


How to manage Sensitive Data in Cloud Analytics Platforms

Managing Sensitive Data is one of the most important challenges organisations face these days. Data breaches are an ever-increasing threat to every industry that needs to be protected against both internal and external threats. 2021 saw the highest average cost of a data breach in 17 years.
In this article we will take a look at what are the main considerations, strategies and an architecture example on how to manage Sensitive Data in a multi-component Cloud Analytics Platform, which as we will see is a complex task but in our post-GDPR days is absolutely essential for the success of any organisation that deals with Sensitive Data.
We know that if you need to manage sensitive data in a simple analytics platform with only one central component like for example data stored in an RDBMS like Azure SQL there are plenty of built-in mechanisms that we can leverage, for example Column Level Encryption, Data Masking, Transparent Data Encryption, and others. However, the reality is that, in most cases, organisations work with Analytics Platforms that involve more than one component, for example a Modern Cloud Analytics Data Platform could include a Data Lake Storage likes ADLS, Azure Synapse, a Spark Engine like Synapse Spark or Databricks, etc.
So how can we build modern analytics platform that deliver value to the business while properly managing Sensitive Data and being compliant with strict security and privacy policies, sector regulation and regional laws? Let’s take a look.
The Data
First of all we need to define what do we mean by sensitive data.
In the context of GDPR: “data consisting of racial or ethnic origin, political opinions, religious or philosophical beliefs, or trade union membership, genetic data, biometric data, data concerning health or data concerning a natural person’s sex life or sexual orientation.”
However, not all sensitive data is personal data. We could be talking about data that is confidential because it may have an impact on the share price of the organisation for example.
Another important consideration is that sensitive data will sit probably within multiple business areas, sometimes on premises as well as the cloud, in new systems as well as legacy ones, etc.
So, the first step will be to define what data is sensitive in the context of our organisation and where it is currently stored taking into consideration all the relevant viewpoints: data protection laws for personal data, for customers but also for the employees, data that is confidential for our organisation like intellectual property, trade secrets, etc. In essence: any data that must be protected from a privacy standpoint.
It is very helpful if the organisation has already a Data Classification framework in place as we will be able to use it as a foundation for our data strategy. In particular, we will need to have defined a set of sensitivity labels to classify the universe of data available. If the organisation doesn’t have one yet, I would strongly recommend focusing on building one as initial step. It’s not a simple process, and we will need to involve a broad audience within the organisation, but it will be essential for the success of any analytics platform that manages sensitive data.
