
Behind the Scenes – What it Takes to Teach GPT-3 How to Build Low-Code Apps
Introduction
Last year, we announced the public preview of Power Apps Ideas, which enables Power Apps makers to take advantage of Microsoft AI technologies that make it easy to write Power Fx formulas with no-code. In this article, we’re going to go behind the scenes to share what it took for the Power Apps engineering team to implement Power Apps Ideas and unveil some of the complexity that’s happening under the covers to support this user experience.
Makers often know what they are trying to accomplish when they set out to write a formula (e.g., “show accounts created in the last week”), but it’s not always clear exactly how to do that. Now, with natural language to Power Fx, makers can express what they want in simple language and the Power Fx formula will be generated for them.
Let Power Apps Write the Power Fx For You! – Power CAT Live – YouTube
With natural language to Power Fx, makers of all skill levels can benefit from the ability to write formulas with ease and accessing the full spectrum of features available in Power Apps. In this article, let’s take a closer look at the magic that happens under the hood.
Behind the Scenes
The core technology powering this feature is GPT-3 (Generative Pre-trained Transformer 3), a sophisticated language model that uses deep learning to produce human-like text. GPT-3 is now available in preview by invitation as part of Microsoft’s Azure OpenAI Service.

In addition, there are several other key components involved in the process. These core pieces are part of the Power Platform AI Services (hosted in Azure Service Fabric), which provides a shared infrastructure for Power Platform products that want to leverage AI capabilities like GPT-3.
