
The New and Improved Cardinality Estimator in SQL Server 2014
One area where a lot of development work went into SQL Server 2014 is the area of query optimization where a crucial component got re-written in order to improve query access and predictability.
To get a better idea about the significance of the change and the way how one should deal with it, let’s first check what the component of cardinality estimation is responsible for.
When a query is executed for the first time, it is getting ‘compiled’. In opposite to a compilation of executables where we talk about binary compilation, the compilation of a SQL Statement is limited to figuring out the most efficient access to the data requested. This means, for example, the query engine needs to decide which index to pick in order to have the most efficient access to the data rows or, in case of table joins, the order of the join and the join methods need to be decided. At the end of the compilation there is a descriptive query plan which will be cached. During the execution phase the query plan is read from cache and interpreted. Since compilation of a query plan represents significant resource consumption, one usually is keen to cache these query plans.
At a very high level, the Query Optimizer uses the following input (in order) during the compilation phase:
- The SQL Query and/or Stored Procedure
- If the query or stored procedure is parameterized, then the value of the parameters
- Knowledge about the index structures of table(s) to be accessed
- Statistics of index(es) and columns of the table(s) to be accessed
- Hints assigned to the query
- Global max degree of parallelism setting
There might be a few more inputs, but these are the main ones. The first step which often is decisive for the performance of the query is to estimate how many rows the query might deliver back based on the inputs above. It is not only estimated how many rows the query would deliver. In order to decide for the correct join method in e.g. a table join, one also needs to estimate how many rows would be delivered by each execution step and query branch accessing each of the tables involved in the join. This is done in the so called Cardinality Estimation (referred to as CE from now), which this article is about. The estimated number of rows will be the base for the next step of query optimization assuming that the estimated number of rows is correct. This means the choice of picking a certain index or the choice of a join order or join type is majorly impacted by the first step of estimating the cardinality of a query.
If that estimation is plain wrong, one can’t expect that the subsequent steps of query optimization will be able to derive an efficient plan, unless the query itself leans to a particular index like querying exactly one row by specifying the Primary Key or hardly any indexes are available to be used.
In order to estimate the number of rows returned, CE requires the statistics over indexes and columns of tables as a reliable source of information to figure out how often a certain value of a parameter value, submitted with the query, is present. Hence if there are no statistics or plain wrong or stale statistics, the best CE logic will hardly be able to predict the right values of returning rows for a query.
The role CE is playing in the process to generate a good query plan is important. One hardly can expect a great Query Execution Plan as a result when the CE would estimates would be completely off workload which required SQL Server code fixes circled around issues in Cardinality Estimation.
What changed in SQL Server 2014?
At a very high level, the CE process in SQL Server 2012 was the same through all prior releases back to SQL Server 7.0 (the release before SQL 2000). In recent years we tried to put a lot of fixes or QFEs in regards to query optimization (including cardinality estimation) under trace flag in order not to cause a general regression over all those releases due to changed behavior by the fix.
With the release of SQL Server 2014, there were several good reasons to overhaul what was basically the CE as introduced 15 years ago. Our goals in SQL Server Development certainly were to avoid issues we so far experienced over the past 15 years and which were not fixable without a major redesign. However to state it pretty clearly as well, it was NOT a goal to avoid any regressions compared to the existing CE. The new SQL Server 2014 CE is NOT integrated following the principals of QFEs. This means our expectation is that the new SQL Server 2014 CE will create better plans for many queries, especially complex queries, but will also result in worse plans for some queries than the old CE resulted in. To define what we mean by better or worse plans, better plans have lower query latency and/or less pages read and worse plans have higher query latency and/or more pages read.
Knowing that the CE has changed and purposefully was not overcautiously re-architected to avoid regressions, you need to prepare a little more carefully for a SQL Server 2014 upgrade if you will utilize the new Cardinality Estimator. Based on our experience so far, you need to know first:
- As of January 2014, feedback about the new CE is very good, showing only a small number of cases where query performance showed regressions compared to the old CE
- Whether the overall picture with the new CE is positive or negative is dependent on the nature of the queries the workload is generating and the distribution of the data
- Even with ISV applications it is not always easy to tell whether certain ISV application benefit from the new CE or not. Reason is that a lot of ISV applications are highly customizable and therefore can produce very different workload when used by different customers.
Activation/De-Activation of the new CE
As delivered, SQL Server 2014 decides if the new Cardinality Estimator will be utilized for a specific database based simply on the compatibility level of that database within the SQL Server 2014 instance. In case the compatibility level of a specific database is set to ‘SQL Server 2014 (120)’ as shown below, the new CE is going to be used.
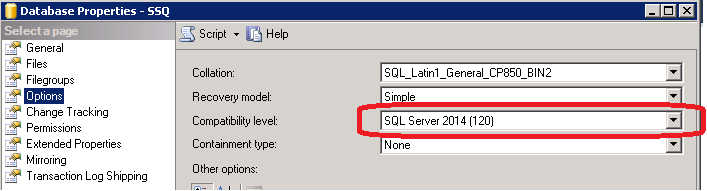
If the Compatibility level of a specific database is set to a lower value, like ‘SQL Server 2012 (110)’, the old CE is going to be used for the specific database.
As with other releases of SQL Server, upgrading your SQL Server instances in place or attaching existing databases from earlier releases of SQL Server will not result in a change of the compatibility level of a database. Hence by purely upgrading a SQL Server instance or attaching a database from SQL Server 2012 or earlier releases will not activate the new CE. One would need to change the compatibility level of such a database manually to ‘SQL Server 2014 (120)’ to activate the new CE. However toggling between the compatibility levels of 110 and 120 in case of SQL Server 2014 does have some other impact beyond the change of CE algorithms. E.g. the parallel insert functionality of SELECT INTO would be disabled by staying on the old compatibility levels as well.
