
Makine çevirisi
What is machine translation?
Makine çeviri sistemleri, büyük miktarda metni ve desteklenen dillerinden herhangi birini çevirmek için makine öğrenme teknolojilerini kullanan uygulamalar veya çevrimiçi hizmetlerdir. Hizmet, "kaynak" metnini bir dilden farklı bir "hedef" diline çevirir.
Makine çevirisi teknolojisinin ve arabirimlerin arkasındaki kavramlar nispeten basitse de, arkasındaki bilim ve teknolojiler son derece karmaşıktır ve özellikle derin öğrenme ( yapay zeka), büyük veri, Linguistics, bulut bilgi işlem ve Web API 'leri.
Erken 2010 yılından bu yana, yeni bir yapay zeka teknolojisi, derin sinir ağları (aka derin öğrenme), konuşma tanıma teknolojisi ile konuşma tanıma birleştirmek için Microsoft çevirmen ekibi izin kalite düzeyine ulaşmak için izin verdi çekirdek metin çeviri teknolojisi yeni bir konuşma çeviri teknolojisi başlatmak için.
Tarihsel olarak, sektörde kullanılan birincil makine öğrenme tekniği istatistiksel makine çevirisi (SMT) oldu. Smt birkaç kelime bağlamında verilen bir kelime için mümkün olan en iyi çevirileri tahmin etmek için gelişmiş istatistiksel analiz kullanır. Smt, Microsoft dahil olmak üzere tüm büyük çeviri hizmet sağlayıcıları tarafından 2000 ' lerin ortalarında beri kullanılmıştır.
Nöral makine çeviri (NMT) gelişi, çok daha yüksek kalitede Çeviriler sonuçlanan, çeviri teknolojisindeki radikal bir vardiya neden oldu. Bu çeviri teknolojisi, kullanıcılar ve geliştiriciler için dağıtmaya başladı 2016 ikinci bölümü.
Hem smt hem de NMT çeviri teknolojilerinde ortak iki unsur vardır:
- Her ikisi de sistemleri eğitmek için (çevrilmiş cümleler milyonlarca kadar) öncesi insan tercüme içeriği büyük miktarda gerektirir.
- Ne iki dilli sözlükler, olası tercümeleri listesine dayalı sözcükleri tercüme, ancak bir cümle içinde kullanılan sözcüğün bağlamında dayalı tercüme hareket.
Çevirmen Nedir?
Çevirmen ve Konuşma hizmetleri, Bilişsel hizmetler API topluluğu, Microsoft 'un makine çeviri hizmetlerinden biridir.
Metin çevirisi
Translator, 2007'den beri Microsoft grupları tarafından kullanılmaktadır ve 2011'den beri müşteriler için API olarak kullanılabilir. Çevirmen, Microsoft'ta yaygın olarak kullanılır. Ürün yerelleştirme, destek ve çevrimiçi iletişim ekiplerine dahil edilir. Aynı hizmete, ek bir ücret ödemeden, Bing, Cortana, Microsoft Edge, Office, Sharepoint, Skypeve Yammer.
Çevirmen, herhangi bir donanım platformunda ve herhangi bir işletim sisteminde dil çevirisi ve dil algılama, metinden konuşmaya veya sözlük gibi dille ilgili diğer işlemleri gerçekleştirmek için web veya istemci uygulamalarında kullanılabilir.
Endüstri standardı Rest teknolojisi yararlanarak, geliştirici kaynak metin (veya sesli konuşma çevirisi için) hizmeti hedef dili gösteren bir parametre ile gönderir ve hizmetin kullanılacak istemci veya Web uygulaması için çevrilmiş metni geri gönderir.
Translator hizmeti, Microsoft veri merkezlerinde barındırılan bir Azure hizmetidir ve diğer Microsoft bulut hizmetlerinin de aldığı güvenlik, ölçeklenebilirlik, güvenilirlik ve kesintisiz kullanılabilirlik avantajlarından yararlanır.
Konuşma çevirisi
Çevirmen konuşma çevirisi teknolojisi Skype Translator ile başlayarak 2014'ün sonlarında başlatıldı ve 2016'nın başından beri müşteriler için açık bir API olarak kullanılabilir. Microsoft Translator canlı özelliğine, Skype'a, Skype toplantı yayınına ve Android ve iOS için Microsoft Translator uygulamalarına entegre edilmiştir.
Konuşma çevirisi artık Microsoft Speech, konuşma tanıma, konuşma çevirisi ve konuşma sentezini (metin-konuşma) için tam olarak özelleştirilebilir hizmetlerin uçtan uca kümesi aracılığıyla kullanılabilir.
