
Strojový preklad
Čo je strojový preklad?
Systémy strojového prekladu sú aplikácie alebo online služby, ktoré využívajú technológie strojového učenia na preklad veľkého množstva textu z a do niektorého z podporovaných jazykov. Služba prekladá text "zdroj" z jedného jazyka do iného "cieľového" jazyka.
Hoci pojmy technológie strojového prekladu a rozhrania, ktoré sa používajú, sú relatívne jednoduché, veda a technológie za ním sú nesmierne zložité a spájajú niekoľko špičkových technológií, najmä hlbokého učenia ( umelej inteligencie), veľké dáta, lingvistika, cloud computing a Web API.
Od začiatku 2010s, nové technológie umelej inteligencie, hlboké neurónové siete (aka hlboké učenie), umožnila technológiu rozpoznávania reči dosiahnuť úroveň kvality, ktorá umožnila Microsoft Translator tím kombinovať rozpoznávanie reči s jeho Core text prekladu technológie pre spustenie novej technológie reči prekladu.
Historicky, primárnej techniky strojového učenia používané v priemysle bol štatistický strojový preklad (SMT). SMT využíva pokročilú štatistickú analýzu na odhad najlepších možných prekladov pre slovo vzhľadom na kontext niekoľkých slov. SMT bol používaný od polovice-2000s všetkých hlavných poskytovateľov prekladateľských služieb, vrátane Microsoft.
Nástup neurónové strojový preklad (NMT) spôsobil radikálny posun v preklade technológie, čo vedie k oveľa vyššej kvalite prekladov. Táto prekladateľská technológia začala nasadzovanie pre používateľov a vývojárov v Druhá časť 2016.
Prekladové technológie SMT aj NMT majú spoločné dva prvky:
- Obaja vyžadujú veľké množstvo pre-ľudský preložený obsah (až do miliónov preložených viet) trénovať systémy.
- Ani pôsobiť ako dvojjazyčné slovníky, prekladať slová na základe zoznamu potenciálnych prekladov, ale prekladať na základe kontextu slova, ktoré sa používa vo vete.
Čo je prekladateľ?
Prekladateľov a rečových služieb, časť Kognitívne služby Kolekcie rozhraní API, sú služby strojového prekladu od spoločnosti Microsoft.
Preklad textu
Translator používajú skupiny spoločnosti Microsoft od roku 2007 a od roku 2011 je k dispozícii ako API pre zákazníkov. Prekladač sa vo veľkej miere používa v rámci spoločnosti Microsoft. Je začlenená do lokalizačných, podporných a online komunikačných tímov. Táto služba je tiež prístupná bez dodatočných nákladov v rámci známych produktov spoločnosti Microsoft, ako sú Bing, Cortana, Microsoft Edge, Office, Sharepoint, Skypea Nariekanie.
Prekladateľ môže byť použitý vo webových alebo klientských aplikáciách na ľubovoľnej hardvérovej platforme a s akýmkoľvek operačným systémom na vykonávanie jazykových prekladov a iných jazykových operácií, ako je zisťovanie jazyka, text do reči alebo slovník.
Využitím priemyselnej štandardnej technológie REST, Developer odošle zdrojový text (alebo audio pre preklad reči) k službe s parametrom označujúcim cieľový jazyk a služba odošle späť preložený text pre klienta alebo webovú aplikáciu, ktorá sa má použiť.
Služba prekladateľa je služba Azure hosťovaná v dátových centrách spoločnosti Microsoft a využíva výhody zabezpečenia, škálovateľnosti, spoľahlivosti a dostupnosti, ktorú tiež dostávajú iné cloudové služby spoločnosti Microsoft.
Preklad reči
Prekladateľská technológia prekladu reči bola spustená koncom roka 2014 počnúc Skype Translator a je k dispozícii ako otvorené API pre zákazníkov od začiatku roka 2016. Je integrovaný do živej funkcie Microsoft Translator, Skypu, vysielania schôdze cez Skype a aplikácií Microsoft Translator pre Android a iOS.
Preklad reči je teraz k dispozícii prostredníctvom programu Microsoft Speech, koncového súboru plne prispôsobiteľných služieb pre rozpoznávanie reči, preklad reči a syntézu reči (text-to-speech).
Ako funguje preklad textu?
