
การแปลภาษาด้วยเครื่อง
การแปลเครื่องคืออะไร
ระบบการแปลภาษาเป็นแอปพลิเคชันหรือบริการออนไลน์ที่ใช้เทคโนโลยีการเรียนรู้ของเครื่องเพื่อแปลข้อความจำนวนมากจากและไปที่ส่วนใดก็ได้ที่ได้รับการสนับสนุน บริการแปลข้อความ "แหล่งที่มา" จากภาษาหนึ่งไปยังภาษา "เป้าหมาย" ที่แตกต่างกัน
แม้ว่าแนวคิดที่อยู่เบื้องหลังเทคโนโลยีการแปลเครื่องและอินเตอร์เฟซที่จะใช้มันค่อนข้างง่ายวิทยาศาสตร์และเทคโนโลยีที่อยู่เบื้องหลังมันมีความซับซ้อนมากและนำมารวมกันหลายเทคโนโลยีชั้นนำโดยเฉพาะอย่างยิ่งการเรียนรู้เชิงลึก ( ปัญญาประดิษฐ์), ข้อมูลขนาดใหญ่, ภาษาศาสตร์, คอมพิวเตอร์เมฆ, และ Api เว็บ.
ตั้งแต่ช่วงต้น 2010, เทคโนโลยีปัญญาประดิษฐ์ใหม่, เครือข่ายประสาทลึก (aka เรียนรู้ลึก), ได้อนุญาตให้เทคโนโลยีของการรู้จำเสียงพูดเพื่อเข้าถึงระดับคุณภาพที่อนุญาตให้ทีมนักแปลของ Microsoft เพื่อรวมการรู้จำเสียงกับ เทคโนโลยีการแปลข้อความหลักที่จะเปิดตัวใหม่เทคโนโลยีการแปลคำพูด
ในอดีต, เทคนิคการเรียนรู้เครื่องหลักที่ใช้ในอุตสาหกรรมคือการแปลเครื่องจักรสถิติ (SMT). SMT ใช้การวิเคราะห์ทางสถิติขั้นสูงเพื่อประเมินการแปลที่ดีที่สุดสำหรับคำที่ได้รับในบริบทของคำไม่กี่ มีการใช้ SMT ตั้งแต่กลาง-2000s โดยผู้ให้บริการการแปลที่สำคัญทั้งหมด, รวมทั้งไมโครซอฟท์.
การถือกำเนิดของการแปลเครื่องของระบบประสาท (NMT) ก่อให้เกิดการเปลี่ยนแปลงที่รุนแรงในเทคโนโลยีการแปลส่งผลให้การแปลที่มีคุณภาพสูงขึ้นมาก เทคโนโลยีการแปลนี้ได้เริ่มต้นการปรับใช้สำหรับผู้คนและนักพัฒนาใน หลังส่วนของ๒๐๑๖.
เทคโนโลยีการแปล SMT และ NMT มีสององค์ประกอบที่เหมือนกัน:
- ทั้งสองต้องการเนื้อหาที่แปลล่วงหน้าเป็นจำนวนมาก (คำแปลถึงล้านประโยค) เพื่อฝึกระบบ
- ทั้งไม่ทำหน้าที่เป็นพจนานุกรมสองภาษาแปลคำตามรายการของการแปลที่เป็นไปได้แต่แปลตามบริบทของคำที่ใช้ในประโยค
นักแปลคืออะไร?
บริการแปลและพูดซึ่งเป็นส่วนหนึ่งของบริการแปลและพูด บริการทางปัญญา คอลเลกชันของ APIs เป็นบริการแปลภาษาจาก Microsoft
การแปลข้อความ
กลุ่ม Microsoft ใช้ตัวแปลตั้งแต่ปี 2007 และพร้อมใช้งานเป็น API สําหรับลูกค้าตั้งแต่ปี 2011 ตัวแปลถูกใช้อย่างกว้างขวางภายใน Microsoft การสนับสนุน และทีมสื่อสารออนไลน์ บริการเดียวกันนี้สามารถเข้าถึงได้โดยไม่มีค่าใช้จ่ายเพิ่มเติมจากภายในผลิตภัณฑ์ Microsoft ที่คุ้นเคยเช่น Bing, Cortana, ไมโครซอฟท์เอดจ์, Office, Sharepoint, Skypeและ Yammer.
