
When you build a Power Apps canvas app there are many different data sources you can choose to use such as SharePoint, Microsoft Dataverse, SQL (on-premises), Azure SQL (online), Excel, and others like Oracle. Depending on the data source and connectors you choose in your canvas app, there are different performance optimizations you can apply. On this topic, I would like to focus on the common issues observed and make recommendations on how to solve them.
Data calls from Power Apps canvas apps send data sources via connectors over the OData protocol. OData requests flow to backend layers to reach out the target data source(s) and retrieve data back to the client or commit data in the data source.
How data calls travel in Power Apps
Understanding how OData requests travel in the server-side could help you to optimize your canvas app performance and your backend data sources.
The following diagram, in Figure1, shows how a typical data request in a canvas app (left side) is travelling server-side layers and reaching out a target data source (right side) and then returns the retrieved data back to the client. This is the typical journey of a data request over various connectors, except the Microsoft Dataverse connector. Figure3 visualizes how requests are passed in the Microsoft Dataverse connector.
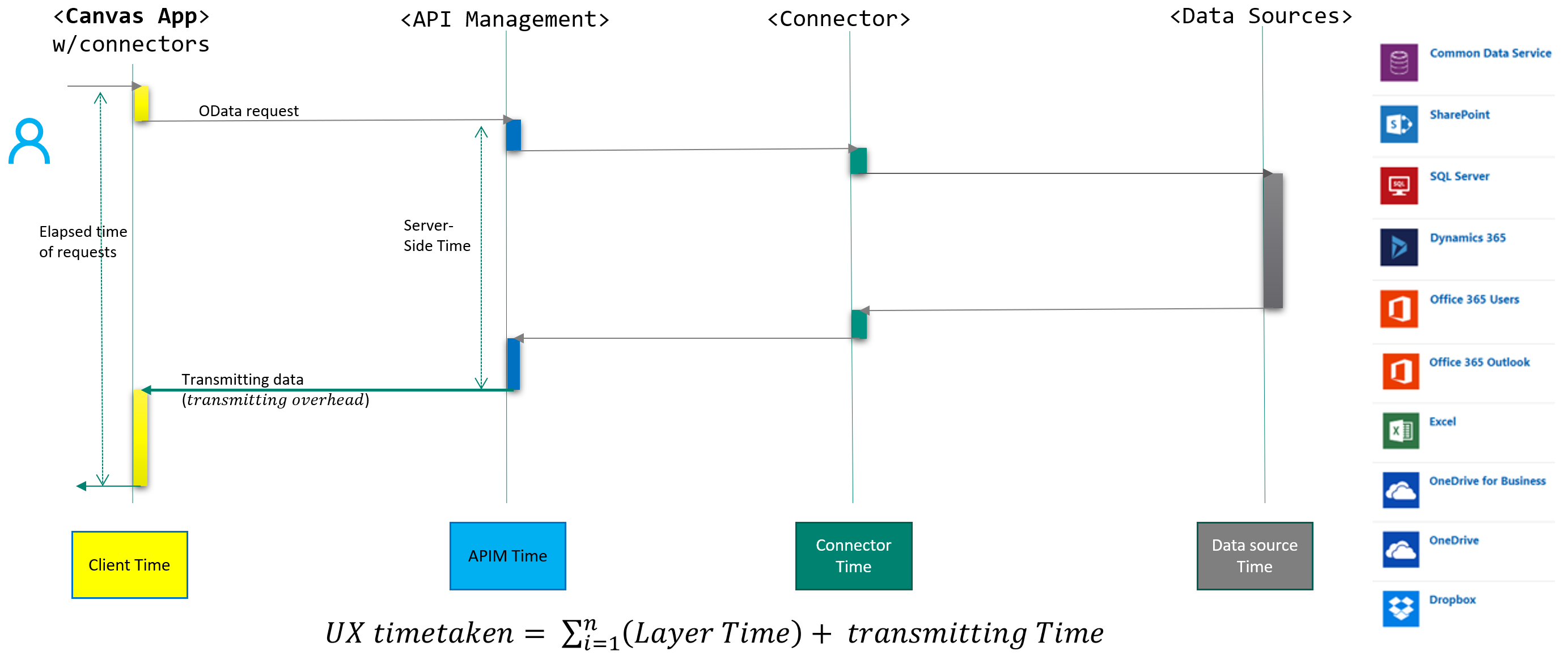
Each layer in Figure1 could perform fast or have some overheads while processing the request.