This article is going to focus specifically on Power Apps and the conversion of natural language to Power Fx, but in future articles, we will also share how other teams in Power Platform are using the same infrastructure to incorporate AI features into their products.
Let’s walk through the process in detail using a concrete example.
Sample Use-Case
Suppose you have a gallery that displays records from the table (Customers) and a text input control (TextSearchBox1). You want to take the text from that input control and search the records in your gallery by a specific column (Full Name). But how exactly do you do that?
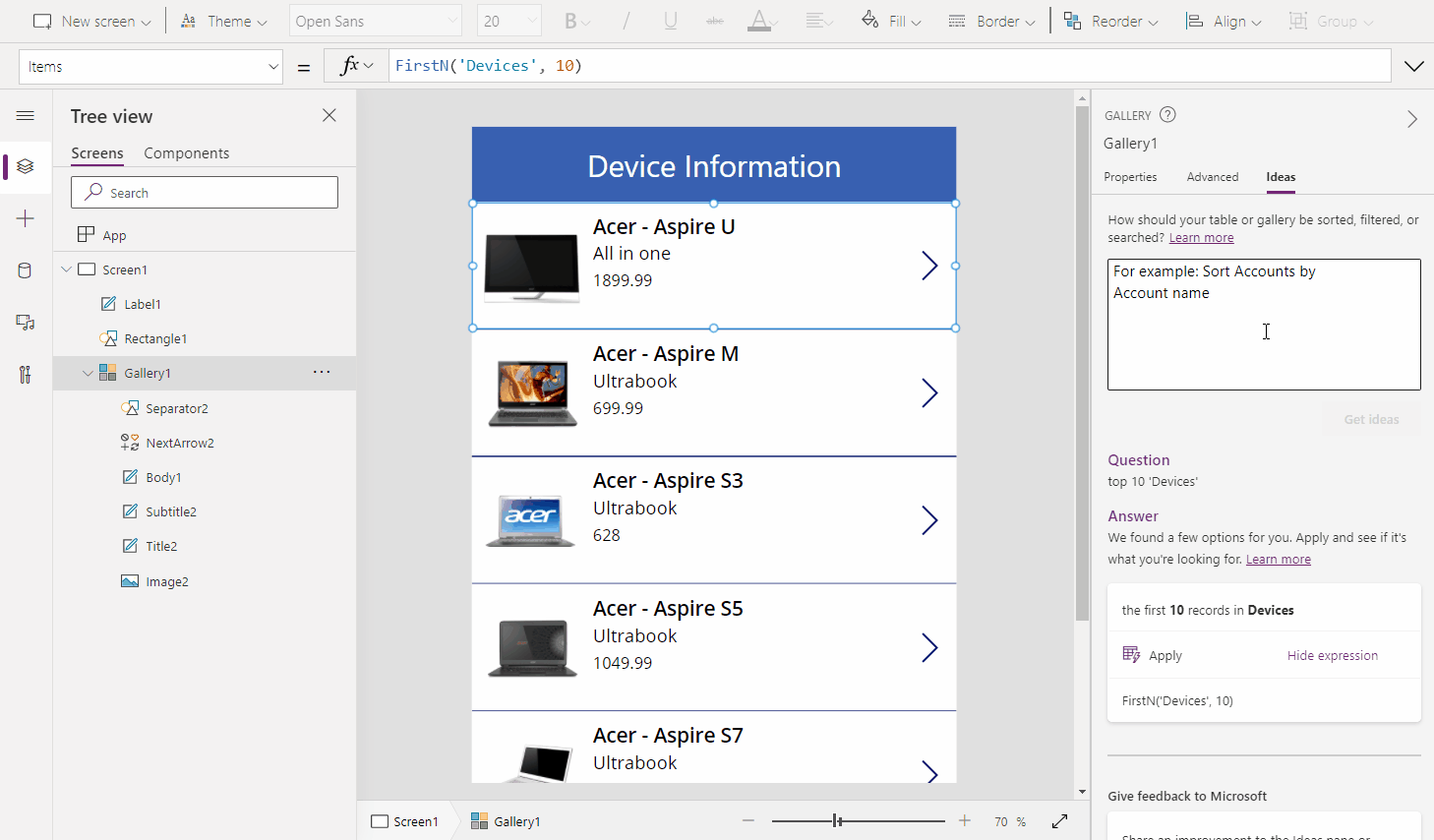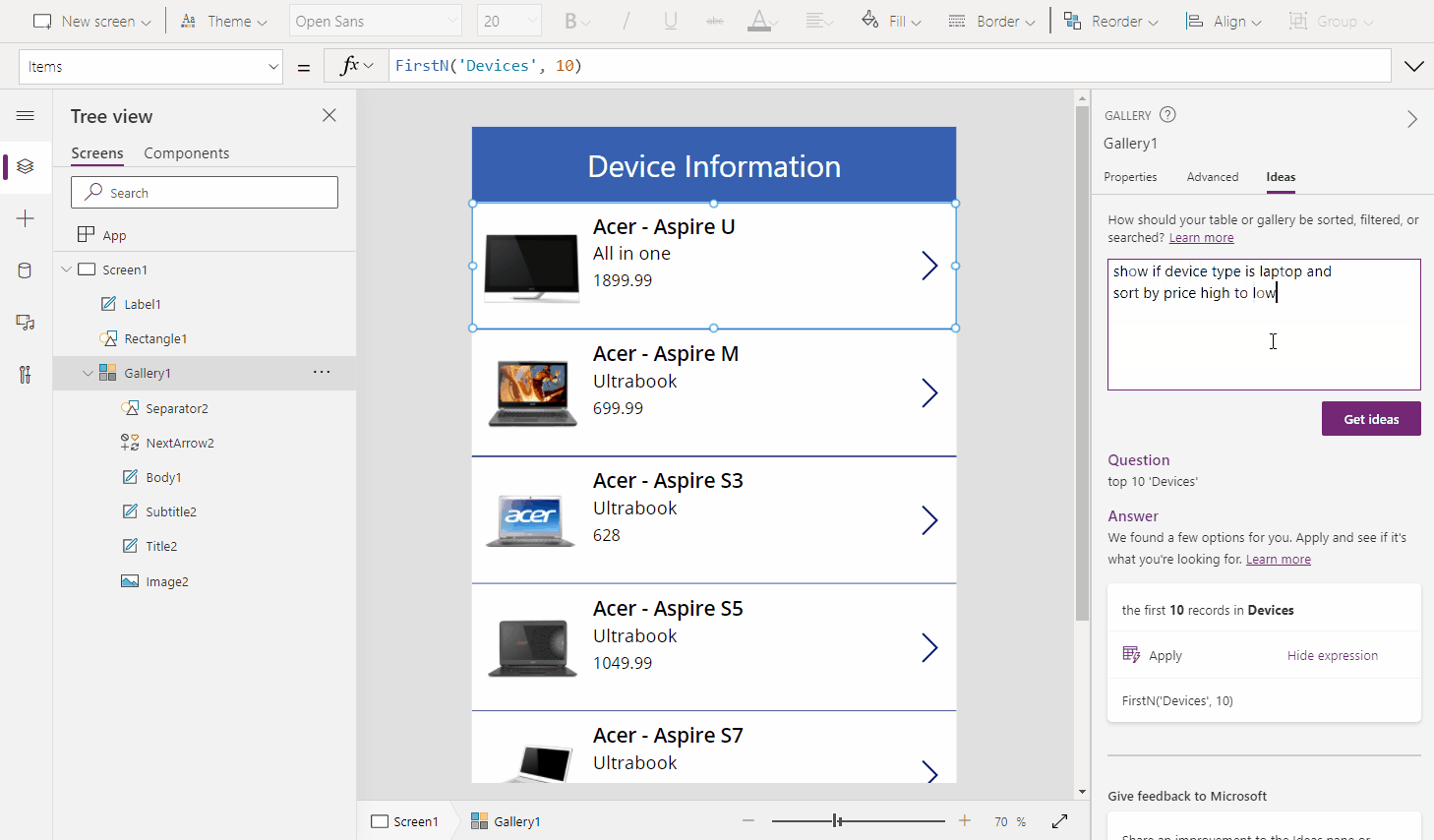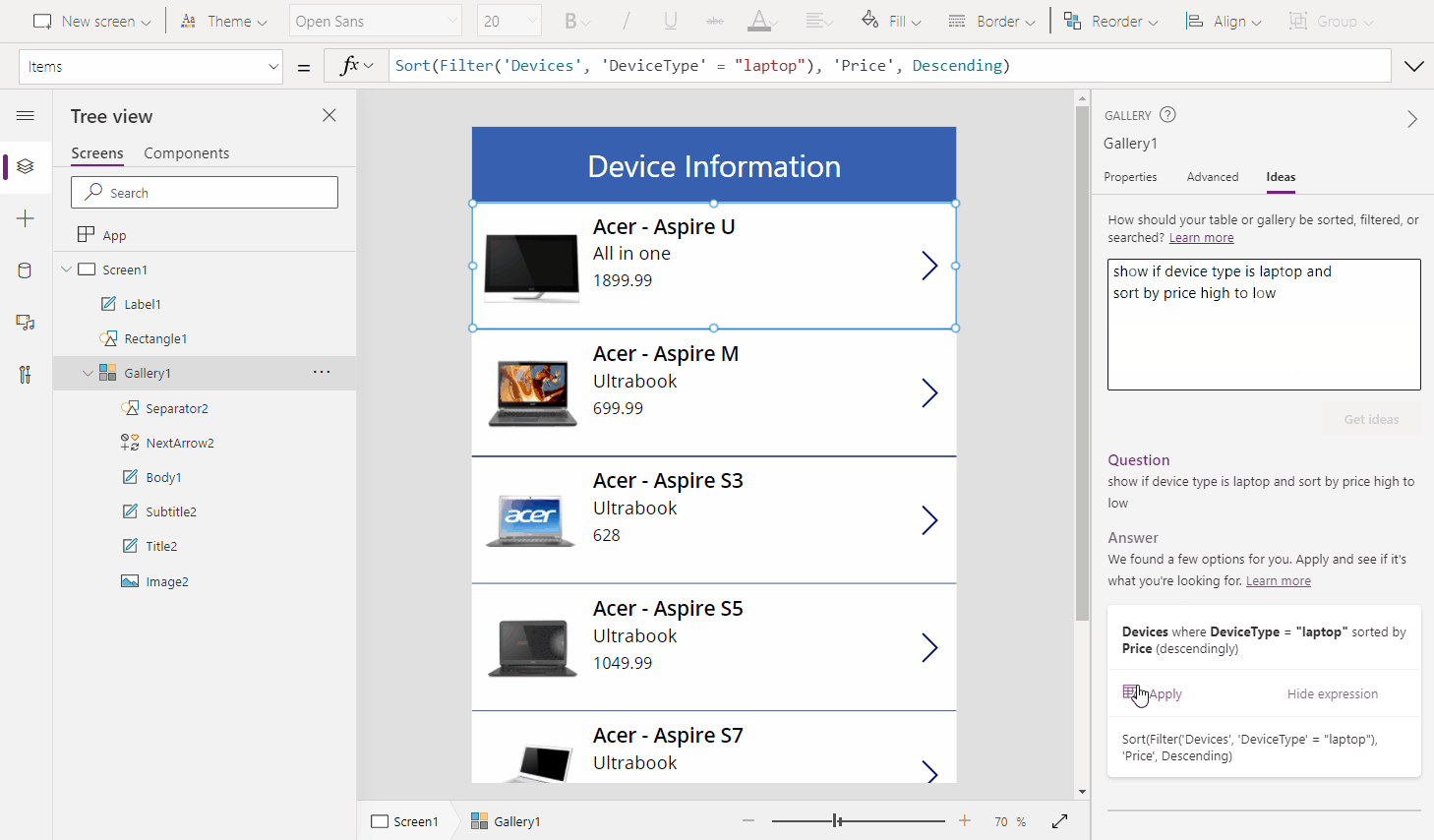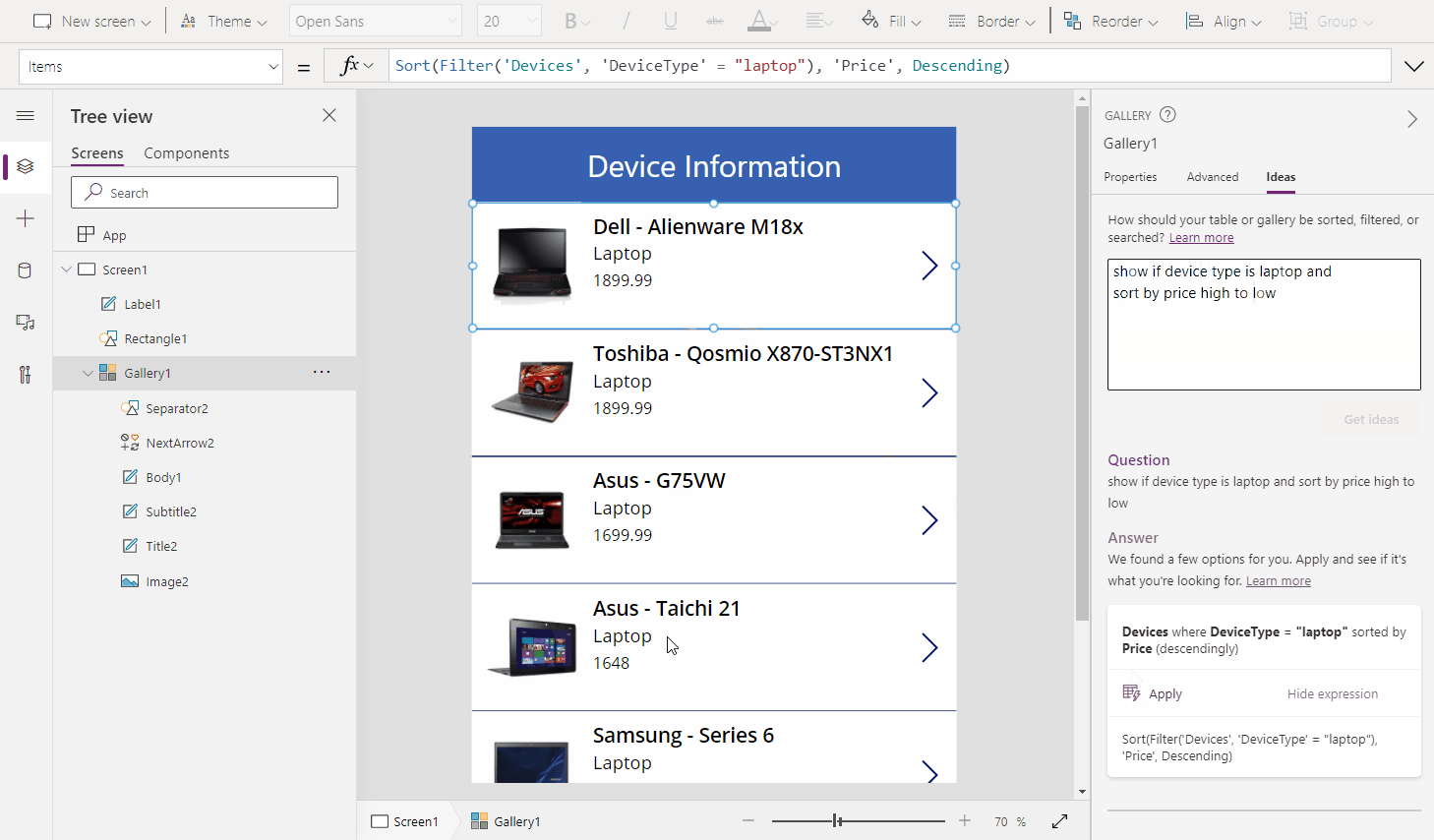
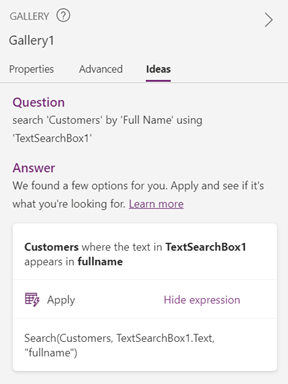
With natural language to Power Fx, you can select the gallery control, click the “Ideas” pane on the right, type in what you are trying to do, then click “Get ideas”.