นักแปลสามารถใช้ในเว็บหรือโปรแกรมไคลเอนต์บนแพลตฟอร์มฮาร์ดแวร์ใด ๆ และกับระบบปฏิบัติการใด ๆ เพื่อดําเนินการแปลภาษาและการดําเนินงานที่เกี่ยวข้องกับภาษาอื่น ๆ เช่นการตรวจสอบภาษาข้อความจะพูดหรือพจนานุกรม
นักพัฒนาซอฟต์แวร์ส่งข้อความต้นฉบับ (หรือเสียงสำหรับการแปลคำพูด) ไปยังบริการที่มีพารามิเตอร์ที่ระบุภาษาเป้าหมายและบริการส่งกลับข้อความที่แปลแล้วสำหรับไคลเอ็นต์หรือเว็บแอปที่จะใช้
บริการแปลภาษาเป็นบริการ Azure ที่โฮสต์ในศูนย์ข้อมูลของ Microsoft และประโยชน์จากการรักษาความปลอดภัย
การแปลเสียงพูด
เทคโนโลยีการแปลคําพูดของนักแปลเปิดตัวในปลายปี 2014 เริ่มต้นด้วย Skype Translator และพร้อมใช้งานเป็น API แบบเปิดสําหรับลูกค้าตั้งแต่ต้นปี 2016 มันถูกรวมเข้ากับคุณลักษณะสดของ Microsoft Translator, Skype, การออกอากาศการประชุม Skype และแอป Microsoft Translator สําหรับ Android และ iOS
การแปลคำพูดจะพร้อมใช้งานผ่านทาง Microsoft Speech ซึ่งเป็นชุดของบริการที่ปรับแต่งได้อย่างเต็มที่สำหรับการรู้จำเสียงการแปลเสียงพูดและการสังเคราะห์เสียงพูด (การแปลงข้อความเป็นคำพูด)
การแปลข้อความทำงานอย่างไร
มีสองเทคโนโลยีหลักที่ใช้สำหรับการแปลข้อความ: มรดกทางสถิติเครื่องแปล (SMT), และรุ่นใหม่กว่าหนึ่ง, การแปลด้วยเครื่องประสาท (NMT)
การแปลภาษาด้วยเครื่องสถิติ
แปลของการแปลด้วยเครื่องวิเคราะห์ (SMT) ถูกสร้างขึ้นบนกว่าทศวรรษของการวิจัยภาษาธรรมชาติที่ไมโครซอฟท์ แทนที่จะเขียนกฎมือ crafted แปลระหว่างภาษา, ทันสมัยแปลระบบแปลวิธีการเป็นปัญหาของการเรียนรู้การแปลงข้อความระหว่างภาษาจากการแปลของมนุษย์ที่มีอยู่และใช้ประโยชน์จากความก้าวหน้าล่าสุดในสถิติประยุกต์และการเรียนรู้ของเครื่อง
เรียกว่า "ขนาน corpora" ทําหน้าที่เป็นศิลาโรเซตาที่ทันสมัยในสัดส่วนขนาดใหญ่ให้คําวลีและการแปลความหมายในบริบทสําหรับคู่ภาษาและโดเมนหลาย เทคนิคการสร้างแบบจําลองทางสถิติและอัลกอริทึมที่มีประสิทธิภาพช่วยให้คอมพิวเตอร์แก้ปัญหาของ decipherment (ตรวจสอบจดหมายโต้ตอบระหว่างแหล่งที่มาและภาษาเป้าหมายในข้อมูลการฝึกอบรม) และถอดรหัส (หาการแปลที่ดีที่สุดของประโยคใส่ใหม่) แปล unites พลังของวิธีการทางสถิติกับข้อมูลภาษาในการผลิตรุ่นที่ทั่วไปดีกว่าและนําไปสู่การแปลเข้าใจมากขึ้น
เพราะวิธีการนี้, ซึ่งไม่ได้พึ่งพาพจนานุกรมหรือกฎไวยากรณ์, มันให้คำแปลที่ดีที่สุดของวลีที่มันสามารถใช้บริบทรอบคำที่กำหนดเมื่อเทียบกับความพยายามที่จะดำเนินการแปลคำเดียว. สำหรับการแปลคำเดียว, พจนานุกรมสองภาษาได้รับการพัฒนาและสามารถเข้าถึงได้ผ่าน www.bing.com/translator.