Metin çevirisi nasıl çalışır?
Metin çevirisi için kullanılan iki ana teknoloji vardır: eski bir, istatistiksel makine çevirisi (SMT) ve yeni nesil bir, neural makine çevirisi (NMT).
İstatistiksel makine çevirisi
Çevirmenin İstatistiksel Makine Çevirisi (SMT) uygulaması, Microsoft'ta on yıldan fazla bir süredir yapılan doğal dil araştırmaları üzerine kurulmuştur. Modern çeviri sistemleri, diller arasında çevirmek için el yapımı kurallar yazmak yerine, çeviriye, metnin diller arasındaki dönüşümlerini mevcut insan çevirilerinden öğrenme ve uygulamalı istatistik ve makine öğrenimindeki son gelişmelerden yararlanma sorunu olarak yaklaşır.
Sözde "paralel corpora" büyük oranlarda modern bir Rosetta Stone olarak hareket, birçok dil çiftleri ve etki alanları için bağlam içinde kelime, ifade ve deyimsel çeviriler sağlayan. İstatistiksel modelleme teknikleri ve verimli algoritmalar bilgisayarın deşifre etme (eğitim verilerindeki kaynak ve hedef dil arasındaki yazışmaları algılama) ve kod çözme (yeni bir giriş cümlesinin en iyi çevirisini bulma) sorununu çözmesine yardımcı olur. Çevirmen, istatistiksel yöntemlerin gücünü daha iyi genelleştiren ve daha anlaşılır çevirilere yol açan modeller üretmek için dilsel bilgilerle birleştirir.
Sözlükler veya dilbilgisi kurallarına güvenmez bu yaklaşım nedeniyle, tek kelime çevirileri gerçekleştirmeye çalışırken karşı belirli bir sözcük etrafında bağlamı kullanabilirsiniz tümceciklerin en iyi çevirileri sağlar. Tek kelime çeviriler için, iki dilli sözlük geliştirilmiştir ve aracılığıyla erişilebilir www.Bing.com/Translator.
Nöral makine çevirisi
Çeviride sürekli iyileştirmeler önemlidir. Ancak, performans iyileştirmeleri 2010'ların ortalarından beri SMT teknolojisi ile platoed var. Microsoft'un AI süper bilgisayarının, özellikle de Microsoft Cognitive Toolkit'in ölçeğini ve gücünü katarak, Çevirmen artık sinirsel ağ (LSTM) çeviri kalite geliştirme yeni bir on yıl sağlayan çeviri tabanlı.
Bu sinirsel ağ modelleri, Azure'daki Konuşma hizmeti aracılığıyla ve 'generalnn' kategori kimliği kullanılarak metin API'si aracılığıyla tüm konuşma dilleri için kullanılabilir.
Neural ağ çevirileri temelde nasıl geleneksel smt olanlar karşılaştırıldığında gerçekleştirilir farklıdır.
Aşağıdaki animasyon çeşitli adımlar neural ağ çevirileri bir cümle çevirmek için geçer gösterir. Bu yaklaşım nedeniyle, çeviri bağlam içine tam cümle, sadece birkaç kelime smt teknoloji kullanır ve daha fazla sıvı ve insan tercüme görünümlü Çeviriler üretecek kayan pencere karşı alacaktır.
Sinirsel ağ eğitimine dayanarak, her kelime, belirli bir dil çifti (örn. İngilizce ve Çince) içinde benzersiz özelliklerini temsil eden 500 boyutlu Vektörlü (a) boyunca kodlanmış. Eğitim için kullanılan dil çiftlerine dayanarak, neural ağ bu boyutların ne olması gerektiğini kendi kendine tanımlayacaktır. Cinsiyeti gibi basit kavramları kodlayabiliyorlar (feminen, erkeksi, nötr), nezaket düzeyi (Argo, Casual, yazılı, resmi, vb), kelime türü (fiil, noun, vb), aynı zamanda eğitim verileri türetildiği gibi diğer olmayan belirgin özellikleri.
Neural ağ çevirileri adımları aşağıdaki gibi geçer:
- Her sözcük veya daha özellikle 500-Boyut vektörünü temsil eden, bir 1000-boyut vektör (b) tümceyi diğer sözcüklerin bağlamında sözcüğü temsil eden bir "neurons" ilk katmanı geçer.