In many apps, two spots commonly present noticeable overheads:
- First in a backend data source while processing the request.
- Second in the client while sending a request or while manipulating received data on the heap memory and executing associated JavaScript functions to process data to show in screens.
If a canvas app connects to an on-premises data source like SQL server, you need to have another layer, called on-premises Data Gateway. The on-premises data gateway is a mandatory part to access on-premises data sources. It takes charge of converting protocol from OData requests to SQL DML (data manipulation language) statement. Figure2 illustrates where and how the on-premises data gateway would be put in place and process data requests.
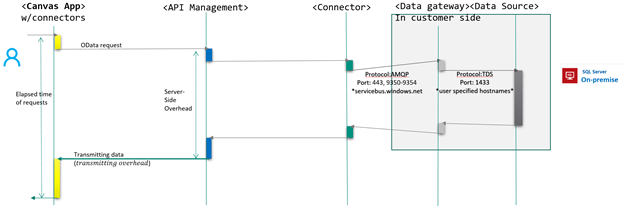
If the app uses a data source on-premises, the location and specification of data gateway would also affect the performance of data calls.
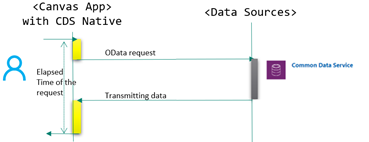
When you use the Microsoft Dataverse connector to access a Microsoft Dataverse environment, data requests would go to the environment instance directly, without passing through API management. Hence, the performance of data calls is much faster. By default, the Microsoft Dataverse connector is created when you create a new canvas app.
With understanding this high-level concept of how data calls travel, let us get into the detail of performance. Concisely, performance overhead could be happening at any of the layers from client, APIM, connector, on-premises data gateway and backend data sources.
In many enterprises, the slow performance of Power Apps has statistically been related to:
- The way of implementing the app
- the bottleneck in data sources
- usage patterns like browser types
- geographical location of on-prem data gateway and environment
- throttling in a gigantic volume of requests onto a backend within a brief period
- The way of implementing an app: this means many things. When the maker makes the client-heavy app by getting large sets of data into data collections at the very initial moment and use such data within multiple screens over client-heavy operations like JOIN, Sort, AddColumn and GroupBy, when the app has long formula in OnStart, when the app triggers many unnecessary data calls in screens and when each data calls returns large data records, then the app would perform slow. Monitor the app’s behavior by using the Power Apps Monitor and check what data calls are taking a long time and how many data calls trigger scenarios in the app. The other suggestion is to balance the workload between client and server. Delegating the workload to the server would be recommended too. From client memory consumption perspective, it is also important to make client app lightweight.
- The bottleneck in data sources: there are many scenarios making backend data source to be bottlenecked. Usually tables in the data source fall into a hotspot when many transactional/non-transactional queries are directed to the same table or record from different users. In other cases, OData calls get slow down if the backend machine hosting the data source is low-end machine, if the backend SQL instance has blockings and deadlocks and if it suffers from resource contention. Plus, if you have on-premises data gateway and it is unhealthy, OData calls could be slow by the bottleneck from the data gateway too. In these cases, it must tune the backend data source.
- Usage patterns: apps you publish will be used by many users on different devices, on different browsers and at different locations having various network conditions. As the Power Apps client executes, it is strongly recommended to use modern browsers like new Microsoft Edge. If some users are on using legacy browsers like Internet Explorer, their experience could be affected. Makers are suggested to publish the app regularly. As the Power Apps platform is continuously optimized and deployed, your app is regenerated within the latest platform optimizations when you republish it.
- Geographical location of the environment and on-premises data gateway: users can access the app globally. However, it would be better to have the data source near most of the end users. When your app access your on-premises data source (for example), the location of on-premises data gateway should be close to the data source to minimize any extra overhead between the gateway and data source.
- Throttling: In most cases, you might not experience throttling limits unless you built your app generates lots of data calls within a small period intentionally. Please check this article and this one . For instance, calls per connection per user would be limited to 600 over 1-minute sliding time window. If your app is built to generate many data calls, whether calls get throttled or not, your users might not experience the best experience, profiling the app using Power Apps Monitor would help you to avoid this problem.