การแปลเครื่องด้วยระบบประสาท
การปรับปรุงอย่างต่อเนื่องในการแปลเป็นสิ่งสําคัญ อย่างไรก็ตามการปรับปรุงประสิทธิภาพการทํางานมีที่ราบสูงด้วยเทคโนโลยี SMT ตั้งแต่กลางปี 2010 โดยใช้ประโยชน์จากขนาดและพลังของ Microsoft SuperComputer AI โดยเฉพาะ Microsoft Cognitive Toolkit, แปลตอนนี้มีเครือข่ายประสาท (แอลจี) ตามการแปลที่ช่วยให้ทศวรรษใหม่ของการปรับปรุงคุณภาพการแปล
โมเดลเครือข่ายประสาทเหล่านี้จะพร้อมใช้งานสําหรับภาษาพูดทั้งหมดผ่านบริการคําพูดบน Azure และผ่าน API ข้อความ โดยใช้รหัสประเภท 'ทั่วไป'
การแปลเครือข่ายประสาทพื้นฐานที่แตกต่างกันในวิธีการที่พวกเขาจะดำเนินการเมื่อเทียบกับ SMT แบบดั้งเดิม.
ภาพเคลื่อนไหวต่อไปนี้แสดงให้ทราบขั้นตอนต่างๆการแปลเครือข่ายประสาทไปผ่านการแปลประโยค เนื่องจากวิธีการนี้, การแปลจะนำไปสู่บริบทเต็มประโยค, เทียบกับเพียงไม่กี่คำที่เลื่อนหน้าต่างที่เทคโนโลยี SMT ใช้และจะผลิตของเหลวมากขึ้นและการแปลของมนุษย์ที่มองหาคำแปล.
บนพื้นฐานของการฝึกอบรมระบบเครือข่ายประสาทแต่ละคำจะถูกใส่รหัสตามเวกเตอร์ขนาด๕๐๐ (a) ซึ่งเป็นตัวแทนของลักษณะเฉพาะภายในคู่ภาษาโดยเฉพาะ (เช่นภาษาอังกฤษและภาษาจีน) ขึ้นอยู่กับคู่ภาษาที่ใช้สำหรับการฝึกอบรม, เครือข่ายประสาทจะกำหนดตัวเองสิ่งที่มิติเหล่านี้ควรจะ. พวกเขาสามารถเข้ารหัสแนวคิดง่ายๆเช่นเพศ (ผู้หญิง, ผู้ชาย, เป็นกลาง), ระดับมารยาท (สแลง, ลำลอง, เขียน, เป็นทางการ, ฯลฯ), ประเภทของคำ (กริยา, นาม, ฯลฯ), แต่ยังมีลักษณะที่ไม่ชัดเจนอื่นๆที่ได้มาจากข้อมูลการฝึกอบรม.
