
Strojový překlad
Co je strojový překlad?
Systémy strojového překladu jsou aplikace nebo služby online, které používají technologie učení se strojem k překladu velkého množství textu z a do všech podporovaných jazyků. Služba převádí "zdrojový" text z jednoho jazyka do jiného "cílového" jazyka.
Ačkoli pojmy týkající se techniky strojového překladu a rozhraní pro její využití jsou relativně jednoduché, věda a technologie za ní jsou extrémně složité a sdružují několik špičkových technologií, zejména hloubkové vzdělávání ( Umělá inteligence), velkých dat, lingvistiky, počítačových počítačů a webových rozhraní API.
Od počátku 2010s nová technologie umělé inteligence, hluboké neuronové sítě (neboli hluboké učení) umožnila technologii rozpoznávání řeči dosáhnout úrovně kvality, která umožnila týmu Microsoft Translator kombinovat rozpoznávání řeči s základní textové překladatelské technologie pro spuštění nové technologie překladu řeči.
Historicky, technika výuky primárního stroje používaná v průmyslu byla statistická strojová překladatelská společnost (SMT). SMT používá pokročilou statistickou analýzu k odhadu nejlepšího možného překladu pro slovo, které je dáno v kontextu několika slov. Společnost SMT byla od poloviny roku 2000s používána všemi hlavními zprostředkovateli překladatelských služeb, včetně společnosti Microsoft.
Nástup nervové strojového překladu (NMT) způsobil radikální posun v překladatelských technologiích, což vedlo k mnohem vyššímu kvalitnímu překladu. Tato technologie překladu začala nasazovat uživatele a vývojáře v Poslední část 2016.
Překladatelské technologie SMT i NMT mají dva prvky společné:
- Obě vyžadují velké množství předčlověka přeloženého obsahu (až miliónů přeložených vět), aby mohly systém trénovat.
- Ani se nechovat jako dvojjazyčné slovníky, překládat slova na základě seznamu potenciálních překladů, ale přeložit na základě kontextu slova, které je použito ve větě.
Co je překladatel?
Překladatelské a řečové služby, které jsou součástí Kognitivní služby kolekce rozhraní API, jedná se o služby strojového překladu od společnosti Microsoft.
Textový překlad
Překladač používají skupiny Microsoft od roku 2007 a od roku 2011 je k dispozici jako rozhraní API pro zákazníky. Překladač se v rámci společnosti Microsoft hojně používá. Je začleněna mezi lokalizační, podpůrné a online komunikační týmy. Stejná služba je také přístupná bez dalších nákladů ze známých produktů společnosti Microsoft, jako jsou Bing, Kortana, Hrana společnosti Microsoft, Office, Sharepoint, Skypea Kňourat.
Překladač lze použít ve webových nebo klientských aplikacích na libovolné hardwarové platformě a s libovolným operačním systémem k provádění jazykového překladu a dalších jazykových operací, jako je detekce jazyka, převod textu na řeč nebo slovník.
Díky standardní technologii REST ve výrobním odvětví odesílá vývojář zdrojový text (nebo zvuk pro překlad řeči) do služby s parametrem označujícím cílový jazyk a služba odešle zpět přeložený text pro klienta nebo webovou aplikaci, který má být použit.
Služba Translator je služba Azure hostovaná v datových centrech Microsoftu a těží z zabezpečení, škálovatelnosti, spolehlivosti a nepřetržité dostupnosti, kterou přijímají i ostatní cloudové služby Microsoftu.
Překlad řeči
Technologie překladače řeči byla spuštěna koncem roku 2014 počínaje Skype Translator a je k dispozici jako otevřené ROZHRANÍ API pro zákazníky od začátku roku 2016. Je integrován do živé funkce Microsoft Translator, Skype, skype meeting broadcast a aplikací Microsoft Translator pro Android a iOS.
Překlad řeči je nyní k dispozici prostřednictvím aplikace Microsoft Speech, komplexní sady plně přizpůsobitelných služeb pro rozpoznávání řeči, překlad řeči a syntézu řeči (převod textu na řeč).
Jak funguje překlad textu?