Input: search ‘Customers’ by ‘Full Name’ using ‘TextSearchBox1’
Client-Side Input
Step #1: Gathering the Input and Context
After clicking “Get ideas”, the natural language query, along with the Power Apps context, is sent to Power Platform AI Services for pre-processing. The Power Apps context provides important information that contextualizes the natural language query and helps generate more accurate formulas.
| Natural Language | search ‘Customers’ by ‘Full Name’ using ‘TextSearchBox1’ |
| Power Apps Context | Controls: [{ Name: “TextSearchBox1”, Type: “TextInput” }] |
| Tables: [{ Name: “Customers”, Columns: [{ DataType: “Text”, DisplayName: “Full Name”, LogicalName: “fullname” }] }] |
In the example above, we can see that Customers is the name of a table, Full Name is the name of a column in that table, and TextSearchBox1 is the name of a text input control.
Pre-Processing
Step #2: Filtering the Content
The first step in the pre-processing stage involves content filtering. In accordance with Microsoft’s principles of Responsible AI, the content is filtered to ensure that the request does not contain any potentially harmful or offensive content. We use two scoring mechanisms for content filtering:
- Hate speech detection – This model, hosted in Azure Machine Learning, is trained to identify inappropriate content (e.g., profanity, violence, hate speech, etc.); it will return a score from 0 to 1 indicating the likelihood that the text contains unsafe content.
- Bad words blocklist – This list contains words that are deemed offensive or vulgar; if a word in this blocklist is found in the text, it will return a score of 1.
If any profanity or inappropriate content is identified, the process is immediately terminated.