ขั้นตอนการแปลเครือข่ายประสาทผ่านไปมีดังต่อไปนี้:
- แต่ละคำหรือมากขึ้นโดยเฉพาะอย่างยิ่งการ๕๐๐-เวกเตอร์มิติที่แสดงให้เห็นผ่านชั้นแรกของ "เซลล์ประสาท" ที่จะเข้ารหัสใน๑๐๐๐-ขนาดเวกเตอร์ (b) เป็นตัวแทนของคำในบริบทของคำอื่นๆในประโยค
- เมื่อคำทั้งหมดได้รับการเข้ารหัสครั้งเดียวใน๑๐๐๐เหล่านี้-เวกเตอร์มิติ, กระบวนการจะถูกทำซ้ำหลายครั้ง, แต่ละชั้นช่วยให้ดีขึ้นปรับการปรับตัวของนี้๑๐๐๐-การแสดงมิติของคำในบริบทของประโยคเต็ม (ตรงกันข้าม SMT ที่สามารถพิจารณาได้เฉพาะหน้าต่าง3ถึง5คำ)
- เมทริกซ์เอาต์พุตสูงสุดจะถูกใช้โดยชั้นความสนใจ (เช่นอัลกอริทึมซอฟต์แวร์) ที่จะใช้ทั้งเมทริกซ์ผลผลิตสุดท้ายนี้และการส่งออกของคำแปลก่อนหน้านี้เพื่อกำหนดคำที่จากประโยคแหล่งที่มาควรจะแปลต่อไป นอกจากนี้ยังจะใช้การคำนวณเหล่านี้เพื่ออาจลดลงคำที่ไม่จำเป็นในภาษาเป้าหมาย
- เลเยอร์ตัวถอดรหัส (แปล) แปลคำที่เลือก (หรือเพิ่มเติมโดยเฉพาะอย่างยิ่งเวกเตอร์ขนาด๑๐๐๐ที่แสดงถึงคำนี้ภายในบริบทของประโยคเต็ม) ในภาษาเป้าหมายที่เหมาะสมที่สุดเท่านั้น การส่งออกของชั้นสุดท้ายนี้ (c) จะถูกป้อนกลับเข้าไปในชั้นความสนใจในการคำนวณที่คำถัดไปจากประโยคแหล่งที่มาควรจะแปล

ในตัวอย่างที่ปรากฎในภาพเคลื่อนไหวบริบท-ตระหนักถึง๑๐๐๐-แบบจำลองมิติของ "การ"จะเข้ารหัสว่าคำนาม (เฮาส์) เป็นคำของผู้หญิงในภาษาฝรั่งเศส (ลาเมซง). การทำเช่นนี้จะอนุญาตให้มีการแปลที่เหมาะสมสำหรับ "การ"เป็น"ลา"และไม่"เลอ"(เอกพจน์, ชาย) หรือ"เลส์"(พหูพจน์) เมื่อมันถึงตัวถอดรหัส (แปล) ชั้น.
อัลกอริทึมความสนใจจะคำนวณขึ้นอยู่กับคำ (s) แปลก่อนหน้านี้ (ในกรณีนี้ "การ") ว่าคำต่อไปที่จะได้รับการแปลควรเป็นเรื่อง ("เฮาส์ความคิดเห็นสี ฟ้า"). ในสามารถบรรลุนี้ได้เนื่องจากระบบเรียนรู้ว่าภาษาอังกฤษและภาษาฝรั่งเศสกลับคำสั่งของคำเหล่านี้ในประโยค นอกจากนี้ยังมีการคำนวณว่าถ้าคำคุณศัพท์เป็น "ใหญ่"แทนที่จะเป็นสีที่มันไม่ควรจะสลับพวกเขา ("บ้านใหญ่"= >"ลากรังเดเมซง").
