
Machine Translation
What is machine translation?
Machine translation systems are applications or online services that use machine-learning technologies to translate large amounts of text from and to any of their supported languages. The service translates a “source” text from one language to a different “target” language.
Although the concepts behind machine translation technology and the interfaces to use it are relatively simple, the science and technologies behind it are extremely complex and bring together several leading-edge technologies, in particular, deep learning (artificial intelligence), big data, linguistics, cloud computing, and web APIs.
Since the early 2010s, a new artificial intelligence technology, deep neural networks (aka deep learning), has allowed the technology of speech recognition to reach a quality level that allowed the Microsoft Translator team to combine speech recognition with its core text translation technology to launch a new speech translation technology.
Historically, the primary machine learning technique used in the industry was Statistical Machine Translation (SMT). SMT uses advanced statistical analysis to estimate the best possible translations for a word given the context of a few words. SMT has been used since the mid-2000s by all major translation service providers, including Microsoft.
The advent of Neural Machine Translation (NMT) caused a radical shift in translation technology, resulting in much higher quality translations. This translation technology started deploying for users and developers in the latter part of 2016.
Both SMT and NMT translation technologies have two elements in common:
- Both require large amounts of pre-human translated content (up to millions of translated sentences) to train the systems.
- Neither act as bilingual dictionaries, translating words based on a list of potential translations, but translate based on the context of the word that is used in a sentence.
What is Translator?
Translator and Speech services, part of the Cognitive Services collection of APIs, are machine translation services from Microsoft.
Text translation
Translator has been used by Microsoft groups since 2007 and is available as an API for customers since 2011. Translator is used extensively within Microsoft. It is incorporated across product localization, support, and online communication teams. This same service is also accessible, at no additional cost, from within familiar Microsoft products such as Bing, Cortana, Microsoft Edge, Office, SharePoint, Skype, and Yammer.
Translator can be used in web or client applications on any hardware platform and with any operating system to perform language translation and other language-related operations such as language detection, text to speech, or dictionary.
Leveraging industry standard REST technology, the developer sends source text (or audio for speech translation) to the service with a parameter indicating the target language, and the service sends back the translated text for the client or web app to use.
The Translator service is an Azure service hosted in Microsoft data centers and benefits from the security, scalability, reliability, and nonstop availability that other Microsoft cloud services also receive.
Speech translation
Translator speech translation technology was launched late 2014 starting with Skype Translator, and is available as an open API for customers since early 2016. It is integrated into the Microsoft Translator live feature, Skype, Skype meeting broadcast, and the Microsoft Translator apps for Android and iOS.
Speech translation is now available through Microsoft Speech, an end-to-end set of fully customizable services for speech recognition, speech translation, and speech synthesis (text-to-speech).
How does text translation work?
There are two main technologies used for text translation: the legacy one, Statistical Machine Translation (SMT), and the newer generation one, Neural Machine Translation (NMT).
Statistical machine translation
Translator’s implementation of Statistical Machine Translation (SMT) is built on more than a decade of natural-language research at Microsoft. Rather than writing hand-crafted rules to translate between languages, modern translation systems approach translation as a problem of learning the transformation of text between languages from existing human translations and leveraging recent advances in applied statistics and machine learning.
So-called “parallel corpora” act as a modern Rosetta Stone in massive proportions, providing word, phrase, and idiomatic translations in context for many language pairs and domains. Statistical modeling techniques and efficient algorithms help the computer address the problem of decipherment (detecting the correspondences between source and target language in the training data) and decoding (finding the best translation of a new input sentence). Translator unites the power of statistical methods with linguistic information to produce models that generalize better and lead to more comprehensible translations.
Because of this approach, which does not rely on dictionaries or grammatical rules, it provides the best translations of phrases where it can use the context around a given word versus trying to perform single word translations. For single words translations, the bilingual dictionary was developed and is accessible through www.bing.com/translator.