Existujú dva hlavné technológie používané pre preklad textu: dedičstvo jeden, štatistický strojový preklad (SMT), a novšie generácie jeden, neurónové strojový preklad (NMT).
Štatistický strojový preklad
Prekladateľ implementácia štatistického strojového prekladu (SMT) je postavená na viac ako desať rokov prirodzeného jazyka-výskum v spoločnosti Microsoft. Skôr než písanie ručne remeselnícky pravidlá preložiť medzi jazykmi, moderné prekladateľské systémy prístup prekladu ako problém učenia transformácie textu medzi jazykmi z existujúcich ľudských prekladov a využitie nedávneho pokroku v aplikovaných štatistík a strojového učenia.
Takzvaný "paralelný corpora" pôsobí ako moderný Rosetta kameň v masívnej proporcie, ktoré poskytujú slovo, frázy, a idiomatické preklady v kontexte pre mnoho jazykových párov a domén. Štatistické modelovacie techniky a efektívne algoritmy pomáhajú počítaču riešiť problém deciferment (detekcia korešpondencie medzi zdrojovým a cieľovým jazykom v údajoch o tréningu) a dekódovanie (nájdenie najlepšieho prekladu novej vstupnej vety). Prekladateľ spája silu štatistických metód s jazykovými informáciami na výrobu modelov, ktoré generalizujú lepšie a vedú k zrozumiteľnejším prekladom.
Z dôvodu tohto prístupu, ktorý sa nespolieha na slovníky alebo gramatické pravidlá, poskytuje najlepšie preklady viet, kde je možné použiť kontext okolo daného slova versus snaží vykonávať jediné slovo preklady. Pre jednotlivé slová preklady, bol vyvinutý Dvojjazyčný slovník a je prístupný prostredníctvom www.Bing.com/Translator.
Neurónové strojový preklad
Neustále vylepšenia prekladu sú dôležité. Avšak, zlepšenie výkonu majú plateaued s SMT technológie od polovice 2010s. Využitím rozsahu a výkonu spoločnosti Microsoft AI Supercomputer, konkrétne Microsoft kognitívne Toolkit, prekladateľ teraz ponúka neurónové siete (V MESTE LSTM) založený preklad, ktorý umožňuje nové desaťročie zlepšenie kvality prekladu.
Tieto neurónové sieťové modely sú k dispozícii pre všetky reči jazykov prostredníctvom služby reč na Azure a prostredníctvom textového API pomocou "generalnn" Kategória ID.
Neurónové siete preklady zásadne líšia v tom, ako sú vykonávané v porovnaní s tradičnými SMT ty.
Nasledujúca animácia zachytáva rôzne kroky neurónové siete preklady prejsť preložiť vetu. Vzhľadom k tomuto prístupu, bude preklad vziať do kontextu plnú vetu, versus len pár slov posuvné okno, ktoré SMT technológie používa a bude produkovať viac tekutín a človek-preložené hľadá preklady.
Na základe školenia neurónové siete, každé slovo je kódovaný pozdĺž 500-rozmery vektor (a), ktoré predstavujú jeho jedinečné vlastnosti v rámci konkrétneho jazyka páru (napr. angličtina a čínština). Na základe jazykových párov používaných na školenie, neurónové siete budú self-definovať, čo tieto rozmery by mali byť. Mohli kódovať jednoduché pojmy ako pohlavie (ženský, mužský, neutrálny), úroveň zdvorilosti (slang, ležérne, písomné, formálne, atď.), typ slova (sloveso, podstatné meno atď.), ale aj akékoľvek iné nezjavné charakteristiky odvodené z tréningových údajov.
Kroky neurónové siete preklady prechádzajú, sú nasledovné:
- Každé slovo, alebo konkrétnejšie 500-rozmer vektor zastupujúci to, prechádza prvou vrstvou "neurónov", ktorý bude kódovať to v 1000-rozmer vektor (b) predstavujúce slovo v kontexte ostatných slov vo vete.
- Akonáhle všetky slová boli kódované jeden čas do týchto 1000-rozmer vektory, proces sa opakuje niekoľkokrát, každá vrstva umožňuje lepšie doladenie tohto 1000-rozmer vyobrazenie slova v rámci celej vety (na rozdiel od SMT Technológia, ktorá môže brať do úvahy len 3 až 5 slov okno)
- Konečná výstupná matica je potom používaná vrstvou pozornosti (t. j. softvérový algoritmus), ktorý bude používať túto konečnú výstupnú maticu a výstup predtým preložených slov na definovanie toho, ktoré slovo od zdrojovej vety by malo byť preložené ďalej. Bude tiež používať tieto výpočty potenciálne pokles zbytočné slová v cieľovom jazyku.