Step #3: Masking the Input
Once the content has been filtered, the next step is to mask the input by removing details that are irrelevant to the formula pattern, keeping only the essential information. In other words, whether a control is named “TextSearchBox1” or “MyTextBox” does not matter; what matters is that the control is a text input control with data type string. This is necessary because the GPT-3 model is trained with masked data, so the natural language input string will also need to undergo the same type of transformation to replicate the type of data that the model has been trained on.
Input: search ‘Customers’ by ‘Full Name’ using ‘TextSearchBox1’
Based on the Power Apps context that is sent along with the natural language query, we know that Customers is the name of a table, Full Name is the name of a column with text as the data type, and TextSearchBox1 is the name of a text input control.
Output: search @tn@0 by @dn@0 [ @dn@0, @ln@0, Str ] using @ti@0 [ Str ]
After undergoing the masking process, the unimportant details (e.g., names of tables, columns, and controls) have been removed, but the key information is still present. This significantly reduces the amount of data required to train the model since the pattern is what is actually important to capture – not all the possible variations in naming.
GPT-3 Model
Step #4: Calling the GPT-3 Model
Now that the pre-processing stage is complete, we are ready to send the input to our GPT-3 model for inference. We have a GPT-3 model specifically fine-tuned for this scenario (more details below). We pass the request to the Azure OpenAI Proxy, which directly talks to Microsoft’s Azure OpenAI Service. From here, it will call our GPT-3 model (hosted in Azure Machine Learning) to obtain the output.
Input: search @tn@0 by @dn@0 [ @dn@0, @ln@0, Str ] using @ti@0 [ Str ]
Output: Search(@tn@0, @ti@0.Text, “@ln@0”)
But how exactly does GPT-3 convert the natural language query to a Power Fx formula? Let’s dive deeper to understand more about the progressions in the GPT-3 model that powers this feature.
Fine-Tuning GPT-3 for Power Fx
GPT-3 can perform a wide variety of natural language tasks, but fine-tuning the vanilla GPT-3 model can yield far better results for a specific problem domain. In order to customize the GPT-3 model for Power Fx, we compiled a dataset with examples of natural language text and the corresponding formulas. These examples were then used to train the model to understand and recognize Power Fx syntax and patterns.
Building the Training Dataset
Originally, we started off by scraping examples from public documentation and providing manual examples. However, the quantity of training data proved to be insufficient, so we developed an auto-generator to augment our training set. Given a specific pattern (e.g., “filter X by Y and Z”), the data generator can produce many examples with minor variations in the masked data and Power Apps context, which significantly increases the size of the training dataset.
Using the OpenAI Codex Model
In August 2021, OpenAI announced the introduction of OpenAI Codex, an AI model specifically designed for generating code from natural language. A descendant of GPT-3, Codex understands both natural language and billions of lines of source code from public repositories. This is the model that powers GitHub Copilot, which aims to be an AI assistant for writing code. Our initial AI model was based on the vanilla GPT-3 model, fine-tuned for Power Fx. Now, we have switched to using the new Codex model and have been training it to gain a deeper comprehension of Power Fx.
Leveraging LoRA for GPT-3
Given the enormous size of the pre-trained GPT-3 model, which includes 175 billion machine learning parameters that can be fine-tuned, it can become increasingly expensive to train and deploy these large-scale models. To tackle this problem, we use LoRA: Low-Rank Adaptation of Large Language Models, a new method for training GPT-3.