I briefly touched on several points. In the real world, makers can select any number of data sources via connectors for Power Apps. Although there are many options, it is important to choose the right data source and connector from many perspectives: architecture, performance, maintenance, scalability and so on. Let us check the details about what potential performance issues might exist per data source: SQL (on-premises), Azure SQL online, SharePoint, Microsoft Dataverse, Dynamics, and Excel. This information will help you to choose the right data source with your business plan and growth in mind.
Common performance issues
Regardless of data sources you pick, there are common issues making your apps slow in the playing of your app. In this section, let us walk through what they might be.
OnStart
The OnStart event runs when the application is loading and having lots of data called in the OnStart command will slow down the load of the app. If a screen, to be open, has a heavy dependency of controls and values defined on other screens, page load would also be affected by slow screen navigation. N+1 query problem at a gallery got commonly reported.
The following are some issues observed in many cases.
- Many data calls happened within OnStart event which made the app start slow. In enterprise, volume of data calls onto a central data source could drive server bottleneck, resource contention as well.
- N+1 query problem observed from some galleries and it triggered too many requests to servers.
- Queries in database got SCAN data tables instead of SEEK over Index.
- Big latency on OnStart due to heavy scripts. This is a common mistake from many canvas apps. Makers should get only the necessary data from the moment of app start.
- Too many columns were retrieved. In fact, all columns of a data entity would be downloading along with operations. Depending on operation type of operation, the number of records would be changed though. In fact, this adds to unnecessary memory usage in clients and network overheads. It is better to select only the necessary columns.
- Users used the Internet Explorer browser while experiencing Power Apps applications.
- Location of environment vs. end-users is a matter.
- Whitelist apps.powerapps.com in Firewall. Check Proxy settings of your clients if network proxy configured.
Recommendations
- Leverage cache mechanism and optimize data calls. Your application would be used by N users at the end. Hence, the number of data calls per user would be landing at the server’s endpoints, which could be a spot where bottleneck or throttling could be occurred from.
- Use View objects in SQL to avoid N+1 query problem or change the UI (user interface) scenarios not to trigger the problem. There are many great posts explaining what N+1 query problem is and how to avoid.
- Use ‘StartsWith’ instead of ‘IN’ in formula. If you use SQL data source, for instance, StartWith operator would use index SEEK in SQL database. However, the IN operator would require Index or table scan.
- Optimize formula in an OnStart event. You can move some formulas to OnVisible event instead. By doing this way, you can let the app start fast and other steps can be continued along with app launching.
- If you use Microsoft Dataverse, make sure you enabled Explicit Column Selection (ECS) at an advanced setting. Then, Microsoft Dataverse connector will interpret what columns been used in the app and only used columns in the app would be retrieved.
- We recommend that users should use the new Microsoft Edge instead of IE (Internet Explorer). IE has some defects when it comes to execute JS scripts.
- Having an environment close to users is also suggested. Although Power Apps has already put in place the Content Delivery Network (CDN) delivering necessary contents of the app from the nearest CDN, data calls would still get the data from the backend data source which might be in different geographical locations. If your app gets a small set of data per request, the impacts would be minimized. Network footprints such as latency, throughput, bandwidth, and packet loss would be another crucial fact affecting performance.
- Cross check with your network team to make sure *.PowerApps.com got whitelisted.
In the next chapter, let us take a close look at each data source and see what common issues and recommendations are there.
Issue types per data source
SQL Server (on-premise)
Canvas app can reach out the data out of on-premises SQL via on-premises data gateway. Once on-premises data gateway is configured, Power Apps canvas app can manage data with various on-premises data sources such as SQL, Oracle, SharePoint on on-premises networks.
However, accessing on-premises data sources could suffer from slowness due to the following common causes. Although this topic is focusing on SQL on-premises. They are still valid for other data sources on-premises.
Common causes
- Thick client or excessive requests: some canvas app formed formula to do Group By, Filter By, JOIN operations client-side. Although canvas app can do such operations, they would need CPU and memory resources from client devices. Depending on data size, these operations make extra scripting time at the client side on top of increasing JS heap size of the client. Be aware of each lookup data call also travel to data source via data gateway. In this case, the number of data calls is really a matter.
- Unhealthy on-premises data gateway: As organizations can define multiple nodes of on-premises data gateway, all configured nodes should be healthy, on-premises data gateway service should be up and running. If one of nodes was unreachable, data requests onto the unhealthy node would not return the result within a decent time but ‘unreachable’ error message after waiting for a while.
