

サーバー製品に関する日本のお客様向け最新ブログ記事
※このポストは、 2019 年 10 月 31 日に投稿された Architecting petabyte-scale analytics by scaling out Postgres on Azure with the Citus extension に加筆および更新を行ったものです。
ペタバイトスケールの分析アーキテクチャ構築に向け、Azure 上の Postgres を Citus 拡張でスケールアウト
2019 年 10 月 31 日午後 1 時 12 分
数億人のユーザーを抱えるソフトウェアの次期アップデートを公開して良いのか、どう確認するのでしょうか。そのためには、まずデータを検討します。Windows の場合、多くのデータが検討対象になります。Windows チームは、8 億台の Windows デバイスから流れ込んでくるデータに基づく、20,000 種の診断メトリックを精査することで、新しいビルドの品質を測定しています。それと同時に、このチームは Windows アップデートのプレリリース バージョンを使用しているマイクロソフト エンジニアから寄せられたフィードバックを評価します。
マイクロソフトでは、Windows の診断メトリックをリアルタイム分析ダッシュボード「リリース品質ビュー (RQV)」に表示させています。社内の「リリース作業担当」チームは、新しい Windows アップデートがリリースされる前に毎回、このダッシュボードを使用して、カスタマー エクスペリエンスの品質を評価しています。マイクロソフトのお客様にとって Windows がどれだけ重要な製品であるかを考えたとき、その Windows を支える RQV 分析ダッシュボードは、Windows に関わるエンジニア、プログラム マネージャー、エグゼクティブにとって非常に重要なツールなのです。
このリアルタイム分析ダッシュボードは大いに活用されるのは当然のことです。マイクロソフトのプリンシパル エンジニアである Min Wei はこう述べています。「私たちは毎日数百人、毎月数千人のアクティブ ユーザーを抱えています。OS の新しいアップデートの提供は、ブロードウェイでショーを上演するようなものです。舞台裏では、非常に多くのスタッフが準備をしています。そして RQV 分析ダッシュボードのおかげで、開演時間に幕が上がり、観客の待ち望むショーをお届けするのです」
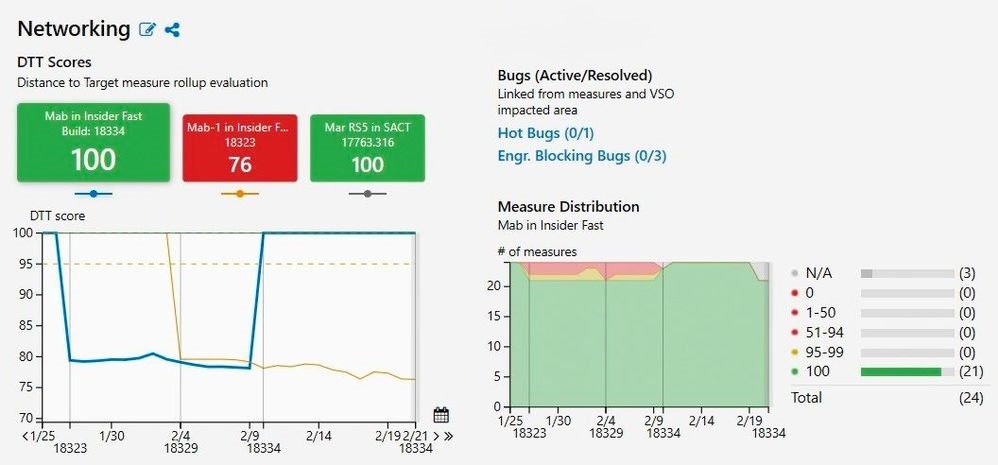
図 1: Windows のチームは、マイクロソフトの社内向け RQV 分析ダッシュボードで次期リリースの品質を評価している。RQV ダッシュボードでは 20,000 種の診断および品質管理用メトリックを追跡している。現在は 1 日あたり 600 万件以上のクエリ、数百人の同時ユーザーをサポート。このダッシュボードは Postgres を利用しており、Postgres の Citus 拡張を使って水平方向のスケールアウトを実現している。またこのダッシュボードは Microsoft Azure に展開されている。
データの「調理」に 2 日もかけるわけにはいかない
Windows のデータ & インテリジェンス チームはオンライン分析処理 (OLAP) のキューブ作成ワークロードにラムダ アーキテクチャを採用して、RQV 分析ダッシュボードを駆動させていました。「OLAP キューブの作成」はデータ サイエンティストやエンジニアが大量のデータから洞察を引き出すときによく利用する、多次元分析に関する用語です。(Postgres のようなデータベースを使った分析の話をするとき、開発者によっては「キューブの作成」ではなく、「ロールアップ」や「プリアグリゲーション」、「集計テーブル」という言葉を用いることがあります。呼び方はさまざまですが、考え方は同じです。ユーザーが特定の方法でクエリを実行することが分かっているなら、演算をあらかじめ済ましておくというのは理にかなったやり方です。)