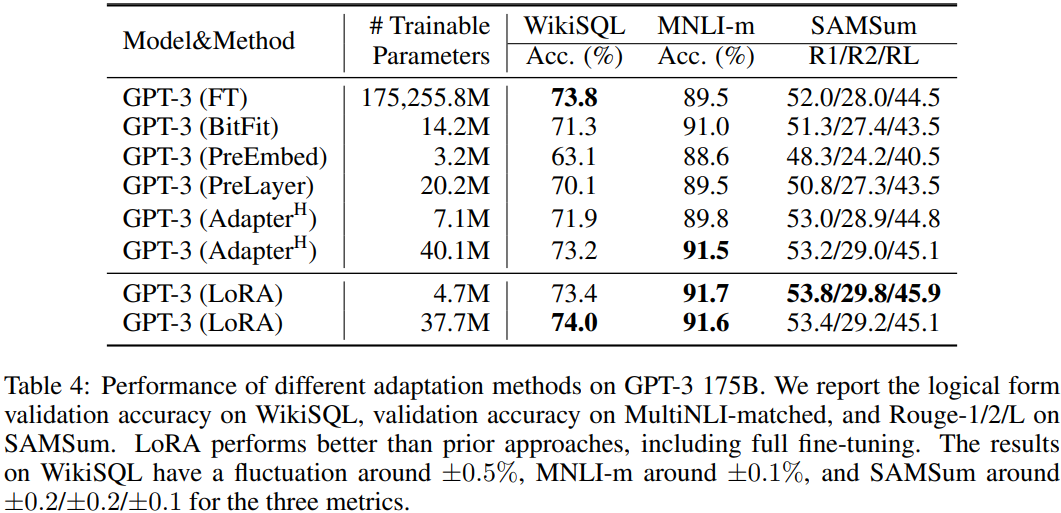
As we can see in the table above, despite having far fewer trainable parameters compared to the fully fine-tuned model, LoRA matches or even exceeds the performance baseline across all three validation datasets.
Compared to traditional methods, LoRA provides two distinct advantages:
- Efficiency and reduced costs for training – Since the number of trainable parameters can be drastically reduced without compromising the accuracy of the model, training new models becomes much more efficient. This reduces both the storage and hardware requirements: using the 175B model as an example, instead of needing 64 GPUs, you can fine-tune using LoRA with only 16.
- Performance improvements for inference – Traditional methods of fine-tuning involve adding custom layers to the pre-trained model to fit the task at hand. These adapter layers, or external modules, are typically added in a sequential manner, which introduces inference latency. LoRA differs from these classical methods since it can be viewed as adding external modules in a parallel manner; these additional modules can be merged back into the base modules seamlessly, thereby ensuring that no additional inference latency is introduced.

As we can see in the table above, for small batch sizes, the inference latency introduced by adapter layer designs can be quite significant compared to LoRA.
Verifying the Model Quality
In order to ensure that our GPT-3 model is performing as expected, we have a custom training pipeline that regularly runs against the model with thousands of examples to verify that the results are correct, thus acting as an early detection system if there are any anomalies in the model behavior.
Post-Processing
Step #5: Filtering the Content
After we get the results from GPT-3, the post-processing stage begins. Just like in the pre-processor, the first step is to filter the content. Again, we use the same mechanisms: checking the results against the hate speech detection model in Azure and verifying that there are no instances of words in the blocklist. Any inappropriate results are filtered out; the remaining ones proceed to the next step.
Step #6: Repairing the Formula
One observation we made early on was that a large number of formulas generated by GPT-3 were almost correct, but there may have been one or two minor mistakes, such as a missing parenthesis or using double instead of single quotation marks.
| Formula (Before Repair) | Issue |
| Filter(@tn@0, ‘@dn@0’ < @dp@0.SelectedDate))) | Contains extra parentheses |
| Filter(@tn@1, @dn@1 in @dd@1.SelectedText.Value) | Missing single quotations |
Filtering out these “almost there” formulas meant that there were often no results generated, which is not ideal. To solve this problem, we repair these formulas by performing simple operations, such as balancing the parentheses or using the correct quotation marks in that context.
| Formula (After Repair) | Operation |
| Filter(@tn@0, ‘@dn@0’ < @dp@0.SelectedDate) | Removed extra parentheses |
| Filter(@tn@1, ‘@dn@1‘ in @dd@1.SelectedText.Value) | Added single quotations |
By repairing the formulas from GPT-3, we significantly increase the number of valid results produced.
Step #7: Un-masking the Output
In the pre-processing stage, we masked the input data; now, we have to undergo the reverse transformation and un-mask the output. Using the information from the Power Apps context, we fill the names and details of the tables, columns, and controls back into the formula.