Pro textový překlad se používají dvě hlavní technologie: starší verze, statistický strojový překlad (SMT) a novější generace, nervový strojový překlad (NMT).
Statistický strojový překlad
Překladatelimplementace statistického strojového překladu (SMT) je postavena na více než deseti letech výzkumu v přirozeném jazyce ve společnosti Microsoft. Moderní překladatelské systémy nepíší ručně vytvořená pravidla pro překlad mezi jazyky, ale přistupují k překladu jako k problému učení se transformaci textu mezi jazyky ze stávajících lidských překladů a využití nedávného pokroku v aplikované statistice a strojovém učení.
Takzvané "paralelní korpusy" působí jako moderní Rosetta Stone v obrovských poměrech a poskytují slovo, frázi a idiomatické překlady v kontextu pro mnoho jazykových párů a domén. Statistické modelování techniky a efektivní algoritmy pomáhají počítači řešit problém dešifrování (detekce korespondence mezi zdrojovým a cílovým jazykem v trénovacích datech) a dekódování (nalezení nejlepšího překladu nové vstupní věty). Překladatel spojuje sílu statistických metod s jazykovými informacemi, aby vytvořil modely, které lépe zobecnit a vést k srozumitelnější překlady.
Vzhledem k tomuto přístupu, který není závislý na slovnících nebo gramatických pravidlech, poskytuje nejlepší překlady frází, kde může používat kontext kolem daného slova a pokoušet se provádět jednoduché překlady slov. Pro překlady jednoduchých slov byl dvojjazyčný slovník vyvinut a je přístupný prostřednictvím www.Bing.com/Translator.
Překlad nervového stroje
Neustálé zlepšování překladů je důležité. Nicméně, zlepšení výkonu se svalnaté s technologií SMT od poloviny-2010s. Využitím rozsahu a výkonu superpočítače AI společnosti Microsoft, konkrétně sady Microsoft Cognitive Toolkit, translator nyní nabízí neuronovou síť (MODUL LSTM) založený na překladu, který umožňuje nové desetiletí zlepšení kvality překladu.
Tyto modely neuronové sítě jsou k dispozici pro všechny jazyky řeči prostřednictvím služby řeči v Azure a prostřednictvím textového rozhraní API pomocí ID kategorie "generalnn".
Překlady nervových sítí se zásadně liší v tom, jak jsou prováděny ve srovnání s tradičními SMT.
Následující animace znázorňuje různé kroky překladu neuronové sítě, které procházejí větou. Vzhledem k tomuto přístupu bude překlad brát v úvahu celou větu, a to pouze několik slov, které používá technologie SMT, a bude produkovat více tekutin a překladů.
Na základě výcviku neuronové sítě je každé slovo zakódováno v 500-dimenzím vektoru (a) reprezentujícím jeho jedinečné vlastnosti v určitém jazykovém páru (např. angličtina a čínština). Na základě dvojic jazyků používaných pro výcvik se neuronová síť sama definuje, jaké rozměry by měly být. Mohly by kódovat jednoduché pojmy, jako jsou pohlaví (ženská, mužský, neutrální), zdvořilost (slang, neformální, písemný, formální atd.), typ slova (sloveso, substantivum atd.), ale také jakékoli jiné nezjevné vlastnosti odvozené od vzdělávacích údajů.
Následuje postup překladu nervových sítí:
- Každé slovo nebo přesněji 500-rozměr vektor, který jej reprezentuje, prochází první vrstvou "neuronů", která jej zakóduje do 1000-dimenbního vektoru (b) představující slovo v kontextu ostatních slov ve větě.
- Jakmile jsou všechna slova jednou zakódována do těchto 1000-dimenzní vektorů, proces se několikrát opakuje, každá vrstva umožňuje lepší doladění tohoto 1000-rozměru vyjádření slova v kontextu plné věty (na rozdíl od SMT technologie, která může vzít v úvahu pouze 3 až 5 slov okna)
- Konečná výstupní matice je pak využívána vrstvou upozornění (tj. softwarový algoritmus), která bude používat jak tuto konečnou výstupní matici, tak i výstup dříve přeložených slov, aby definovaly, které slovo ze zdrojové věty by mělo být dále přeloženo. Tyto výpočty budou také použity k potenciálně přetažení nepotřebných slov v cílovém jazyce.