残念ながら、データ & インテリジェンス チームが OLAP キューブの作成に利用していたアーキテクチャは、深刻な障害に行く手を阻まれました。「OLAP キューブの作成が順調に進まなくなってきたのです。私たちのチームでは毎日、MapReduce ジョブを通じて数億個のキューブを生成していました。しかしディメンションを追加するにつれ、『次元の呪い』に悩まされるようになったのです。一部のノードではメモリが使い果たされ、キューブ作成ジョブにかかる時間はどんどん伸びていきました」と Wei は言います。
キューブ作成が遅れる (ロールアップやレポート テーブルの作成が遅れる) ということは、Windows チームが必要な洞察を必要なときに得られないということを意味していました。Wei は次のように語っています。「データの『調理』 (すなわち準備) に24 ~ 48 時間かかっていました。そのため分析レポーティングが予定より 2 ~ 3 日遅れることもありました。こうした遅れによって、Windows のタイトなリリース スケジュールを守っていくことが難しくなりました」
ユーザーの要求に動的に応じるデータ分析手法—すなわち、「OLAP キューブの動的な作成」が必要
加速度的に増加する診断メトリックを前にして、Wei はただ追加のサーバーやハードウェアを展開するだけでは、キューブ作成問題を解決することができないと気づきました。いくら新しいサーバーを用意してリソースを追加しても、Windows のユーザー ベースの成長と、生成されるメトリック全体の増大には今に追いつかなくなることが目に見えていました。
Wei はサーバーをさらに増やすのではなく、動的キューブの作成という道を模索することにしました。「私たちは数億個の OLAP キューブを作成していましたが、多くの場合、ユーザーがダッシュボードに必要としていたのは、OLAP キューブの小さなサブセットに限られていました」と Wei は言います。「ユーザーが必要としているキューブのみを必要に応じて動的に生成すれば、パフォーマンス問題に対応できるのではないかと考えました」
ここで Wei が気づいたのは、動的 OLAP キューブ作成に求められるスケールと性能を実現するためには、新しいタイプのデータベースが必要になるということでした。また Wei の考えでは、そのような新しいデータベースは、データの持続性向上にも役立てられるべきでした。「2 年もすれば、このデータモデルが人々に理解されるようになるでしょう」 Wei は言います。
「次元の呪い」に対処できる分析ダッシュボード用データベースの発見
Wei はさまざまなデータベースの評価に取りかかり、Apache Pinot や Apache Kylin、Apache Druid といったオープンソースのデータベースも検討しました。しかしそれらのデータベースには SQL のサポートが制限されていたり、拡張データ型に対応していないなどの制約がありました。またこれらのデータベースは、大規模な RQV 分析ダッシュボードの駆動に求められる同時実行クエリのパフォーマンスを実現することができず、間違ったデータを修正するための更新にも非対応でした。
Wei はリレーショナル データベース管理システム (RDBMS) なら、上記の数種のデータベースが抱える欠点を克服できるということに気がつきました。とりわけ重要なのは、RDBMS は動的キューブの作成に必要な性能を実現できると同時に、データ持続性の要件も満たせるという点でした。「RDBMS の構築もしくは購入に向けて、決意が固まりました」と Wei は言います。
適切な RDBMS を探し始めた Wei は、水平分散型のリレーショナル データベースが最も妥当な選択であるとわかりました。「個々のサーバーに 10 TBのメモリが搭載される日は、まだ当分やって来ないでしょう」と Wei は語ります。「少なくとも向こう 10 年の間は、分散メモリ型アーキテクチャが最適な選択となるはずです」
また RDBMS による OLAP キューブの作成について、Wei はロールアップ方式のデータ集計によって、急速に増大しているデータ量が圧縮されるという方式を求めていました。「Windows の診断機能によって、毎日数百億行のデータが生成されています。追加しかできないデータストアの場合、その百億行が蓄積していくことになるのです」と Wei は言います。「私はロールアップを使って、一種の『意味的圧縮』を実現し、データベース内のデータ量を削減したいと思いました」