- The location of on-premises data gateway: data gateway requires some network calls to on-premises data sources to interpret OData requests. For instance, data gateway needs to understand the data entity schema so that she could translate OData requests into SQL DML (data manipulation language) statement. However, when the data gateway configured at the other continent with high network latency between the data gateway and SQL instance, it would spawn extra overhead.
- Scalability: In some enterprises, a high volume of data access onto the on-premises data gateway would be expected. In this case, just one node of the on-premises data gateway could be a bottleneck to cover a large volume of requests. A single node of the on-premises data gateway can deal with concurrent connections up to 200. If all these concurrent connections are executing queries actively, other requests would be waiting for an available connection.
Recommendations
- Do use the View object in SQL database for Group By, Filter By, JOIN operations instead of doing such operations at PowerApps client-side. Maker or DBA (Database administrator) can create view(s) with only necessary columns which require for canvas app. Then, use the view entity in canvas app. This approach would also address N+1 query problem.
- Make sure all on-premises data gateway nodes are healthy and configured at decent network latency between the nodes and SQL instance.
- In enterprises, having a scalable data gateway cluster would be recommended in case heavy data requests are expected. DBA (Database administrator) can check how many connections get set up between data gateway nodes and the SQL instance. By checking concurrent connections in an on-premises data gateway or in a SQL server, your organization can decide the point when the data gateway should be scaled out how many nodes are.
- Please do monitor and optimize on-prem data gateway performance by following instructions in the link. As an on-premises data gateway is in organization’s network, Microsoft could not check its performance nor health, but organizations should do.
- Do profile slow queries in a SQL database and tune if any slow queries are found. That is, tune indexes and queries. For instance, if there was a formula getting certain data with descending (DESC) order on a certain column, that sorting column should have an index with descending order. Be aware that an index key would be creating an ascending (ASC) order by default unless specified. Makers can also check the URL address of data requests. For example, following data request snippet asks SQL to return 500 records matching Column to Value and order by ID descending. Hence, makers can imagine what index requires to cover the request condition.In the example below which shows a partial part of an OData call, the ID column should have an index with descending order to perform the query fast.Items? $filter=Column eq ‘Value’ & Orderby = ID desc & top 500 Check the execution plan of slow queries to see if any table or index scan exists. Check if any excessive cost of Key Lookup in the execution plan of slow queries observed or not. When it comes to tune SQL queries, refer to this doc, monitor and tune for performance.
- Make sure your SQL database has no resource contentions such as CPU bottleneck, IO contention, Memory pressure and/or tempDB contention, apart from checking Locks & Waits, Deadlock and timeout of queries.
Note: Azure SQL provides a feature called Automatic tuning. As it is named, it would create missing indexes automatically and fix the execution plan performance problems. Consider turning on this feature on SQL instance.
Azure SQL Online
Organizations can connect to Azure SQL Online via SQL connector. In this case, slow requests were caused by slow queries in the database and/or the huge volume of data had to be transmitted to the client. There were the main concerns. In some case, Service tier of a SQL server was also attributed to slow response.
Common issues
- Data size transfer to client: by default, PowerApps canvas app shows data entities which would be either tables or views from database objects. All columns of entities would be retrieving, which prompts slow response of data requests in case entities have many columns and define many big data types like NVARCHAR(MAX). Simply, total data size of transferring data to client requires transferring time and scripting time to keep that amount data in the JS heap at client side.
- Slow queries: depending on filtering conditions of data requests, the SQL statement which was converted to could be executed with a certain execution plan. If the query executed with heavy IO operation by table scan or index scan, it means data entities might not have proper indexes covering the query. Although the execution plan of queries uses indexes, it could be slow too in case Key Lookup costs high. Refer to item#3,5 and 6 from on-premises SQL section above.
- Service tier: Three Azure SQL Database service tiers—Basic, Standard, and Premium—are available. Each tier has a bit different CPU, IO Throughput and IO(Input/output) latency. Under heavy data requests, these resources could be throttled once the threshold hits. Then, query performance would be compromised.
Recommendations
- Monitor and turn slow queries. check this article: Monitor and Tune for Performance.