- Dekodér (preklad) vrstva, prekladá vybrané slovo (alebo presnejšie 1000-rozmer vektor predstavujúce toto slovo v rámci celej vety) v jeho najvhodnejšej cieľový jazyk ekvivalent. Výstup tejto poslednej vrstvy (c) sa potom privádza späť do vrstvy pozornosti, aby sa vypočítal, ktoré ďalšie slovo zo zdrojovej vety by sa malo preložiť.

V príklade znázornený v animácii, kontext-Aware 1000-rozmer model "na"bude kódovať, že podstatné meno (House) je ženské slovo vo francúzštine (La Maison). Tým sa umožní vhodný preklad pre "na"byť"La"a nie"Le"(singulární, muži) alebo"Les"(množné číslo), akonáhle dosiahne dekodér (preklad) vrstvu.
Pozornosť algoritmus bude tiež počítať, na základe slova (y) predtým preložené (v tomto prípade "na"), že ďalšie slovo, ktoré majú byť preložené by malo byť predmetom ("House") a nie prídavné meno ("Blue"). V môže dosiahnuť, pretože systém sa dozvedel, že angličtina a francúzština Invertovať poradie týchto slov vo vetách. To by tiež vypočítala, že v prípade, že prídavné meno malo byť "Veľký"namiesto farby, že by nemal Invertovať je ("veľký dom"= >"La Grande Maison").
Vďaka tomuto prístupu je konečná produkcia vo väčšine prípadov plynulejšia a bližšie k ľudskému prekladu, ako by mohol mať niekedy aj preklad založený na SMT.
Ako funguje preklad reči?
Prekladateľ je tiež schopný prekladať reč. Táto technológia je vystavená v prekladači Live Feature (http://translate.it), Prekladač Apps, Skype Translator a je tiež spočiatku k dispozícii iba prostredníctvom funkcie Skype Translator a Microsoft Translator Apps na iOS a Android, táto funkcia je teraz k dispozícii vývojárom s najnovšou verziou otvoreného REST-based API k dispozícii na portáli Azure.
Hoci sa to môže zdať ako priamočiare proces na prvý pohľad na vybudovanie technológie reči prekladu z existujúcej technológie tehál, to vyžadovalo oveľa viac práce, ako jednoducho zapojiť existujúce "tradičné" človek-k-stroj rozpoznávanie reči na existujúci text prekladu jeden.
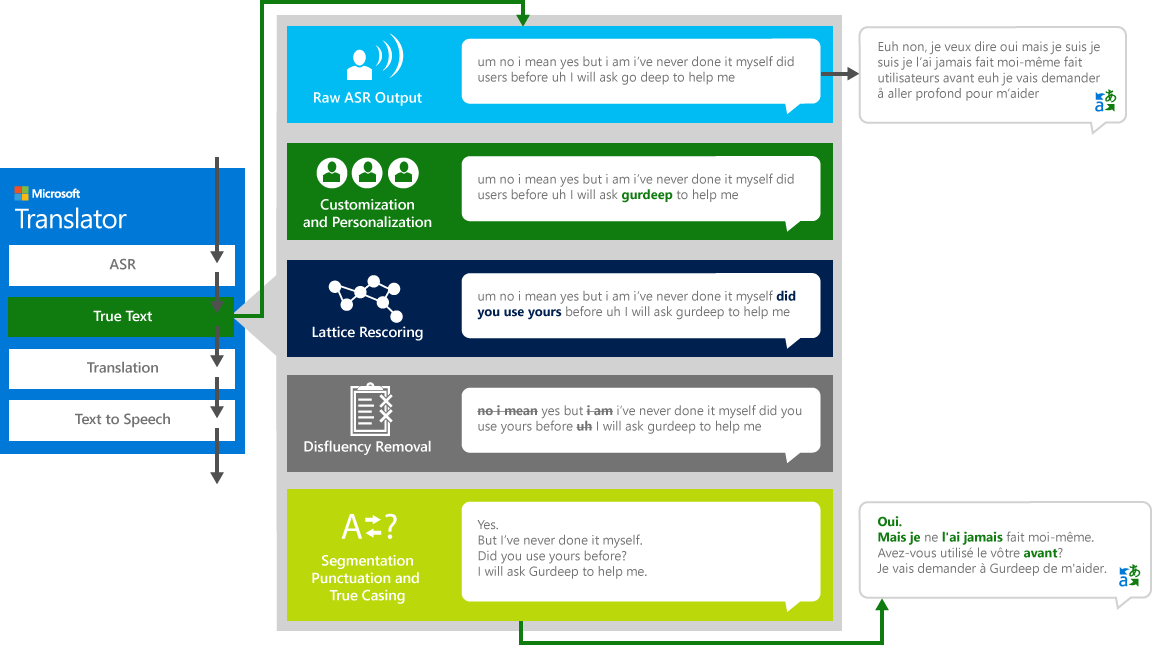
Ak chcete správne preložiť "zdroj" reči z jedného jazyka do iného "cieľový" jazyk, systém prechádza štyri-krokom procesu.