More information on how to build a well-designed Data Classification Framework can be found here.
Once we have defined our Data Classification policies we will need a Unified Data Governance solution like Azure Purview to manage the discovery and classification of our data assets.
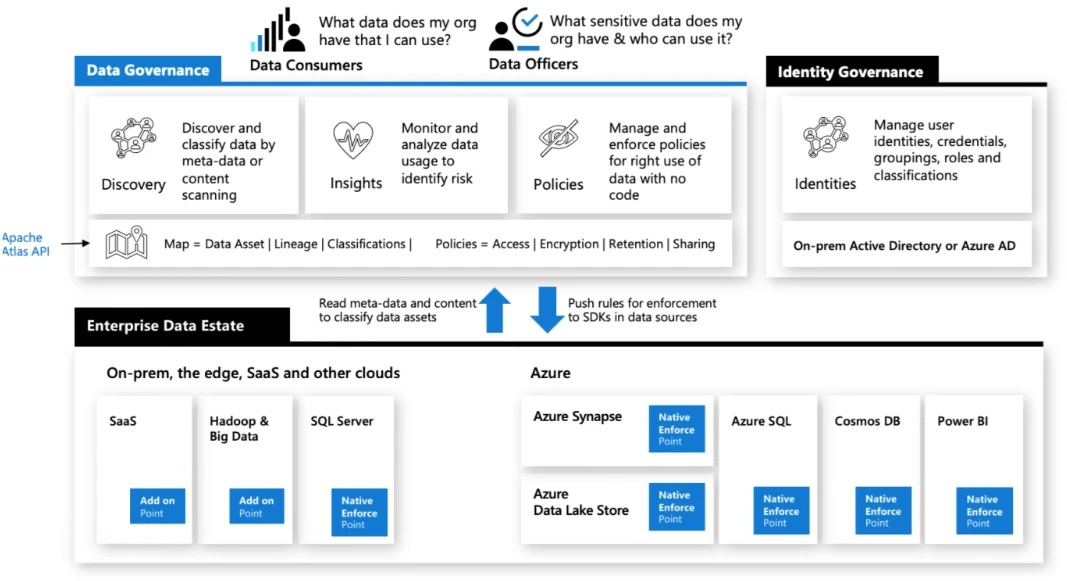
Features like Purview Sensitivity Label Insights (currently in Preview) will enable us to classify and label datasets based on their level of sensitivity as well as to obtain insights on how many assets we have from each category:
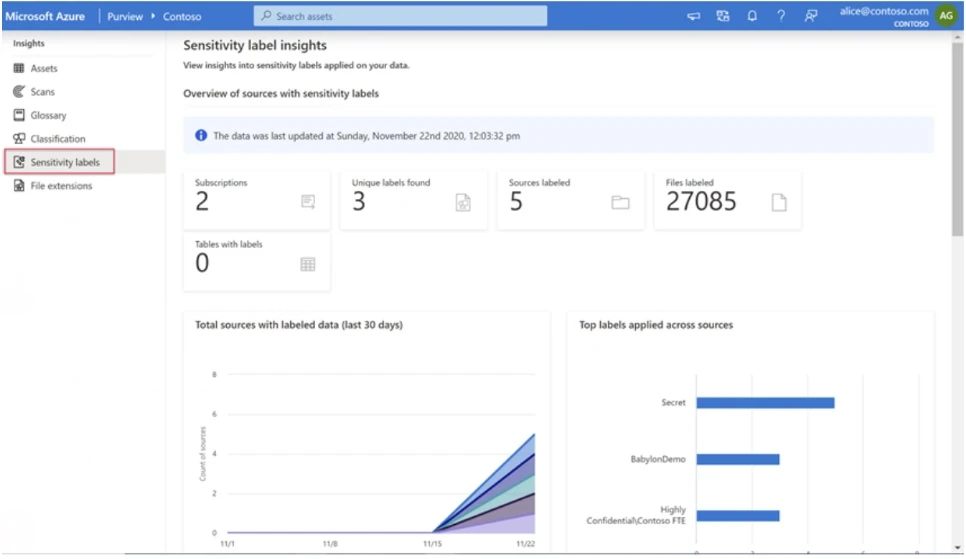
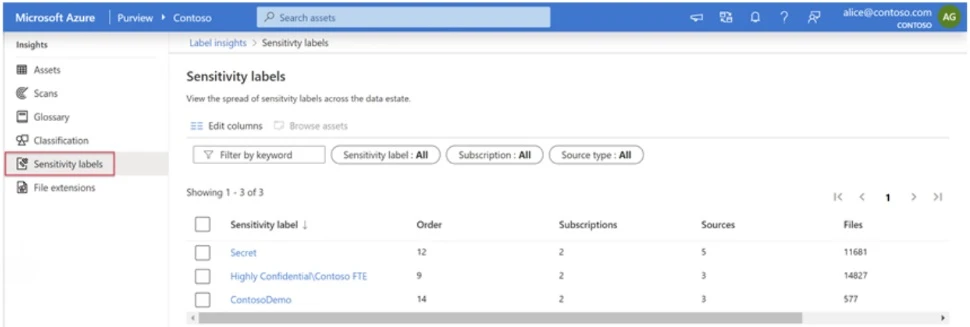
The Challenge
It is essential to have a clear view on what the challenges for building this type of analytics platform are. In some instances, one challenge when building an Analytics Platform that will manage Sensitive Data is the perception of some organisations that it is harder to ensure data privacy and security in the cloud. In Microsoft we have available plenty of documentation and white papers that cover this topic in-depth and Azure is leading the industry with more than 90 compliance certifications, including over 50 specific to global regions and countries and more than 35 compliance offerings specific to the needs of key industries, including health, government, finance, education, manufacturing and media. Here are some examples:

One of the main challenges from a Data Privacy standpoint is the threat of data exfiltration, in particular around the figure of the malicious or negligent insider (an employee that intentionally or by mistake exfiltrates data outside the organisation, typically financial or personal data). This is one of the most complex scenarios because we are looking at protecting sensitive data from people that actually should have access to the data assets. For example, let’s imagine a scenario where we are storing customer data including a column with credit card information (unencrypted) in a relational database, and we are using a Data Masking mechanism which exposes the last four digits and adds a constant string as a prefix in the form of a credit card (e.g. XXXX-XXXX-XXXX-1234). This would be effective for data consumers querying the data, however in the unfortunate (and hopefully unlikely) scenario of the database admin being the malicious insider this mechanism wouldn’t be effective because they would have direct access to the unencrypted data in the database.
There are some ways to mitigate this, however it is important to bear in mind that very often when we are talking about data privacy, People and Processes are more effective than Technology controls. Also, it is important for any organisation to define their level of risk appetite when building security and privacy controls for any system that manages data.