Query Store would also provide the necessary information to find slow queries. You can use Extended Events to trace SQL. If you need more details, please refer to Quick Start: Extended events in SQL Server and SSMS XEvent Profiler. - Do use View object in Azure SQL online for Group By, Filter By, JOIN operations instead of doing such operations at PowerApps client-side. In addition, View can define only necessary columns. View can select columns and remove some big data type like NVARCHAR(MAX), VARCHAR(MAX) and VARBINARY(MAX) unless necessary. Maker or DBA (Database administrator) can create view(s) with only necessary columns which require for canvas app. Then, use the view entity in canvas app. This approach would also address N+1 query problem.
- Check the service tier of Azure SQL online if it is on DTU-Based purchase model. Lower tier would have some limitations and constraints. From a performance perspective, CPU, IO throughput and latency would be matter. Hence, check the performance of the SQL database and check if resource usage exceeds the threshold or not. on-premises SQL normally sets the threshold of CPU usage on around 75%, for example.
SharePoint online
SharePoint connector pipelines to SharePoint list(s). From SharePoint list itself, maker can see Power App menu which wizard would create a canvas app quickly.
Common issues
- Data size transmitting back to client is matter, especially when the SharePoint data source is remote. If formula in events at canvas app has nondelegable functions inside, Power Apps platform would retrieve records up to Data Row Limits, default 500 but maker can change it up to 2000. If Data Row Limits were set to 2000 and the SharePoint list has many columns, data size transmitting to client could be huge and it could lead to slowness.
- Too many dynamic lookup columns: SharePoint supports various data types including dynamic lookup, Person or Group and Calculated. If a SharePoint list defines too many dynamics columns, it would take time to manipulate these dynamic columns within SharePoint itself before serving asked data requests. This would depend on the volume of data rows on the SharePoint list.
- Picture column and Attachment: size of image and attached file will attribute to slow response if they are all retrieving to client unless specific columns specified.
Recommendations
- As SharePoint provides many delegable functions,it is worthy checking your formula to see if it would be delegable or not. Otherwise, PowerApps would retrieve the number of records to client, which defined within Data Row Limits (Default 500), and then apply formula on a retrieved data set at client side. Not only reducing Data Row Limits to a low value or at least staying at the default but also forming the formula to be delegable are important to make the app performant.
For instance, let say you have an ID column defined Number data type in the list. Both formulas below will return the results as expected. However, the former is nondelegable and the latter delegable.Formula Delegable? Filter (‘SharePoint list data source’, ID = 123 ) Yes Filter(‘SharePoint list data source’, ID =”123”) No As we assume that the ID column in SharePoint defined data type as Number, right-hand side value should be numeric variable instead of string variable. Otherwise, this type of mismatch would trigger the formula to be nondelegable.
- Review your SharePoint list and make sure only the necessary columns have been defined. As number of columns in the list would affect performance of data requests because either matched records or records up to data low limits would be retrieving and transmitting back to client with all columns defined in the list whether the app uses some or not.
Enabling Explicit Column Selection (ECS) is highly recommended so that data requests would ask only used columns on the app. - Do not overuse dynamic Lookup columns and Person or Group type in SharePoint. Otherwise, extra overheads would be seen on the SharePoint side to manipulate data before applying any filter or search on. You can use a static column to keep email aliases or names of people instead.
- If you have a gigantic list having hundreds of thousands of records, consider partitioning the list to split into several ones per category or datetime. For instance, your data could be stored on different lists on a yearly or monthly base. Then, you can implement the app to let a user select a time window to retrieve data within that range.
Within a controlled environment, the performance benchmark has proved that the performance of OData requests against SharePoint list were highly related to the number of columns in the list and the number of rows retrieving limited by Data Low Limits. The lower column and the lower data row limits setting perform the better. In the real world, however, it is quite hard to simply reduce data rows limits and columns because the app needs a certain amount of data to cover business scenarios. Hence, please monitor OData requests at the client side and tune these two knobs.
Microsoft Dataverse
As you can check this article ‘What is Microsoft Dataverse’, Microsoft Dataverse provides a handy way to define custom entities with built-in security model where you can securely store your business data in.
Canvas app can access a Microsoft Dataverse data source which directly connect to Microsoft Dataverse instance without through API management layer (Refer to Figure 3.) Microsoft Dataverse has enabled by default so that when you create a new canvas app connecting to your Microsoft Dataverse instance, data requests from your app will execute through Microsoft Dataverse onto your Microsoft Dataverse instance.