- Bir kez tüm kelimeler bu 1000-boyut vektörler içine bir kez kodlanmış, süreç birkaç kez yinelenir, her katman daha iyi ince-bu 1000-tam cümle bağlamında sözcüğün boyut gösterimi-ayar izin (SMT aksine sadece 3 ila 5 kelime pencere dikkate alabilir teknoloji)
- Son çıkış matriks daha sonra dikkat katmanı (yani bir yazılım algoritması) bu son çıkış matrisi hem de daha önce çevrilmiş sözcüklerin hangi sözcüğü, kaynak cümle, sonraki tercüme edilmelidir tanımlamak için kullanacak kullanılacak. Bu hesaplamalar, potansiyel olarak gereksiz sözcükleri hedef dilde bırakmak için de kullanılır.
- Kod çözücü (çeviri) katmanı, seçili sözcüğü (veya daha özel olarak bu sözcüğü tam tümceyi içeriğindeki temsil eden 1000 boyut vektörünün) en uygun hedef dil eşdeğeri olarak çevirir. Bu son katman (c) çıktısı daha sonra kaynak cümlenin hangi sonraki sözcüğün çevrilmesi gerektiğini hesaplamak için dikkat katmanına geri beslenir.

Animasyonda tasvir örnekte, bağlam duyarlı 1000-boyut modeli "olan"Bu isim (House) Fransızca kadınsı bir kelime (La Maison). Bu uygun tercüme izin verecektir "olan"olmak"La"ve değil"Le"(tekil, erkek) veya"Les"(çoğul) kod çözücü (çeviri) katmanına ulaştığında.
Dikkat algoritması da, daha önce (Bu durumda "tercüme Word (s) dayanarak, hesaplayacakolan"), bir sonraki kelimenin tercüme edilmesi konu olmalıdır ("House") ve bir sıfatı değil ("Mavi"). Sistem İngilizce ve Fransızca cümleler bu kelimelerin sırasını tersine çevirmek öğrendim çünkü bu elde edebilirsiniz. Aynı zamanda, Eğer sıfatın "Büyük"bir renk yerine, onları tersine çevirmek olmamalıdır ("büyük ev"= >"La Grande Maison").
Bu yaklaşım sayesinde, son çıkış, çoğu durumda, daha akıcı ve daha yakın bir SMT tabanlı çeviri daha bir insan tercüme daha hiç olabilirdi.
Konuşma çevirisi nasıl çalışır?
Çevirmen aynı zamanda konuşmayı çevirebiliyor. Bu teknoloji Translator canlı özelliğinde ortaya çıkmıştır (http://translate.it), çevirmen uygulamaları, Skype Translator ve ayrıca başlangıçta yalnızca Skype Translator özelliği ve iOS ve Android 'de Microsoft Translator uygulamalarında kullanılabilir hale gelmiştir, bu işlevsellik artık açık olan en son sürümü ile geliştiriciler tarafından kullanılabilir REST tabanlı API Azure portalında kullanılabilir.
Mevcut teknoloji tuğla bir konuşma çeviri teknolojisi oluşturmak için ilk bakışta bir düz ileri süreci gibi görünebilir rağmen, sadece mevcut bir "geleneksel" insan-to-Machine konuşma tanıma takmadan çok daha fazla çalışma gerekli mevcut metin çevirisi bir motor.
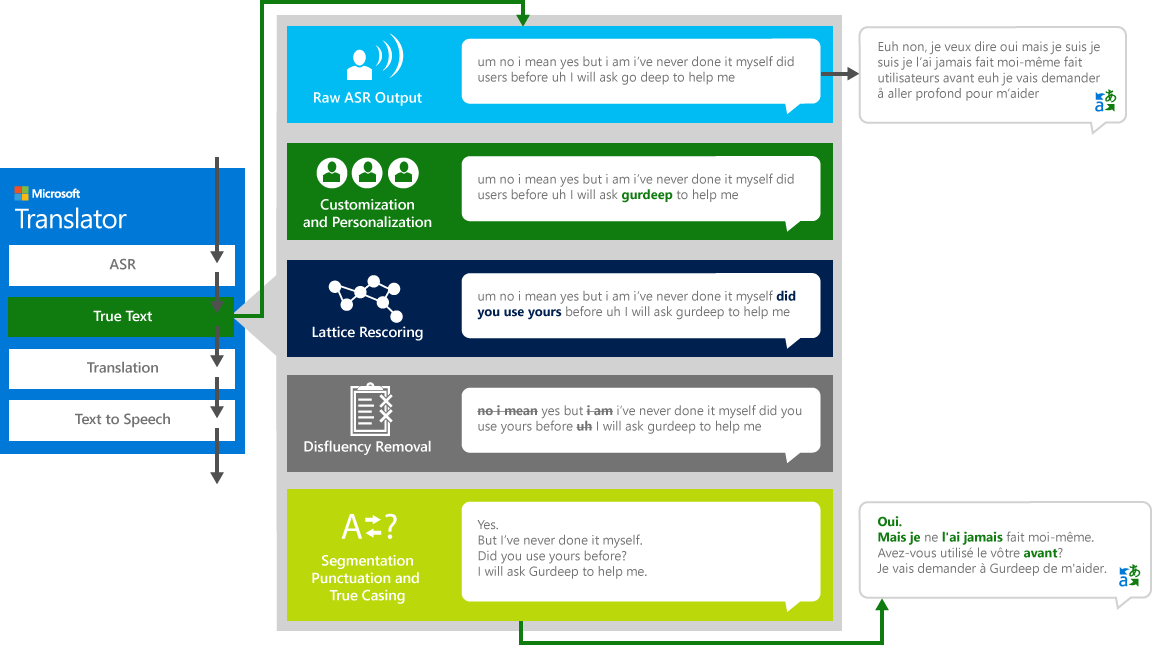
"kaynak" konuşmasını bir dilden farklı bir "hedef" diline doğru çevirmek için, sistem dört adımlı bir işlemden geçer.