Neural machine translation
Continuous improvements to translation are important. However, performance improvements have plateaued with SMT technology since the mid-2010s. By leveraging the scale and power of Microsoft’s AI supercomputer, specifically the Microsoft Cognitive Toolkit, Translator now offers neural network (LSTM) based translation that enables a new decade of translation quality improvement.
These neural network models are available for all speech languages through Speech service on Azure and through the text API by using the ‘generalnn’ category ID.
Neural network translations fundamentally differ in how they are performed compared to the traditional SMT ones.
The following animation depicts the various steps neural network translations go through to translate a sentence. Because of this approach, the translation will take into context the full sentence, versus only a few words sliding window that SMT technology uses and will produce more fluid and human-translated looking translations.
Based on the neural-network training, each word is coded along a 500-dimensions vector (a) representing its unique characteristics within a particular language pair (e.g. English and Chinese). Based on the language pairs used for training, the neural network will self-define what these dimensions should be. They could encode simple concepts like gender (feminine, masculine, neutral), politeness level (slang, casual, written, formal, etc.), type of word (verb, noun, etc.), but also any other non-obvious characteristics as derived from the training data.
The steps neural network translations go through are the following:
- Each word, or more specifically the 500-dimension vector representing it, goes through a first layer of “neurons” that will encode it in a 1000-dimension vector (b) representing the word within the context of the other words in the sentence.
- Once all words have been encoded one time into these 1000-dimension vectors, the process is repeated several times, each layer allowing better fine-tuning of this 1000-dimension representation of the word within the context of the full sentence (contrary to SMT technology that can only take into consideration a 3 to 5 words window)
- The final output matrix is then used by the attention layer (i.e. a software algorithm) that will use both this final output matrix and the output of previously translated words to define which word, from the source sentence, should be translated next. It will also use these calculations to potentially drop unnecessary words in the target language.
- The decoder (translation) layer, translates the selected word (or more specifically the 1000-dimension vector representing this word within the context of the full sentence) in its most appropriate target language equivalent. The output of this last layer (c) is then fed back into the attention layer to calculate which next word from the source sentence should be translated.

In the example depicted in the animation, the context-aware 1000-dimension model of “the” will encode that the noun (house) is a feminine word in French (la maison). This will allow the appropriate translation for “the” to be “la” and not “le” (singular, male) or “les” (plural) once it reaches the decoder (translation) layer.
The attention algorithm will also calculate, based on the word(s) previously translated (in this case “the”), that the next word to be translated should be the subject (“house”) and not an adjective (“blue”). In can achieve this because the system learned that English and French invert the order of these words in sentences. It would have also calculated that if the adjective were to be “big” instead of a color, that it should not invert them (“the big house” => “la grande maison”).
Thanks to this approach, the final output is, in most cases, more fluent and closer to a human translation than an SMT-based translation could have ever been.
How does speech translation work?
Translator is also capable of translating speech. This technology is exposed in the Translator live feature (http://translate.it), the Translator apps, Skype Translator and is also Initially made available only through the Skype Translator feature and in the Microsoft Translator apps on iOS and Android, this functionality is now available to developers with the latest version of the open REST-based API available on the Azure portal.
Although it may seem like a straight forward process at a first glance to build a speech translation technology from the existing technology bricks, it required much more work than simply plugging an existing “traditional” human-to-machine speech recognition engine to the existing text translation one.
