

エキスパートに聞く! 未来を実現する IT インフラ
クラウド環境ではオンプレミスとは異なる運用管理が必要に
この1~2年で注目を集め始めた「NoOps」とは?
「オンプレミスのシステムで運用管理を担ってきた人たちがパブリッククラウドの世界に来ると、多くの人が大きなギャップがあることに驚きます」。日本マイクロソフトの真壁徹氏は自身の経験を踏まえて、このように指摘する。同氏は、オンプレミスとクラウドでは、運用に対する考え方が大きく異なっていると強調する。
ところで、この1~2年でにわかに注目を集め始めた「NoOps」というキーワードがある。「No Operations」の略語であるが、真壁氏は「運用に関わる作業や、それに携わる人たちが不要になるという意味ではありません」と注意を喚起する。運用に関する作業の中で「嬉しくないこと」をなくす「No "Uncomfortable" Ops」の意味だと説明する。

日本マイクロソフト株式会社
デジタルトランスフォーメーション事業本部
エンタープライズクラウドアーキテクト技術本部
クラウドソリューションアーキテクト
真壁 徹 氏
オンプレミスのシステムでは、ハードウエアやOS、ミドルウエア、アプリケーションの全てに対してユーザーが運用管理を担う必要があった。これに対して、クラウドサービスの場合、 IaaS(Infrastructure as a Service) であればハードウエアの運用管理をクラウド事業者に委ねられる。
PaaS(Platform as a Service) のようなマネージドサービスを活用すれば、ユーザーはアプリケーションの運用に集中できる。既存のIT組織の関与がなくてもシステムを構築しやすい。実際、デジタルトランスフォーメーション(DX)に向けた取り組みでは、現業部門とクラウド専業のITベンダーだけでプロジェクトを進めるケースも多い。この結果として、何が起こったのか。真壁氏は次のように解説する。
「従来はIT組織、なかでもインフラチームが動かなければプロジェクトは進みませんでした。この体制では、ITインフラに対するガバナンスが利いていたはずです。しかし、インフラチームが関与しないパブリッククラウドのプロジェクトはガバナンスが効いていないことが多く、企業としてのポリシーが適用されていないがために、問題解決までに長い時間がかかってしまいます。セキュリティ対策不備など、問題そのものを生み出してしまうケースも散見されます」
ガバナンスやポリシーの後付けは容易ではない。設計段階で考慮することが重要だ。クラウドサービスを使うから運用は不要と言いながら、何かあったら運用でカバーという考えは矛盾している。これではNoOpsどころではない。NoOpsはアプリとインフラの専門家が協力し設計することで実現できる。
ビジネスオーナーとサービスレベルを合意することが必要
クラウドサービスとそのエコシステムが進化した結果、現在は監視・通知や構成変更をはじめとして「嬉しくないこと」を支援、自動化するツールが充実し始めている。その半面、NoOpsに向けて、どこから着手していいか分からないという企業も少なくないだろう。真壁氏は「まずは、そのシステムが支えているビジネスのオーナーとサービスレベルに対して合意することが必要です」と説明する。例えば可用性の目標値がなければ、それを向上させるためにどれだけの施策や投資が必要であるかを判断できないからだ。
ビジネスオーナーは、往々にして「システムは動き続けるのが当たり前」という意識を持っている。しかし、オンプレミスとクラウドのいずれにしても、可用性を100%にすることは難しい。クラウドサービス自体のSLA(サービスレベル契約)も100%のものは稀だ。真壁氏は「サービスレベルの議論や合意がないシステムでは、雰囲気で100%の可用性を期待されがちになりますし、可用性を高めるための投資が認められないケースが多いのが現実です」と語る。
システム全体の可用性は、机上でも算出できる。そのシステムを構成する要素、例えばクラウド基盤やマネージドサービスなど個々の可用性を掛け合わせることで理論上の値が算出できる。この数値が、ビジネスオーナーと合意した可用性に達していなければ、どこかの要素の可用性を高める手だてを打つ。システム稼働後の監視で、合意した数値に達していなければアーキテクチャーやリカバリー方式の見直しなどの改善策を立案する。サービスレベルの合意ができていれば、ビジネスオーナーはこのための投資を必要なものだと判断してくれるだろう。なお、サービスレベルは可用性に限らない。他には応答性能などが挙げられる。数値化可能で、ビジネスに結びつくあらゆる指標がサービスレベルとして定義可能だ。この指標を実現するため、妥当性を検証しながら改善のプロセスを回していく。
![【ビジネスオーナーとサービスレベルを合意することが運用管理の大前提に】 [ビジネスオーナーとのSLO(Service Level Objective=サービスレベル目標)/SLA(Service Level Agreement=サービスレベル契約)の合意] - サービスレベルに合わせて実施 → [監視] -サービスレベルの未達 → [改善] アーキテクチャー、リカバリー方式の見直しなど - サービスレベルの妥当性検証 → (SLO/SLAの合意に戻る)](https://cdn-dynmedia-1.microsoft.com/is/image/microsoftcorp/mcaps-biz-cloudplatform-asktheexpert-RE3URf6?scl=1)
システムを構成する各コンポーネントを観測する仕組みを作る
真壁氏は、実際にシステムのサービスレベル向上に取り組む場合には、まずは「可観測性(Observability)」を担保することが重要だと指摘する。「可観測」とは、もともと制御工学の専門用語で、対象物が制御可能であるための必要条件である(観測できないものは制御できない)。「稼働中のシステムで何が起こっているのかを観測するための仕組みを作ることが、サービスレベル向上へ向けた第一歩です」と説明する。
オンプレミスの環境でも、ほとんどの企業が基幹系などの重要なシステムに対しては、監視のためのツールを導入してきた。ただし、シンプルな死活監視や、CPUやメモリー、ネットワークの利用率を監視する程度にととどまっているケースも多い。オンプレミスのシステムは、一般的にモノリシックなアーキテクチャーである場合が多く、構成する要素が少ない。また、基盤とアプリケーションの依存関係もシンプルだ。それであれば監視もシンプルな仕組みで十分、という判断もあっただろう。