Input: Search(@tn@0, @ti@0.Text, “@ln@0”)
Output: Search(Customers, TextSearchBox1.Text, “fullname”)
Step #8: Checking the Syntax
In order to avoid returning an incorrect formula, we validate that the Power Fx formula is indeed correct, thus filtering out the invalid results.
Step #9: Generating a Description
For each formula we output, we also generate a natural language description to accompany it. This brief description helps to de-mystify the results and make sense of what the formula is actually doing. If the output contains more than one formula, this helps to distinguish between formula A vs. formula B.
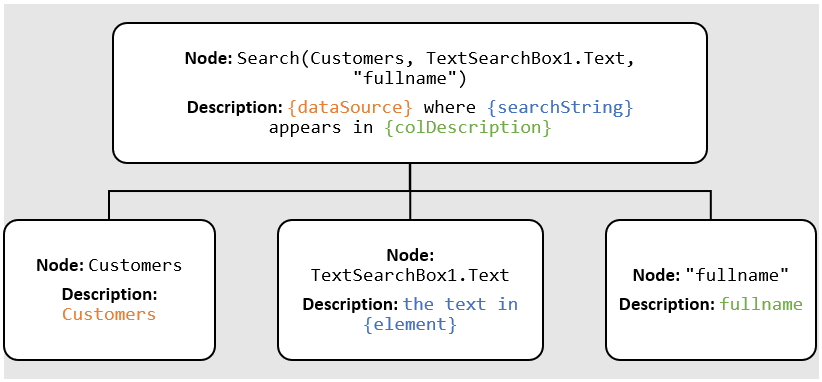
Input: Search(Customers, TextSearchBox1.Text, “fullname”)
Output: Customers where the text in TextSearchBox1 appears in fullname
The description generator takes the input formula and creates an abstract syntax tree that represents the structure of the formula. Then, it will traverse the tree and generate a short description for each node. The final result is the full natural language description of the formula.
Client-Side Output
Step #10: Displaying the Results
Finally, after the post-processing stage is finished, the resulting Power Fx formulas and natural language descriptions are displayed in the frontend. The user can simply click “Apply” to use the formula and see the results. Going back to the sample use-case we started with, we can see that we have successfully built a search functionality for records in the gallery. With the help of Power Apps Ideas, writing Power Fx formulas has never been easier!
Responsible Innovation
Our commitment to uphold Microsoft’s Responsible AI principles and develop AI ethically has been a driving factor in the development of the natural language to Power Fx feature. That means taking a people-centered approach and designing features in a way that puts the user in the driver’s seat at all times.
Power Apps Ideas uses AI technologies to help the user by showing suggested formulas based on the natural language query, but the decision to click and apply the formula ultimately rests with the user, who is always in control.
In addition to producing a Power Fx formula, we also generate a natural language description for each result, which increases transparency and makes the results produced by the AI system understandable. Furthermore, to ensure that our AI systems perform safely, content filtering takes place in both the pre- and post-processor stage to mitigate the risk of producing inappropriate results. We also verify that the GPT-3 model is reliable and behaving as expected by running thousands of examples against the model. By innovating responsibly, we can help build a future where AI technology has a lasting, positive impact.
Conclusion
In this article, we’ve uncovered some of the magic that happens behind the scenes in order to transform natural language into Power Fx formulas. We’ve also demonstrated how the principles of Responsible AI have been a driving force behind the development of this feature.
Natural language to Power Fx represents one major step towards the goal of achieving a no-code platform that empowers everyone to build. As we continue to push the needle towards no-code, we will continue to improve and expand upon our suite of AI-powered features to assist makers in app development. The future is limitless, and we’re building it today.
—
If you have any questions, feedback, or ideas for future topics, let us know in the comments below!
To learn more about engineering at Power Apps, stay tuned for new articles in our “Behind the Scenes” series. If you are interested in exploring career opportunities at Power Apps, check out our Careers page.