Microsoft Dataverse connector performs much faster than the old connector. If you have existing canvas apps using an old connector, we highly recommend migrating the app to the Microsoft Dataverse connector.
Common issues
- Too much data transmitted to a client also made requests be slow. For instance, if your app has set Data Row Limits to 2000, instead of default 500, it adds up extra overhead on transferring data and manipulating received data to JS Heap at client side.
- The app did run client-heavy scripting such as Filter By/Join at client side instead of doing such operation at server side.
- Canvas app had used old commondataservice connectors. Firstly, the old commondatasource connectors got some overheads. Hence, OData requests via the connector were slower than that via Microsoft Dataverse connector.
Recommendations
- Enable Explicit Column Selection (ECS) which would select only used columns in your app instead of retrieving all columns of the entity you used in your app.
- Leverage Microsoft Dataverse View. Microsoft Dataverse View makes a logical view out of entities with joining/ filtering entities. For instance, if you should join entities and filter their data, you can define a view via Microsoft Dataverse View designer by joining them and define only necessary columns. Then, use this view in your app which put load to server by avoid the app from joining overhead at client side. This would reduce not only extra operations but also data transmission.
- Migrate your app to use Microsoft Dataverse connector in case your app is still using the old connectors such as commondataservice or dynamicscrmonline.
- Reduce Data Row Limits to 500 at least. Please think about your app really requires retrieving more than 500 records or not. As your app might be running at mobile/tablet devices, having light-weight data at clients would perform better. In many cases, delegable functions cover your business logic.
Note: Microsoft Dataverse View only support sorting and filtering as of today. Group By would be in the future.
| Note:
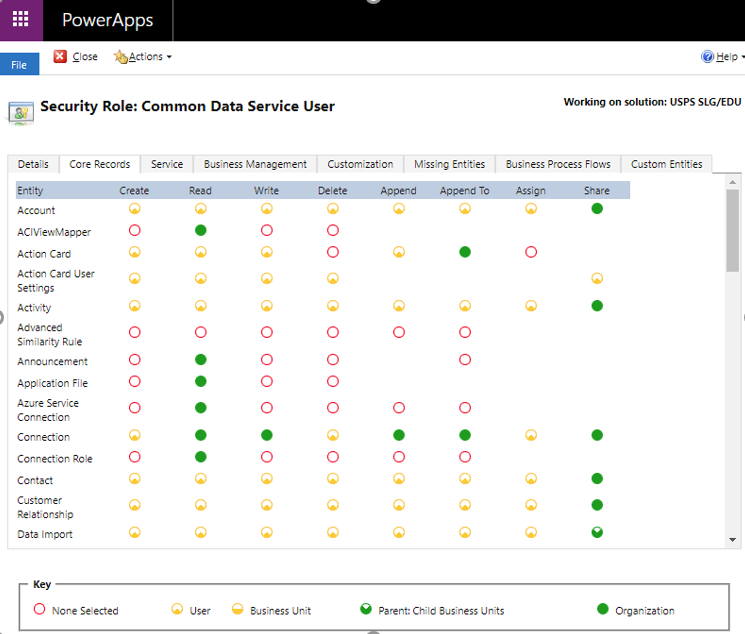
By default, out-of-box entities set minimum privileges as Figure4. You can configure many privileges. If you defined custom entities, however, you must set privileges for your custom entities from the Custom Entities tab. Otherwise, app users might not be able to see data from the app you published when users are under Microsoft Dataverse User role. Microsoft Dataverse comes with the built-in security model which administrators can configure or edit security role privileges and access level for out-of-box entities and custom entities. From PowerApps portal, select a gear icon positioned at the right top, then select Advanced settings. The page would be redirected to Dynamics 365 settings page. Within the page, click the Settings menu at the top. Find and click Security under System. If you click Security Roles among many menus, it will list up defined Security roles. Find Common Data Service User from the list. When you click the role, you would be landing at Security Role privilege editor [Figure 4], where you can configure security privileges per security role and entities.
Figure 4 Security Role privilege editor |
Excel
People in the business world use Excel sheets to manage their business data. The Excel connector in PowerApps provides connectivity from a canvas app to the data in Excel data table. By following steps here, you can define a data table(s) within an Excel file and retrieve such data onto a canvas app.