ขอบคุณวิธีการนี้ผลผลิตสุดท้ายคือในกรณีส่วนใหญ่ได้อย่างคล่องแคล่วมากขึ้นและใกล้ชิดกับการแปลของมนุษย์มากกว่าการแปล SMT ตามที่เคยได้รับ
การแปลคำพูดทำงานอย่างไร
นักแปลยังสามารถแปลคําพูดได้ เทคโนโลยีนี้จะเปิดเผยในคุณสมบัติล่ามสด (http://translate.it), ปพลิเคชันนักแปล, Skype แปลและยังเป็นครั้งแรกที่ทำให้พร้อมใช้งานเฉพาะผ่านทาง Skype ผู้แปลคุณลักษณะและในปพลิเคชัน Microsoft แปลบน iOS และ Android, ฟังก์ชันนี้จะพร้อมใช้งานสำหรับนักพัฒนาที่มีรุ่นล่าสุดของการเปิด API ที่เหลืออยู่บนพอร์ทัล Azure
แม้ว่ามันอาจจะดูเหมือนเป็นกระบวนการตรงไปข้างหน้าอย่างรวดเร็วก่อนที่จะสร้างเทคโนโลยีการแปลคำพูดจากอิฐเทคโนโลยีที่มีอยู่, มันจำเป็นต้องทำงานมากขึ้นกว่าเพียงแค่เสียบ "แบบดั้งเดิม" ที่มีอยู่ "การรู้จำเสียงของมนุษย์ต่อเครื่อง เครื่องยนต์เพื่อแปลข้อความที่มีอยู่หนึ่ง
หากต้องการแปลคำพูด "แหล่งที่มา" อย่างถูกต้องจากภาษาหนึ่งไปเป็นภาษา "เป้าหมาย" อื่นระบบจะดำเนินการกระบวนการสี่ขั้นตอน
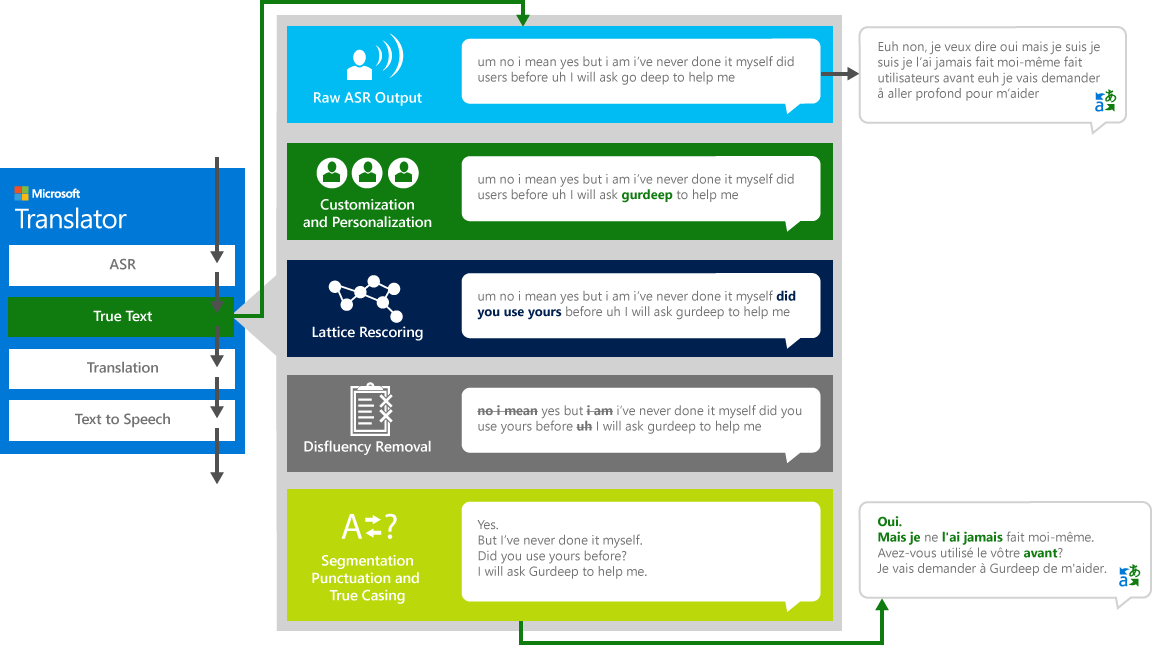
- การรู้จำเสียงในการแปลงเสียงเป็นข้อความ
- TrueText: เทคโนโลยีของ Microsoft ที่ใช้ประโยชน์จากข้อความที่จะทำให้มันเหมาะสมมากขึ้นสำหรับการแปล
- แปลผ่านเครื่องมือแปลข้อความที่อธิบายไว้ข้างต้นแต่ในรูปแบบการแปลที่พัฒนาขึ้นเป็นพิเศษสำหรับชีวิตจริงพูดคุย
- การแปลงข้อความเป็นคำพูดเมื่อจำเป็นในการผลิตเสียงที่แปล

การรู้จำเสียงอัตโนมัติ (ASR)
การรู้จำเสียงอัตโนมัติ (ASR) จะดำเนินการโดยใช้ระบบเครือข่ายประสาท (NN) การฝึกอบรมในการวิเคราะห์หลายพันชั่วโมงของการพูดเสียงเข้ามา รุ่นนี้ได้รับการฝึกอบรมเกี่ยวกับการโต้ตอบของมนุษย์ต่อมนุษย์มากกว่าคำสั่งของมนุษย์ต่อเครื่อง, การผลิตการรู้จำเสียงที่เหมาะสำหรับการสนทนาปกติ. เพื่อให้บรรลุนี้, ข้อมูลมากขึ้นเป็นสิ่งจำเป็นเช่นเดียวกับ DNN ขนาดใหญ่กว่าของมนุษย์ต่อเครื่อง ASRs.