- Dekódovací vrstva přeloží vybrané slovo (nebo přesněji 1000-rozměr vektor představující toto slovo v kontextu plné věty) ve svém nejvhodnějším ekvivalentu cílového jazyka. Výstup této poslední vrstvy (c) se pak opět vrátí do vrstvy s důrazem, aby se vypočítal, které další slovo ze zdrojové věty má být přeloženo.

V příkladu, který je zobrazen v animaci, je kontextový model 1000-rozměr modelu "Tá"zakóduje, že substantivum (Dům) je ženské slovo ve francouzštině (La Maison). To umožní odpovídající překlad pro "Tá"být"La"a ne"Le"(jednotné, mužské) nebo"Les"(množné číslo), jakmile dosáhne vrstvy dekodéru (překladu).
Algoritmus upozornění bude také vypočítávat na základě dříve přeložených slov (v tomto případě "Tá"), že následující slovo, které má být přeloženo, by mělo být předmětem ("Dům") a nikoli přídavné jméno ("Modré"). V této oblasti toho lze dosáhnout, protože systém zjistil, že angličtina a francouzština Invertuje pořadí těchto slov ve větách. Bylo by také vypočítáno, že má-li být adjektivum "Velký"místo barvy je neinvertujte ("velký dům"= >"La Grande Maison").
Díky tomuto přístupu je konečný výstup ve většině případů plynněji a blíže k překladu člověka, než jaký by kdy mohl být překlad založený na SMT.
Jak funguje překlad řeči?
Překladatel je také schopen překládat řeč. Tato technologie je vystavena v živé funkci Překladač (http://translate.it), překladač aplikací Skype, a zároveň je zpřístupněných pouze prostřednictvím funkce aplikace Skype Translator a v aplikacích Microsoft Translator na serveru iOS a Android, je tato funkce nyní k dispozici vývojářům s nejnovější verzí otevřeného ROZHRANÍ API na bázi REST dostupné na Azure portálu.
I když se může zdát, že se na první pohled jeví jako přímý dopředový proces, jak vybudovat technologii překladu řeči ze stávajících technologických cihel, vyžaduje to mnohem více práce než pouhé připojení stávajícího "tradičního" rozpoznávání řeči mezi lidmi a počítači na stávající textový překlad.
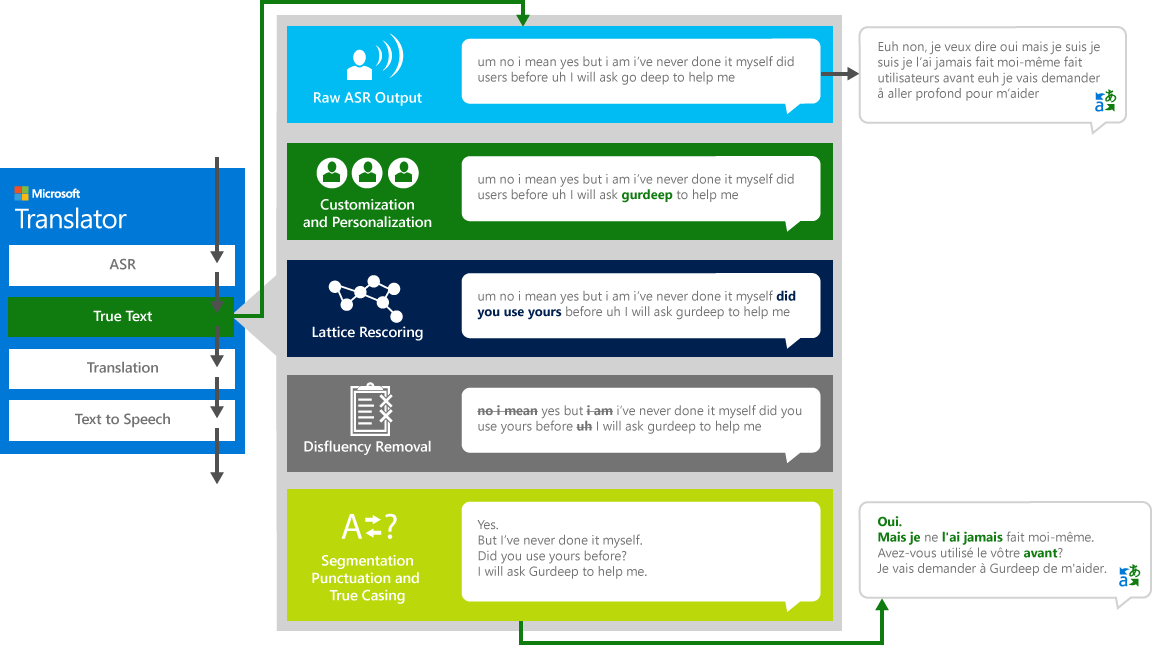
Chcete-li správně přeložit "zdrojový" projev z jednoho jazyka do jiného "cílového" jazyka, systém projde procesem ve čtyřech krocích.