Frequently increased privacy control also means increased complexity, for example we will see below in this article that one effective strategy to tackle the malicious/negligent insider threat is to use a Data Obfuscation strategy, however this often increases the complexity of the architecture, especially in a multi-component analytics data platform, as we will need to keep a consistent obfuscation strategy through the whole end to end data workflow.
Common Strategies
Next step will be to define the data privacy strategy for our platform, the most common ones for managing sensitive data in an analytics platform are the following:

- Data Obfuscation is the process of modifying sensitive data in such a way that it is of no or little value to unauthorized intruders. There are different techniques to obfuscate data like Encryption, Tokenization or Masking, all of them with their trade-offs:
- Data Encryption uses mathematical techniques and an encryption key to temporarily encode the data, making it unreadable to anyone who doesn’t have the decryption key. Encryption is one of the most common method of keeping sensitive information secure. The encryption will be as strong as the key and the algorithm used, so a more complex algorithm will be harder to crack and therefore more secure. This technique is very secure, however it is important to bear in mind that at least theoretically no algorithm is completely unbreakable.
- Data Tokenisation is similar to encryption, however instead of using an algorithm we use a tokenisation technique that replaces sensitive data with a randomly generated token. Because the original information is not contained within the token, which is in essence a placeholder, a potential attacker wouldn’t have any way to decode the sensitive data. This method is very secure but it requires to maintain lookup tables with sensitive data creating more architectural complexity and maintenance overhead.
- Data Masking consists in replacing the original data with realistic but false one to ensure privacy. It is used to allow for testing, training, application development and others. Something to keep in mind is that normally Data Masking is applied while consuming the data rather that at the storage level, making it more vulnerable to data exfiltration on a Malicious / Negligent Insider scenario.
In general, we can say that Data Obfuscation it’s an effective strategy to keep sensitive data secure while allowing data analysts and data scientists to perform (most) analytics Use Cases. On the other hand, it increases the complexity of our solution as we will need to ensure that the data is obfuscated before entering the platform and that the different components will be able to work with obfuscated data in a cohesive fashion.
We will also need to ensure that data can be de-obfuscated if and when required. Depending on the type of obfuscation that we use, for example if we want to use Data Tokenization, we will also need to rely on third parties potentially adding some vendor lock in into our design. And finally, we should also keep in mind that any type of encoding and decoding process will have ultimately an impact on performance.
