-to-end approach, from GPU kernels to scheduling and batching policies to context and memory management, unlocking multiplicative gains rather than incremental improvements. By pushing the boundaries of efficiency, we enable AI that is faster, more sustainable, and ready to scale.
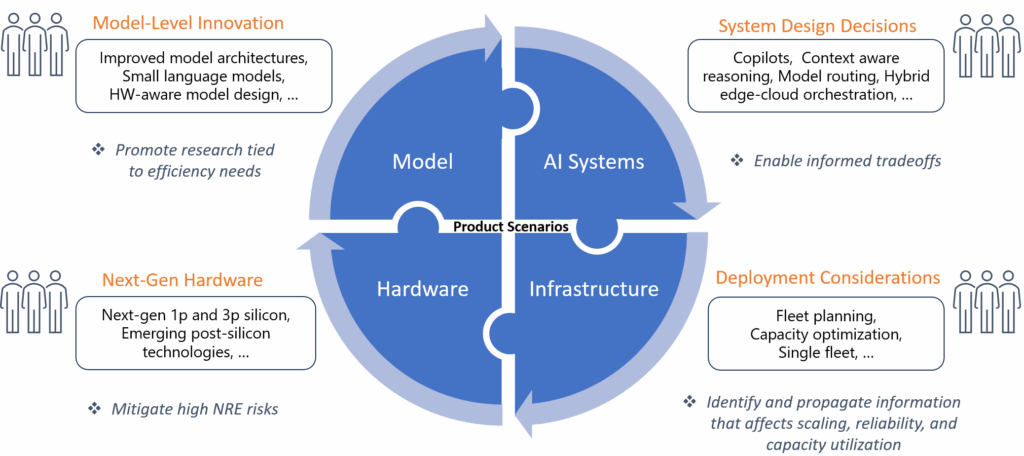
Our research
We design and optimize GPU kernels and model‑execution strategies to maximize throughput and minimize latency for real‑world LLM workloads.
We reimagine the AI inference stack, optimizing scheduling, routing, and resource allocation to deliver predictable performance and cost efficiency.
Long‑horizon assistants, reasoning‑heavy models, and agentic workflows drive significant inference‑time compute and context growth. We make AI smarter and leaner by engineering “context paths” that minimize redundancy while preserving utility.
News
-

A breakthrough in microfluidics brings liquid cooling directly into AI chips
September 24, 2025
-

Key insights from GenAI industry panel
June 26, 2025
-

Research Focus: Week of June 10, 2024
2024年6月12日