- Rozpoznávání řeči, pro převod zvuku do textu
- TrueText: technologie společnosti Microsoft, která normalizuje text tak, aby byla vhodnější pro překlady
- Překlad přes výše popsaný modul pro překlady textu, ale na překladatelských modelech speciálně vyvinutých pro skutečný život mluvené rozhovory
- V případě potřeby text na řeč pro vytvoření přeloženého zvuku.

Automatické rozpoznávání řeči (ASR)
Automatické rozpoznávání řeči (ASR) se provádí pomocí systému nervových sítí (NN), který je vycvičen při analýze tisíců hodin příchozí zvukové řeči. Tento model je trénoval na interakci mezi člověkem a lidmi, nikoli s příkazy od člověka k počítači, což vytváří rozpoznávání řeči, které je optimalizováno pro normální konverzaci. Aby toho bylo dosaženo, je zapotřebí mnohem více dat, stejně jako větší DNN než tradiční mezilidské ASRs.
Další informace o Řeč společnosti Microsoft na textové služby.
PravdivýText
Když lidé hovoří s jinými lidmi, nemluvíme tak dokonale, jasně nebo elegantně, jak si často myslíme. Díky technologii TrueText je literál textu transformován tak, aby lépe odrážel uživatelský záměr, a to odebráním odtoků řeči (výplňová slova), jako například "um", "Ah" s, "a" s, "jako" s, stutters "a opakováními. Text je také srozumitelnější a přeložitelný přidáním konců vět, správných interpunkčních znamének a velkých písmen. Abychom dosáhli těchto výsledků, používali jsme desítky let práce na jazykových technologiích, vyvinuli jsme se z překladače a vytvořili tak TrueText. Následující diagram znázorňuje prostřednictvím příkladu reálného života různé transformace TrueText, která pracuje na normalizování tohoto literálního textu.
Překlad
Text je pak přeložen do libovolné jazyky a dialekty podporována překladatelem.
Překlady pomocí rozhraní API pro překlad řeči (jako vývojář) nebo z aplikace nebo služby překladu řeči jsou napájeny nejnovějšími překlady nervových sítí pro všechny jazyky podporované mluvením (viz zde pro úplný seznam). Tyto modely byly také vybudovány rozšířením současných, většinou napsaných, převážně psaných překladatelských modelů, s více mluvenými texty a s větším modelem pro vytvoření lepšího modelu pro mluvené konverzační typy překladů. Tyto modely jsou také k dispozici prostřednictvím standardní kategorie "řeč" z tradičního rozhraní API pro překlad textu.
Pro všechny jazyky, které nejsou podporovány nervovým překladem, je prováděn tradiční překlad SMT.
Text na řeč
Pokud je cílovým jazykem jeden z 18 podporovaných textů na řeč Jazykya případ použití vyžaduje zvukový výstup, text je pak převeden na výstup řeči pomocí syntézy řeči. Tato fáze je vynechána ve scénářích překladu řeči na text.
Další informace o Služba pro zpracování textu mluvené řeči společnosti Microsoft.
Výzkum
Prohlédněte si nejnovější výzkumné dokumenty z týmu Microsoft Translator.



