

As self-service becomes the first stop in contact centers, AI agents now define the frontline customer experience. Modern customer interactions span voice, text, and visual channels, where meaning is shaped not only by what is said, but by how it’s said, when it’s said, and the context surrounding it.
In customer service, this is even more pronounced-customers reaching out for support don’t just convey information. They convey intent, sentiment, urgency, and emotion, often simultaneously across modalities; a pause or interruption on a voice call signals frustration, blurred document image leads to downstream reasoning failures, and flat or fragmented response erodes trust-even if the answer is correct In our previous blog post, we reflected on the evolution of contact centers from scripted interactions to AI-driven experiences. As contact center landscape continues to change, the way we evaluate AI agents must change with them. Traditional approaches fall short by focusing on isolated metrics or single modalities, rather than the end-to-end customer experience.
Contact centers struggle to reliably assess whether their AI agents are improving over time or across architectures, channels, and deployments. While cloud services rely on absolute measures like availability, reliability and latency, AI agent evaluation today remains fragmented, relative, and modality specific. What would be useful is an absolute, normalized measure of end-to-end conversational quality- one that reflects how customers actually experience interactions and answers the fundamental question: Is this agent good at handling real customer conversations?
Introducing the Multimodal Agent Score (MAS)
MAS is built on the observation that every service interaction- whether human-to-human or human-to-agent- naturally progresses through three fundamental stages: (explored in more detail here: Measuring What Matters: Redefining Excellence for AI Agents in the Contact Center )
- Understanding the input – accurately capturing and interpreting what the customer is saying, including intent, context, and signals such as urgency or emotion.
- Reasoning over that input – determining the appropriate actions, managing context across turns, and deciding how to resolve the issue responsibly.
- Responding effectively – delivering clear, natural, and confident resolution in the right tone and format.
Multimodal Agent Score directly mirrors these stages. It is a weighted composite score (0-100) designed to assess end-to-end AI agent quality across modalities- voice, text, and visual- aligned to how real conversations naturally unfold.
MAS Dimensions and Parameters
| Conversation Stage | MAS Quality Dimension | What It Measures | Example Parameters |
| Understanding | Agent Understanding Quality | how well the agent hears and understands the user (e.g., latency, interruptions, speech recognition accuracy) | Intent-determination, Interruption, missed window |
| Reasoning | Agent Reasoning Quality | how well the agent interprets intent and resolves the user’s request | Intent-resolution, acknowledgement |
| Response | Agent Response Quality | how well the agent responds, including tone, sentiment, and expressiveness | CSAT, Tone stability |
Computing each MAS score:
MAS is computed as a weighted aggregation of three quality dimensions stated in the table above.
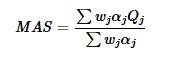
where:
- Qj represents one of the three quality dimensions: Agent Understanding Quality (AUQ), Agent Reasoning Quality (ARQ), Agent Response Quality (AReQ)
- wj represent the costs or weights of each dimension
- αj captures the a priori probability of the respective dimension
Computing each MAS dimension:
Computing each MAS dimension (AUQ, ARQ, AReQ) involves aggregating underlying parameters into a single weighted score. Raw measurements (such as interruption, intent determination, or tone stability) are first normalized into a 0–1 score before aggregating them at the dimension level. We apply a linear normalization function clipping each raw measurement at predefined thresholds suitable for the parameter being measured (for example, maximum allowed interruption or minimum required accuracy). This maintains the sensitivity of each parameter in the relevant effective range and avoids the negative impact of measurement outliers, making MAS an absolute measure of agent quality.
MAS in Practice: Voice Agent Evaluation Example
To ground MAS in real-world conditions, we evaluated ~2,000 synthetic voice conversations across two agent configurations using identical prompts and scenarios:
- Agent-1: Chained voice agent using a three-stage ASR–LLM–TTS pipeline
- Agent-2: Real-time voice agent using direct speech-to-speech architecture
The evaluation dataset included noise, interruptions, accessibility effects, and vocal variability to simulate production environments.