これに対して、クラウド上のシステムは構成するコンポーネントが多くなりがちだ。仮想マシンやコンテナー、データベースのマネージドサービス、ロードバランサーなど、クラウドが提供する複数のサービスや機能を組み合わせて活用しているケースが多い。これらのコンポーネントのいずれかで不具合が発生すると、システム全体が利用できなくなる恐れがある。それぞれのきめ細かな監視はもちろん、依存関係を把握したうえで全体を監視する必要がある。
マイクロソフトが提供しているソリューションで、この役割を果たすのが「 Azure Monitor 」である。これは、クラウドやオンプレミス環境のサービスやアプリケーションを監視するためのクラウドサービスだ。それぞれのサービスおよびアプリケーションから各種データを収集・可視化・分析し、ユーザーが設定したしきい値を超えた場合にはアラートを発信したり、何らかのアクションを起こしたりする機能を備えている。アクションには、「Mail(電子メールを送信)」「Webhook(外部サービスにHTTPで通信)」「Runbook(ユーザーが指定したジョブを実行)」などを設定できる。
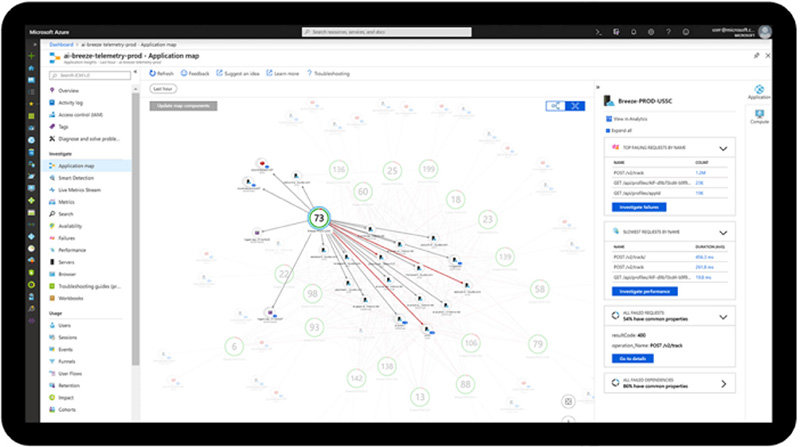
Azure Monitorはユーザーが指定したサービスからログ、メトリックを収集する。メトリックとは特定の時点におけるシステムの何らかの側面を表す数値のことだ。これらのデータは、ポータル画面で参照することができる。例えば、特定の仮想マシンを指定すると、パフォーマンスを示すグラフが表示される。このグラフをクリックすると、複数の統計情報を時系列で表示するグラフを確認できる。蓄積したログやメトリックをさまざまな切り口で検索できる機能も備えている。
加えて、アプリケーション視点でのきめ細かな分析を可能にする「 Application Insights 」というサービスも提供されている。これを利用すると、応答時間やページビュー数、ユーザー数、セッション数などの監視はもちろん、アプリケーションが依存する他のサービスとの関連を可視化し、その応答時間やエラーを詳細に把握できる。
真壁氏は、改めて「クラウドでは可観測性を担保することがまず検討すべき課題」だと前置きした上で次のように指摘する。
「オンプレミスの環境では、資産として保有するため、また、環境を自ら構築維持するする必要があるために運用管理ツールをまず「選定」することが重要な課題でした。これに対して、クラウドサービスとして提供されているツールは、従量課金なので気軽に試すことが可能です。自社のシステムに最適なツールを見つけるまで試行錯誤を重ねることができるわけです。その中でもAzure MonitorはAzureの各サービスに統合されているので、準備や初期作業の負担を軽くできます。Azureで可観測性の向上に取り組むのに、まずおすすめしたいサービスです」
※本記事は、日経 XTECH Special 「I&O リーダーが知っておくべき最新トレンド 未来を実現する IT インフラ」からの転載です。
ホームページに戻る