- Data Segregation consists in separating the sensitive from the non-sensitive data and storing it in different data stores. This will allow us to keep different security controls for the data assets depending on its level of sensitivity, for example we could use two different Azure Data Lake Storages under separate Azure Subscriptions (one for Non sensitive and one for Sensitive data), and then ensure that only accounts approved by the organisation’s Privacy and Security teams have access to the Sensitive Data Lake storage. This approach gives us a very high degree of flexibility with a relative low effort. On the other hand, it will increase the complexity of the solution albeit not as much as other options like Tokenization. We will also have to keep extra attention to our data modelling strategy and how to join datasets that will physically sit in separate locations.
- Not bringing sensitive data to the Data Platform is also a valid and common option, and it’s actually the safest one. However, it is not a feasible approach in many scenarios as some Data Platforms will require ingesting, storing and analysing Sensitive Data. In any case I would recommend conducting an exercise during the design phase to explore (and challenge) if it is completely necessary (or even a good idea) bringing sensitive data to the Analytics Solution you are building. It turns out that in many cases, like in most Analytics Data Lakes, bringing Sensitive Data is not 100% required to fulfil the Business Use Cases.
Example: Architecture using Data Encryption and Data Segregation
And finally, we will start working on designing a solution. This step will depend heavily on the specific scenario, business Use Cases, skillset of the team and others. Below you can see an example of an architecture that combines Data Obfuscation and Segregation to ensure complete privacy for our sensitive data:
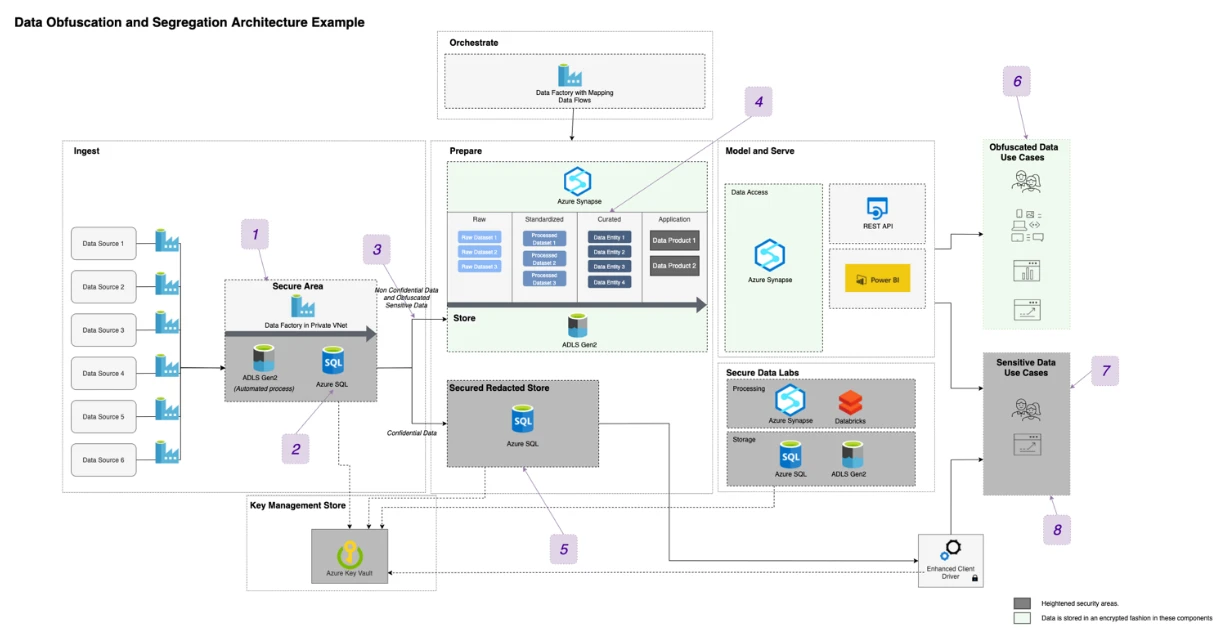
- First we ingest data from the different data sources into the Secure Area, this area is a completely isolated DMZ (ideally no human should have access).