また Wei は、インデクシング機能とトランザクションの「UPSERT (挿入 + 更新)」機能を必要としていました。さらに、JSON や キーバリュー型、HyperLogLog (HLL) 、t-digest などの拡張データ型に対応していることも求めていました。Wei はまったく新しい分散データベースの構築すら検討しましたが、その実装は長期のプロジェクトになることがわかりました。「もし本当にやるなら最上部にデータベース エンジンを構築する必要がありますが、1 人の人間が 1 年という期日の中で達成することを考えると、そのアプローチには無理があると分かりました」と Wei は振り返ります。
「分散型の PostgreSQL は革命的な手法です」
—Min Wei、マイクロソフト プリンシパル エンジニア
帰宅中にカンファレンス発表の録音を聴き、Postgres のオープンソース拡張「Citus」を発見
適切なデータベースを探し続けていた Wei は、ある日、Citus というPostgres のオープンソース拡張を発見しました。それは PostgreSQL のスケールアウトに関するビデオに、耳を傾けていたときのことでした。ビデオ内のプレゼンテーションは、Citus Data のプリンシパル エンジニアである Marco Slot が、パリで開かれた dotScale 2017 で行ったものでした。「Citus が分散型の SQL プラットフォームであり、私たちの要件に対応できるということを知りました」と Wei は語ります。「是非とも Citus について調べなければ、と思いました」.
Wei は Postgres の Citus 拡張を検証するため、プロトタイプの構築に取りかかりました。「プロトタイプの構築時、私は Postgres を学習中でした。その時点では Postgres を使った運用経験がほとんどなく、頼る相手もいませんでした。私は数百種のパラメーターをいじってみたり、AB テストを行ったりしました」と Wei は言います。「そして Citus がサポートするパーティション分割、インデックスオンリー スキャン、部分インデックスなどを試してみた結果、Citus を使えばいろいろな問題が解決できることが分かりました」
Postgres と Citus 拡張がオープンソースである点も重要でした。「データ & インテリジェンス チームでは、データが最も大事な資産でした」と Wei は言います。「Postgres と Citus のような人気のあるデータベース プラットフォームを使っていれば、現在の開発者たちが引退するころになってもなお、コードは生き続けるに違いないと思えました。そのため、このアーキテクチャは時の試練に耐えるだろうという確信を持つことができました」
初期の結果に手応えを感じた Wei は、概念実証段階だったプロジェクトを正式なものに移行しました。「私は Microsoft Azure チームに働きかけ始め、分散 RDBMS が必要だと伝えました」と Wei は振り返ります。「数か月後、マイクロソフトが Citus Data を買収したと知って、とてもうれしかったです」
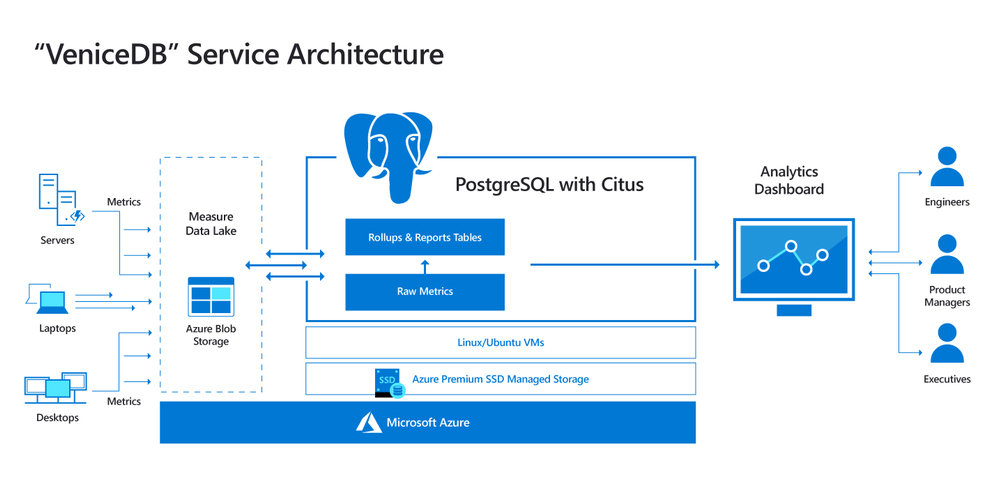
図 2: Windows チームではリリース作業の意思決定に、オープンソースの Postgres データベースを利用したアーキテクチャを採用し、Citus を使って Postgres を水平方向にスケールアウトさせている。「VeniceDB (コードネーム)」システムは 8 億台以上のデバイスから 20,000 種以上のメトリックを収集する。未加工の Windows イベントデータやステージングキューのために 1.5 PB (ペタバイト) 分の Azure Blob Storage を利用。Citus データベースクラスターには 44 のノードが含まれ、全体としてのコア数は 2,816、メモリは 18.7 TB、SSD ストレージはなんと 1.5 PB (ペタバイト) にも上る。