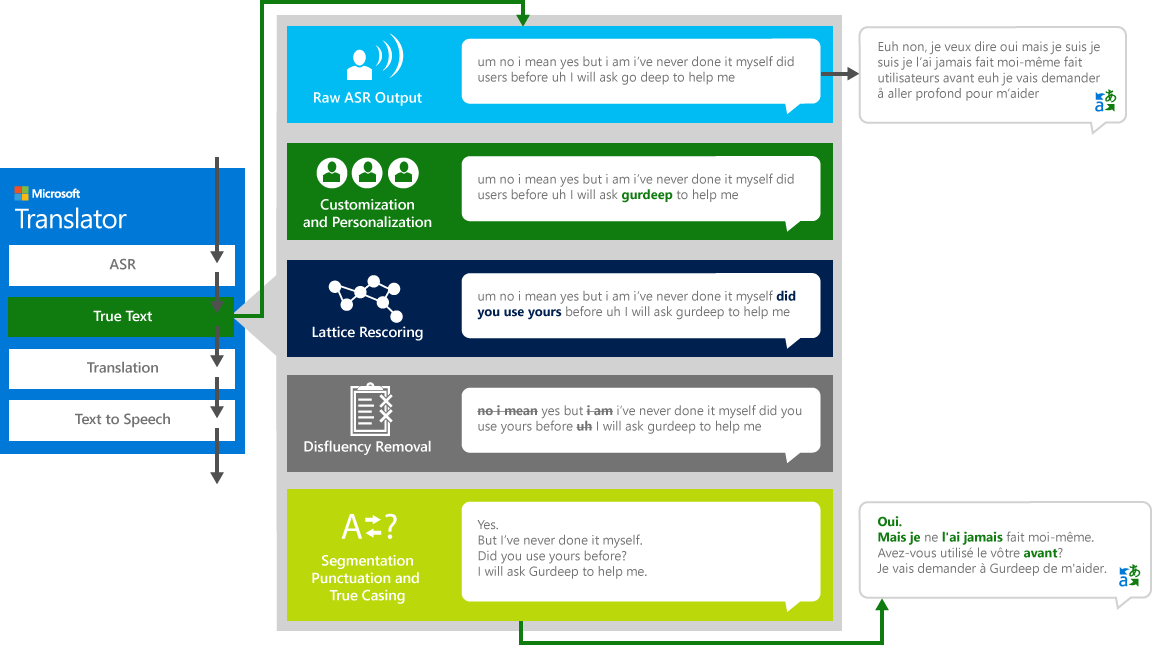
To properly translate the “source” speech from one language to a different “target” language, the system goes through a four-step process.
- Speech recognition, to convert audio in into text
- TrueText: A Microsoft technology that normalizes the text to make it more appropriate for translation
- Translation through the text translation engine described above but on translation models specially developed for real life spoken conversations
- Text-to-speech, when necessary, to produce the translated audio.

Automatic Speech Recognition (ASR)
Automatic Speech Recognition (ASR) is performed using a neural network (NN) system trained on analyzing thousands of hours of incoming audio speech. This model is trained on human-to-human interactions rather than human-to-machine commands, producing speech recognition that is optimized for normal conversations. To achieve this, much more data is needed as well as a larger DNN than traditional human-to-machine ASRs.
Learn more about Microsoft’s speech to text services.
TrueText
As humans conversing with other humans, we don’t speak as perfectly, clearly or neatly as we often think we do. With the TrueText technology, the literal text is transformed to more closely reflect user intent by removing speech disfluencies (filler words), such as “um”s, “ah”s, “and”s, “like”s, stutters, and repetitions. The text is also made more readable and translatable by adding sentence breaks, proper punctuation, and capitalization. To achieve these results, we used the decades of work on language technologies, we developed from Translator to create TrueText. The following diagram depicts, through a real-life example, the various transformation TrueText operates to normalize this literal text.
Translation
The text is then translated into any of the languages and dialects supported by Translator.
Translations using the speech translation API (as a developer) or in a speech translation app or service, is powered with the newest neural-network based translations for all the speech-input supported languages (see here for the full list). These models were also built by expanding the current, mostly written-text trained translation models, with more spoken-text corpora to build a better model for spoken conversation types of translations. These models are also available through the “speech” standard category of the traditional text translation API.
For any languages not supported by neural translation, traditional SMT translation is performed.
Text to Speech
If the target language is one of the 18 supported text-to-speech languages, and the use case requires an audio output, the text is then converted into speech output using speech synthesis. This stage is omitted in speech-to-text translation scenarios.
Learn more about Microsoft’s text to speech services.
Research
View the most recent research papers from the Microsoft Translator team.