Although a maker knows a little about other data sources, Excel would be enough to store your business data based on your format.
However, please be aware that the Excel connector has limitations compared to other data sources. As it provides little delegable functions, PowerApps loads data from data table up to 2000 records, nothing more than that. If you really want to load more than 2000 records, you should do partition your data onto a different data table and then load both data tables.
Apart from this limitation, there are some cases when slow performance happens. Let us see what common issues are there.
Common issues
-
- Too many data tables are defined, and each data table has an immense size of data over many columns. As Excel is not a relational database nor data source providing some delegable functions, PowerApps should load data from defined data tables and then you can use functions that PowerApps provides such as Filter, Sort, JOIN, Group By and Search. If you have defined too many data tables and each contains many columns and stores many records, obviously launching App would be affected by because each data table should be manipulated within JS heap in Browser and the app would also consume certain amount of memory for the data(refer to a section how to check memory usage of your app using developer tool.)
- Heavy transactions from many users get slow down the app too. We know Excel is a product dealing with data in its spread sheets. It is not a system nor a relational database. Which means that any data changes from your app would be managed by Excel in the same way that Excel does for data in spread sheets.
If the app mainly reads data from the excel file but rarely triggers transactions like Create/Update/Delete, the app will perform well although hundreds of thousands of users use the app. However, if heavy transactions happen from a small group of users, it would be a big offender of slow performance.
There is no simple number saying what is the threshold of transactions because it is also related to data itself and the size of the data table and others like network footprint and user’s devices.
The location and size of the excel file. If all data tables are defined within a single file and the file size is big, then extra overheads for downloading the file and reading data to load are expected.
Meanwhile, you can select various storage to store the excel file(s): Azure Blob storage, One Drive for business and so on. Please be aware that the Excel file should be downloaded to the client before loading data out of the data tables defined within the file. You can naturally imagine the downloading time of the file would be adding up on overall performance of your app start.
Recommendations
- It is better to keep the file near your end-users so that the file can be downloaded quickly instead of putting it in a remote location.
- Leverage other data sources like Microsoft Dataverse, SQL, or SharePoint instead, especially for the Enterprise scale app.
- If you have Read-only data, you can import such data into the app itself instead of loading it whenever the Power Apps app start.
- Split to multiple Excel files with minimum data tables(sheets) and load a file when it really requires so that transmitting a file and loading data from data table would be scattered.
- Define only the necessary columns on the data table at Excel. Loading unnecessary columns hurts the performance, obviously.
The Excel connector and Excel file will be a good fit for small transactions and data. However, it might not be good enough on the enterprise scale.
Memory pressure
Another important topic would be to check memory pressure. but here, let us briefly check it out.
Memory consumption of your canvas app is matter as it would be running at mobile player, window player and browsers via various devices like tablet, mobile, laptop and desktop. If your canvas apps get crashed or hung at certain device, chances are it caused by the out of memory exception at Heap.
Common issues
- JS Heap hit the ceiling due to heavy scripts running at client side for adding columns, joining, Filtering, Sorting and Group By.
Recommendations
- In most cases, out-of-memory exception at the heap in client triggered crashing/hung the app.
- Do profile Performance from a browser and check what scenarios hits the ceiling of JS Heap.
In Microsoft Dataverse/SQL/Dynamics CE, makers can use a View object to avoid joining/filtering/grouping/sorting from client side but on server side. This approach would reduce client overhead of Java scripting for such actions.
From developer tools in browser, you can profile memory. It would visualize heap size, document, nodes, and listeners. If client-heavy operations like JOIN, Group By happened at client with a data set having records 2000, objects in heap would be increasing and it could hit the ceiling.

Check JS heap size in Browser
Conclusion
Makers can build Power Apps applications with diverse options of data sources. In this article, we walked through many options you could choose with considerations per data source and connector. While selecting the data sources, each way has pros and cons.
Depending on the app covering different business needs and scenarios, makers would be suggested to pick the right data source and a connector.
In the enterprise level of applications, picking up the Microsoft Dataverse data source and Microsoft Dataverse connector would be the recommended choice as it comes with lots of benefits and this combination performs well above.
If your application would have small amount of transactions, you can go with whatever available data sources in your environment.
Plus, the maker should think about the number of users who will use the app when it has published, the volume of Create/Update/Delete transactions, type of data interactions, geographical access, and user’s devices as well.