Microsoft Azure 上に Citus データベース クラスターを構築
新たに利用するデータベースとして Postgres を選択した Wei は、Citus を使って Postgres を Microsoft Azure 上で水平方向にスケールアウトさせています。またその際には、Ubuntu/Linux 仮想マシンを活用しています (Wei のシステムは「VeniceDB」というコードネームで呼ばれています)。VeniceDB システムには 2 つの Citus データベース クラスターが含まれており、どちらのクラスターも RQV 分析ダッシュボードおよび関連 API にサービスを提供しています。
それぞれの Citus クラスターには現在、22 のノード (合計 44 ノード) が含まれており、2 つのクラスターを合わせるとコア数は 2,816、メモリは 18.7 TBに達しています。Wei は Azure Premium SSD Managed Disks をなんと 1.5 PB (ペタバイト) 分もデータベースのために利用しています。またそれとは別に、さらに 1.5 PB 分の Azure Blob Storage をステージング キューや未加工の Windows イベント データのために使っています。
上で紹介したのは、あくまで現在のノード数です。Wei は今年中に Citus データベース クラスターをアップグレードし、さらにノードやリソースを追加する予定です。
Wei と彼のチームが Postgres と Citus の実稼働を Azure 上で開始したのは、Citus が Azure Database for PostgreSQL の組み込み機能として統合される以前のことでした。そのため、彼らは Postgres データベースと Citus 拡張を一からすべて自分で管理する必要がありました。
幸いなことに現在では、Postgres のために利用するクラウド データベースを検討中の新規ユーザーに向けて、マイクロソフトはフルマネージドのデータベースを Postgres 向けのサービスとして提供しています。さらに Azure Database for PostgreSQL には、展開オプションとして、Citusが組み込まれました。このオプションは Hyperscale (Citus) と呼ばれています。
Postgres のオープンソース拡張である Citus のほかにも、Wei はいくつかの Postgres 拡張を利用しています。例えば、彼は ‘postgresql-topn’ を使ってデータ内で頻繁に現れるアイテムの上位を抽出したり、‘pg_cron’ を使ってデータベース タスクのスケジューリングを行ったりしています。さらに ‘intarray’ で NULL の含まれていない整数配列を操作し、‘postgresql-hll’ で HyperLogLog データ構造をネイティブのデータ型として扱えるようにしています。
また、Wei のチームは Postgres をそれなりの頻度でアップグレードしてきました。「VeniceDB」システムは Postgres 10 を使って立ち上げられましたが、現在実稼働中の Citus データベース クラスターでは、Postgres 11.5 が動作しています。さらに Wei は Postgres 12 と Citus 9.x を使ったテストにも着手しています。Wei はこう言っています。「Postgres と Citus はこの 2 年間で改良されてきました。私にはそれが分かります」
「数百人の同時ユーザーと毎日 600 万件以上のクエリに対応可能です。Citus のおかげで、75% のクエリに対する応答時間は 200 ミリ秒以下となっています」
—Min Wei、マイクロソフト プリンシパル エンジニア
超低遅延の応答時間で、分析ダッシュボードの 1日 600 万件以上のクエリを支える