- Rozpoznávanie reči, konverzia zvuku do textu
- TrueText: technológia spoločnosti Microsoft, ktorá normalizuje text, aby bolo vhodnejšie pre preklad
- Preklad cez text prekladu motora popísané vyššie, ale na preklad modely špeciálne vyvinuté pre reálny život hovorené rozhovory
- Text-to-speech, ak je to potrebné, na výrobu preloženého zvuku.

Automatické rozpoznávanie reči (ASR)
Automatické rozpoznávanie reči (ASR) sa vykonáva pomocou neurónové siete (NN) systém vyškolení na analýzu tisíce hodín prichádzajúce audio reči. Tento model je vyškolený na človeka-na-ľudskej interakcie skôr ako človek-na-stroj príkazy, produkovať rozpoznávanie reči, ktorý je optimalizovaný pre bežné konverzácie. Na dosiahnutie tohto cieľa, je potrebné oveľa viac údajov, rovnako ako väčšie DNN ako tradičné človeka-k-stroj ASRs.
Ďalšie informácie o Reč Microsoftu na textové služby.
PlatíText
Ako ľudia konverzačné s inými ľuďmi, nebudeme hovoriť ako dokonale, jasne alebo úhľadne, ako sme často myslíme, že robíme. S technológiou TrueText je doslovný text transformovaný tak, aby užšie odrážal používateľský zámer odstránením rozptýľovania reči (výplň slov), ako napríklad "UM" s, "Ah" s, "a" s, "ako" s, zasekáva a opakovania. Text je tiež čitateľný a prekladateľný pridaním vety prestávky, správne interpunkcia, a kapitalizácie. Na dosiahnutie týchto výsledkov sme použili desaťročia práce na jazykových technológiách, sme vyvinuli od prekladateľ vytvoriť TrueText. Nasledujúci diagram zobrazuje prostredníctvom reálneho života príklad, rôzne transformácie TrueText pracuje na normalizovať tento doslovný text.
Preklad
Text sa potom preloží do niektorého z jazyky a dialekty podporovaný prekladateľom.
Preklady pomocou API na preklad reči (ako vývojár) alebo v aplikácii alebo službe na preklad reči sú poháňané najnovšími prekladmi založenými na neurálnej sieti pre všetky jazyky podporované reči (pozri tu pre úplný zoznam). Tieto modely boli tiež postavené rozšírením súčasných, väčšinou písaný text-vyškolení prekladové modely, s viac hovorený-text corpora vybudovať lepší model pre hovorené konverzácie typy prekladov. Tieto modely sú dostupné aj prostredníctvom štandardná kategória "reč" tradičného textového prekladu API.
Pre všetky jazyky, ktoré nepodporujú neurónové preklady, sa vykonáva tradičný preklad SMT.
Text na reč
Ak je cieľovým jazykom jeden z 18 podporovaných textov na reč Jazykya prípad použitia vyžaduje zvukový výstup, text sa potom prevedie na hlasový výstup pomocou syntézy reči. Táto fáza sa vynechá v scenároch prekladu reči na text.
Ďalšie informácie o Text spoločnosti Microsoft na reč služby.
Výskum
Pozrite si najnovšie výskumné dokumenty z tímu Microsoft Translator.