- We will use Azure Data Factory pipelines to bring the source data to the Data Obfuscation component (in this case Azure SQL). Why are we using Azure SQL as a Data Obfuscation component? There are few reasons but the main one is for simplicity: We won’t need any third party tools, we have access to it in the Azure Portal, it’s easy to deploy with a couple of clicks and it will provide us with native and strong Data Encryption features, in this architecture we will use Azure SQL Always Encrypted on the selected sensitive columns. Always Encrypted is a feature designed to protect sensitive data stored in Azure SQL and allows us to encrypt data inside client applications and never reveal the encryption keys to the Database Engine. This will provide a separation between those who own the data and can view it, and those who manage it but should have no access to the unencrypted data. As a result, we are ensuring on-premises database administrators, cloud database operators, or other high-privileged unauthorized users, can’t access the encrypted data, and therefore protecting the sensitive fields from a Malicious/Negligent Insider threat. At this stage we will encrypt the columns with sensitive data and will export the results to the Data Lake in the form of Parquet files.
- Data will land into the regular access Data Platform (green areas), all the columns that contain Sensitive data will have been encrypted during the previous step. No user will be able to decrypt the data unless they have the right keys that have been securely stored in Azure Key Vault.
- Because sensitive data has been encrypted using a deterministic algorithm it is possible run analytics workloads (including joining tables) on obfuscated data while keeping referential integrity.
- A copy of the Sensitive data is stored on the Secured Redacted Store (using Column Level Encryption) for those Use Cases that will require access to the unencrypted sensitive data. Physically, this could be a separate Azure SQL instance than the one we use in the Secure Area or it could be the same one depending on our security requirements.
- Data Consumers can run analytics or operational workloads on data that has been obfuscated, the only difference is that they won’t be able to see the actual value, they will see instead an encrypted literal.
- However, this architecture should allow also for those Use Cases that will require actual access to the sensitive data in its unencrypted form. This could include for example an automated process that processes or analyses sensitive data without human interaction or the development and creation of data assets by data engineers who will, in some cases, require access to sensitive data to ensure the quality of the assets. In any case these Use Cases will have to be validated by the Privacy and Security teams to ensure compliance and access will be granted following the organisation’s data governance and security internal processes.
- Data Consumers that have special permission to perform analytics or operational workloads have access to both the regular Serving Layer and the Secured Redacted Store.
Considerations
These are some considerations that should be taken into account when building an Analytics Platform that will manage Sensitive Data:
- The Cloud IS SAFE: One of the first considerations to take into account is that the cloud is safe. This conversation is outside the scope of this article, but I would recommend taking a look at some of our security available resources.
- End to End compliance: Also, it is important to be aware that the real challenge as I explained above is not to manage Sensitive data in the Cloud but to manage Sensitive data in a complex (multi-component) analytics platform.
- Sensitive data is NOT ONLY PII data: It is common to mix the concepts of Sensitive Data, Confidential Data and PII data but it is important to understand that they are not the same thing.
- Data Governance, Strategy and Process > Technical Security controls: Having a defined Data Governance strategy is the single most effective tool to protect our sensitive data. This is not to say that establishing effective technical security controls is not important, but without a clear Data Governance with strict Data Policies and Data Privacy strategies defined at an organisation level technology itself will render useless.
- Data Classification Policy: It is crucial that our Data Privacy strategy includes a defined Data Classification Framework widely adopted in the organisation. If we don’t know which data is sensitive we will have to treat all the data as sensitive.
-=-
I’m a Cloud Solution Architect specialised on Data & AI. During the last 15 years I’ve been designing, building and implementing data platforms for many organisations across most verticals. My background is on Analytics, Data Governance, Enterprise Architecture and Big Data. Outside work I spend most of my time making music and running a small record label.