Postgres の Citus 拡張を使い Postgres をスケールアウトすることで、Wei のチームは Windows 診断テストやユーザー フィードバックから生まれる大規模なデータ セットの取り込みに必要な I/O 性能を実現できるようになりました。「この RQV 分析のユースケースでは、書き込み処理を非常に多用します」と Wei は言います。「私たちは毎日 8 ~ 10 TB のデータを Postgres データベースに取り込んでいます。また規制要件の関係で、毎日同じくらいのデータを削除しています」
また、このシステムは読み込み処理も非常に多用します。めったに読み込まれない「死んだ」データを 5 TB 程度保存しているだけのデータベースとは違い、Wei のシステムの場合、RQV 分析ダッシュボードのデータを使用するユーザーは、最大 200 TB の診断データのクエリを絶え間なく実行しています。
「数百人の同時ユーザー、毎日 600 万件以上のクエリに対応可能です」と Wei は言います。「ダッシュボードは、場合によっては 20 ~ 25 分ごとに更新されます。そのため、このデータベースは 150 ~ 200 TB のデータを毎日数百回ずつ読み込まなければならないのです。Citus のおかげで、75% のクエリに対する応答時間は 200 ミリ秒以下に収まっています。一部の種類のクエリの場合、75% の応答時間は 90 ミリ秒以下です。片方の Citus クラスターでは、95% のクエリに対する応答時間が 1 秒以下となっています。もう一方の Citus クラスターでも、3 秒以下に収まっています」
Citus 拡張により Postgres を Azure上 でスケールアウト—動的な OLAP キューブ作成を支援
Citus を使用し Postgres を多数のノードにスケールアウトさせることで、Wei のチームはより多くのメモリと計算資源を利用可能となり、さらに Citus が提供する大規模な並列処理の恩恵も受けられるようになりました。その結果、Wei は動的な OLAP キューブ作成とロールアップ作成に求められる性能および応答時間を達成できています。しかも Citus を利用することで、Wei のチームはキューブ/ロールアップの計算を新しいデータがやってくるたびインクリメンタルに実行できるようになっています。
「分散型の PostgreSQL は革新的な手法です」と Wei は語ります。「Azure 上の Citus のおかげで、OLAP キューブをオンデマンドで作成できています」
新しいデータを「調理」しダッシュボードに追加するまでに、もう 2 ~ 3 日もかかることはありません。「Windows の品質に関する最新のデータを RQV 分析ダッシュボードのユーザーの手元まで、確実に届けられるようになりました」と Wei は言います。「そのため、ダッシュボードのユーザーはタイトなリリース スケジュールを守りながら、製品の品質を高めることができています」
「Citus はペタバイトスケールの Postgres データベースであり、大規模なエグゼクティブ向け分析ダッシュボードの駆動が可能で、数百件の同時実行クエリに対応しています。Citus とPostgres を Azure 上で合わせて使うという手法は、マイクロソフトの社内チームにとって適切なアプローチでした—これは他の多くの組織にとっても適切なアプローチであると確信しています」
—Min Wei、マイクロソフト プリンシパル エンジニア
大規模な並列トランザクションを管理
エンジニアその他のチームメンバーは、RQV 分析ダッシュボードを使って Windows のリリース作業に関する重要な意思決定を行っています。そのため、データベース内のデータは正確でなくてはなりません。しかし、ダッシュボードの基盤となるデータベースに、誤って不適切なデータが入り込んだらどうなるでしょうか。Wei は PostgresOpen 2018 に登壇した際、このようなケースについて語り、自身がリアルタイム分析データベースを構築したときの教訓を共有しました。