เรียนรู้เพิ่มเติมเกี่ยวกับ คำพูดของ Microsoft กับบริการข้อความ.
การให้คะแนน
เราไม่พูดอย่างสมบูรณ์แบบชัดเจนหรือเรียบร้อยขณะที่เรามักคิดว่าเราทำ ด้วยเทคโนโลยี TrueText ข้อความที่เป็นตัวอักษรจะถูกเปลี่ยนให้เป็นไปตามเจตนาของผู้ใช้อย่างใกล้ชิดโดยการนำคำพูดออก (คำฟิลเลอร์) เช่น "um" s, "ah" s "และ" s "เช่น" s, stutters และการทำซ้ำ นอกจากนี้ยังสามารถอ่านข้อความได้มากขึ้นโดยการเพิ่มตัวแบ่งประโยคเครื่องหมายวรรคตอนที่เหมาะสมและตัวพิมพ์ใหญ่ เพื่อให้บรรลุผลเหล่านี้เราใช้เวลาหลายทศวรรษของการทำงานในเทคโนโลยีภาษาที่เราพัฒนาขึ้นจากนักแปลเพื่อสร้าง TrueText แผนภาพต่อไปนี้แสดงให้ทราบผ่านตัวอย่างในชีวิตจริงการเปลี่ยนแปลงต่างๆ TrueText ดำเนินการเพื่อทำให้ข้อความตัวอักษรนี้เป็นปกติ
แปล
จากนั้นข้อความจะถูกแปลเป็น ภาษาและภาษาถิ่น สนับสนุนโดยนักแปล
การแปลโดยใช้ API การแปลคำพูด (เป็นนักพัฒนา) หรือในแอปพลิเคชันการแปลคำพูดหรือบริการจะขับเคลื่อนด้วยการแปลใหม่ล่าสุดเครือข่ายระบบประสาทสำหรับภาษาที่สนับสนุนการป้อนข้อมูลเสียงพูดทั้งหมด (ดู ที่นี่ สำหรับรายการทั้งหมด) รูปแบบเหล่านี้ถูกสร้างขึ้นโดยการขยายตัวในปัจจุบัน, ส่วนใหญ่เขียนข้อความแบบจำลองการแปล, ด้วยคำพูดมากขึ้นในการสร้างรูปแบบที่ดีกว่าสำหรับการสนทนาประเภทการพูดคุยของการแปล. รุ่นเหล่านี้ยังมีอยู่ผ่าน ประเภทมาตรฐาน "เสียงพูด" ของ API การแปลข้อความแบบดั้งเดิม
สำหรับภาษาใดๆที่ไม่ได้รับการสนับสนุนโดยการแปลระบบประสาท, การแปล SMT แบบดั้งเดิมจะดำเนินการ
ข้อความที่จะพูด
ถ้าภาษาเป้าหมายเป็นหนึ่งใน18ที่สนับสนุนการแปลงข้อความเป็นคำพูด ภาษาและกรณีการใช้งานต้องการเอาต์พุตเสียงข้อความจะถูกแปลงเป็นเอาต์พุตเสียงโดยใช้การสังเคราะห์เสียงพูด ขั้นตอนนี้จะถูกละเว้นในสถานการณ์สมมติการแปลเป็นข้อความคำพูด
เรียนรู้เพิ่มเติมเกี่ยวกับ ข้อความของ Microsoft กับบริการเสียงพูด.