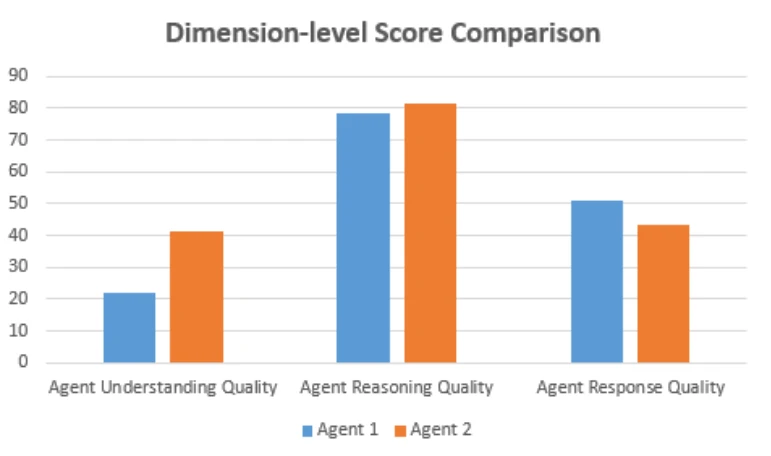
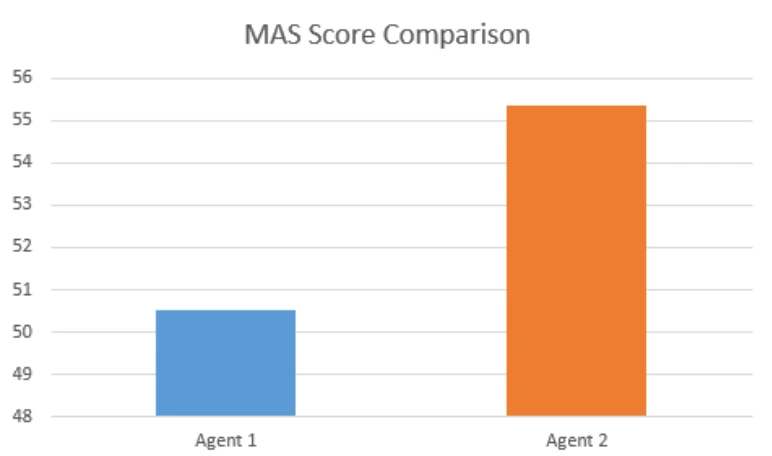
Shown below is a comparison of core MAS metrics, including dimension-level scores and the overall MAS score.
Voice Evaluation Results (Excerpt)
| Dimension | Parameters | Agent-1 | Agent-2 |
| AUQ | Interruption Rate (%) | 0.045 | 0.025 |
| AUQ | Missed Response Windows | 0.00045 | 0.0015 |
| ARQ | Intent Resolution | 0.13 | 0.08 |
| ARQ | Acknowledgement Quality | 0.08 | 0.10 |
| AReQ | CSAT | 0.128 | 0.126 |
| AReQ | Tone stability | 0.16 | 0.14 |
Key Observations
MAS provides flexibility to surface quality insights at an aggregate level, while enabling deeper analysis at the individual parameter level. To better understand performance outliers and anomalous behaviors, we went beyond composite scores and analyzed agent quality at the individual parameter level. This deeper inspection allowed us to attribute observed degradations to specific factors: Example:
- Channel quality matters: Communication channels introduce multiple challenge such as latency, interruptions, compression and loss of information, penalizing recognition and response quality.
- Turn-taking quality is critical: Missed windows and interruptions strongly correlate with abandonment.
- Tone and coherence matter: Cleaner audio and uninterrupted responses lead to higher acknowledgement and perceived empathy.
- MAS reveals root causes: Differences in scores clearly distinguish understanding, reasoning, and response failures-something single metrics cannot do.
Looking Forward
We will continue to refine and evolve MAS as we validate it against real-world deployments and business outcomes. As the Dynamics 365 Contact Center team, we aim to establish MAS as our quality benchmark for evaluating AI agents across channels. Over time, we also intend to make MAS broadly available, extensible, and pluggable, enabling organizations to adapt it, to evaluate their contact center agents across modalities. For readers interested in the underlying methodology and mathematical foundations, a detailed research paper will be published separately.