「時には間違ったデータを取り込んでしまうこともあります。そのエラーを修正するために、多大なコストを強いられる場合もあります」と Wei は言っています。「ある時などは、約 2 週間分もの不適切なデータを取り込んでしまいました。とにかくおかしい列が、1 列あったのです。私はどうしようもない状況に陥ったと思いました。テーブルを削除するなら 7 日はかかると知っていたからです。しかし私はそのとき、これは Postgres なのだから更新を行えるのだということに気がつきました。Citus は分散型システムという性質を持っているため、更新は速やかに実行可能でした。そこで私はある週末に作業を行うことにしました。週末はクエリの件数が少ないからです。Postgres と Citus のおかげで、260 億行の更新をたった 10 時間で実行できました。これには本当に驚かされました。データの更新によるデータ精度の向上という点において、ほかの分散データベースにはこのレベルの能力などとても望めません」
ペタバイトスケールのデータベースを Azure 上の Citus でサポート
Wei は Citus による Postgres のスケールアウトを心から勧めています。「一部の組織では、大規模なデータ ウェアハウスが必要なときに、データ レイクを構築しています。しかしその代わりに私が勧めるのは、Citus の利用を本気で検討することです」と Wei は言います。「Citus はペタバイトスケールの Postgres データベースであり、大規模なエグゼクティブ向け分析ダッシュボードの駆動が可能で、数百件の同時実行クエリに対応しています。Citus と Postgres を Azure 上で合わせて使うという手法は、マイクロソフトの社内チームにとって適切なアプローチでした—これは他の多くの組織にとっても適切なアプローチであると確信しています」
Citus は Azure Database for PostgreSQL で展開オプションとして組み込まれ、利用可能となりました (このオプションは Hyperscale (Citus) と呼ばれています)。そのためユーザーは、Wei と Windows データ & インテリジェンス チームが実行したのとまったく同じように、Postgres を Microsoft Azure 上で水平方向にスケールアウトさせられるようになっています。しかもデータベースを管理するために、貴重なエンジニアリング サイクルを費やす必要はありません。
**********
このストーリーの執筆にレビュー、編集、その他の協力していただいた、Min Wei、Teresa Giacomini、Greg Thomas、Marco Slot、Jose Miguel Parrella、Craig Kerstiens、Samay Sharma、Umur Cubukcu に深甚なる感謝の意を表します 。
ブログ記事一覧
- SQL Server を Azure Virtual Machines に独自にインストールする場合は、リソース プロバイダーにご登録ください (2019-07-08)
- Azure Sentinel — 防御者を支援するクラウドネイティブの SIEM が一般提供開始 (2019-09-24)
- すべての開発者がマイクロサービス アプリケーションをより簡単に構築できるようにするためのオープン ソース プロジェクト、Dapr (Distributed Application Runtime) の発表 (2019-10-16)
- アプリケーションを Azure にリフトアンドシフトするエンドツーエンドの手順 (2019-10-21)
- SQL VM リソース プロバイダーへの一括登録 (2019-10-25)
- SQL Server の高可用性と災害復旧に関する新しい特典 (2019-10-30)
- SQL Server ビッグ データ クラスターの HDFS 階層化機能でデータ レイクを統合 (2019-10-31)
- ペタバイトスケールの分析アーキテクチャ構築に向け、Azure 上の Postgres を Citus拡張でスケールアウト (2019-10-31)
- SQL Server 2019 の一般提供を開始 (2019-11-04)
- データに関するインテリジェンスをもたらす SQL Server 2019 の一般提供を開始 (2019-11-04)
※本情報の内容 (添付文書、リンク先などを含む) は、作成日時点でのものであり、予告なく変更される場合があります。