- Konuşma tanıma, sesi metne dönüştürmek için
- TrueText: metni daha fazla tercüme için uygun hale getirmek üzere normalleştirir bir Microsoft teknolojisi
- Yukarıda açıklanan metin çeviri motoru ile çeviri, gerçek hayat konuşulan konuşmalar için özel olarak geliştirilen çeviri modelleri
- Metin-to-Speech, gerektiğinde, çevrilmiş ses üretmek için.

Otomatik konuşma tanıma (ASR)
Otomatik konuşma tanıma (ASR), binlerce saatlik gelen ses konuşmasını çözümleme konusunda eğitimli bir neural ağ (nn) sistemi kullanılarak gerçekleştirilir. Bu model, normal sohbetler için optimize edilmiş konuşma tanıma üreten, insan-to-Machine komutları yerine insan-insan etkileşimleri üzerinde eğitim görmektedir. Bunu başarmak için, çok daha fazla veri yanı sıra geleneksel insan-to-Machine ASRS daha büyük bir DNN gereklidir.
Hakkında daha fazla bilgi edinin Microsoft 'un metin hizmetlerine konuşma.
DoğruMetin
İnsanlar diğer insanlarla konuşan gibi, biz çok iyi, açık ya da düzgün olarak biz genellikle düşünüyoruz gibi konuşmayın. TrueText teknolojisiyle, literal metin, "um" s, "Ah" s, "ve" s, "gibi" s, stutters ve tekrarlar gibi konuşma disfluetlerini (dolgu sözcükleri) kaldırarak Kullanıcı amacını daha yakından yansıtacak şekilde dönüştürülür. Metin Ayrıca, cümle sonları, uygun noktalama işaretleri ve büyük harfe çevirme ekleyerek daha okunabilir ve çevrilebilir hale gelmiştir. Bu sonuçları elde etmek için, biz dil teknolojileri üzerinde çalışma yıllar kullandık, biz trueText oluşturmak için çevirmen geliştirdi. Aşağıdaki diyagram, gerçek yaşam örneği ile çeşitli dönüştürme trueText bu değişmez metin normalleştirmek için çalışır gösterir.
Çeviri
Metin daha sonra herhangi bir çevrilir diller ve lehçeler Translator tarafından desteklenir.
Speech Translation API (Geliştirici olarak) veya konuşma çevirisi uygulaması veya hizmetinde kullanılan Çeviriler, tüm konuşma giriş desteklenen diller için en yeni neural ağ tabanlı Çeviriler ile desteklenmektedir (bkz. burada tam listesi için). Bu modeller aynı zamanda daha fazla konuşulan metin corpora ile konuşulan konuşma türleri çeviriler için daha iyi bir model oluşturmak için mevcut, çoğunlukla yazılı metin eğitimli çeviri modelleri genişletilerek inşa edildi. Bu modeller de kullanılabilir "konuşma" standart kategorisi Geleneksel metin çeviri API 'sı.
Sinirsel çeviri tarafından desteklenmeyen diller için geleneksel smt çevirisi gerçekleştirilir.
Metin konuşma
Hedef dil desteklenen 18 metin-to-Speech biri ise Dillerve kullanım örneği bir ses çıkışı gerektiriyorsa, metin sonra konuşma sentezini kullanarak konuşma çıktısı dönüştürülür. Bu aşama konuşma-metin çevirisi senaryolarında atlanabilir.
Hakkında daha fazla bilgi edinin Microsoft 'un metin konuşma Hizmetleri.
Araştırma
Microsoft Translator ekibinden en son araştırma belgelerini görüntüleyin.