Another alternative to enable/disable the different CE algorithms is the usage of a trace flag. Even with the compatibility level of a database set to ‘SQL Server 2014 (120)’, the trace flag would enforce the usage of the old CE. In opposite to the compatibility level which is applied to a specific database, the trace flag, if used as startup trace flag, would affect the usage of the CE SQL Server instance wide. This behavior might not be desired when many different databases are run in one instance. However, for situations where one runs one user database per SQL instance or consolidates several databases of a type of application under one SQL server instance, it indeed might make sense to use the trace flag approach. In order to force the old CE algorithms, trace flag 9481 can be used as startup trace flag.
Why can query plans change with the new CE?
Calculate combined density of filters differently
In this section we refer quite a bit to index or column statistics and the specific data that is captured in those. For folks less familiar with how index or column statistics are structured and what is contained in those, it would be advisable to read the Microsoft TechNet article, “Statistics Used by the Query Optimizer in Microsoft SQL Server 2008” before continuing.
One of the most significant changes in the new CE is the way how the CE calculates the selectivity of a combination of filters submitted with a query. In the old CE, the assumption was that the selectivity of the filters was independent, assuming any combination of values stored in the different columns the filters are applied to, would have the same probability of occurring. However very often reality is that combinations of values of different columns are not as independent. We can find masses of cases where values in different column within one table are not independent of each other. Think about a car brand like Toyota, Volkswagen, Ford, Mercedes, etc being represented in one column and the type like Corolla, Jetta, Focus or E-Class being represented in another column of the table. It immediately becomes clear that certain combinations can’t happen since Volkswagen is not producing a car named ‘Corolla’.
Let’s see at what the differences really are in the calculation of selectivity.
Let’s assume the following indexes against a table like this:
|
index_name |
index_description |
index_keys |
|
FILCA~0 |
clustered, unique, primary key located on PRIMARY |
RCLNT, GL_SIRID |
|
FILCA~1 |
nonclustered located on PRIMARY |
RCOMP, RACCT, RYEAR, RVERS, RLDNR |
|
FILCA~2 |
nonclustered, unique located on PRIMARY |
DOCNR, DOCCT, RLDNR, RYEAR, RCOMP, ROBUKRS, DOCLN, RCLNT |
|
FILCA~3 |
nonclustered located on PRIMARY |
REFDOCNR, REFRYEAR, REFDOCCT, RCOMP, ROBUKRS, RLDNR, RCLNT, REFDOCLN |
The query issued against the table looks like:
SELECT
*
FROM
“FILCA”
WHERE
“RCLNT” = ‘001’ AND “RLDNR” = ’10’ AND “RRCTY” = ‘0’ AND “RVERS” = ‘001’ AND “RCOMP” = ‘ABXYZ’
AND “RACCT” = ‘1212121212’ AND “RMVCT” = ” AND “RYEAR” = ‘1997’ AND “RLEVL” = ‘0’ AND “DOCTY” = ”
AND “POPER” BETWEEN ‘001’ AND ‘006’ AND “DOCCT” = ‘A’
SQL Server’s query optimizer using the old CE would choose the first non-clustered index (FILCA~1) to access the table. This means there would be five filters which could be applied since all the five columns of the ~1 index are specified in the query.
In the single column statistics the densities of each single column look like:
|
Column Name |
Density |
|
RAACT |
0.125 |
|
RVERS |
0.3333 |
|
RCOMP |
0.5 |
|
RLDNR |
0.5 |
|
RYEAR |
1 |
Treating the selectivity/density of each filter/column independently, the question of the overall density would be:
0.125 * 0.3333 * 0.5 * 0.5 * 1 = 0.0104
A value which is confirmed when we look at the combined densities displayed in the statistics of index FILCA~1:
|
All density |
Average Length |
Columns |
|
0.5 |
11.14286 |
RCOMP |
|
0.0625 |
31.14286 |
RCOMP, RACCT |
|
0.0625 |
39.14286 |
RCOMP, RACCT, RYEAR |
|
0.02083333 |
45.14286 |
RCOMP, RACCT, RYEAR, RVERS |
|
0.01041667 |
49.14286 |
RCOMP, RACCT, RYEAR, RVERS, RLDNR |
|
0.01041667 |
55.14286 |
RCOMP, RACCT, RYEAR, RVERS, RLDNR, RCLNT |
|
3.60E-05 |
89.14285 |
RCOMP, RACCT, RYEAR, RVERS, RLDNR, RCLNT, GL_SIRID |
Assuming an even distribution over the values of the columns, we can assume density values as those displayed above. Be aware that CE using parameter sniffing would use the particular density value for a submitted value if the data distribution is uneven. But for simplicity reasons we assume an even distribution. Having a very small number of rows in our table of only 27776 rows, the estimated number of rows basically was calculated out of:
# of rows / (1/combined density) which would be: 27776/(1/0.01041667) = 289.33
This means CE would expect to get 289 rows back using this index FILCA~1
Looking at the query it becomes clear that using the non-clustered index, not all columns could be filtered that were specified in the where clause. After reading the 289 entries of the non-clustered index, the real data rows would be read and the additional column filters applied then.
Now to the change with the new CE, where we assume that the combination of the different column values are not as independent. The assumption is that certain combinations of values are not coming up at all, whereas others are showing up more frequently. Besides the example with car brands and their car types, other examples of such dependencies between columns are found in all business processes and therefore in the underlying data in database tables. For example, materials or goods that are produced or stored in certain locations and warehouses only would have such a data dependencies. Or, employees associated with a certain profit center or organization would also have such a data dependencies. This means the reality is that the values in different columns are sometimes related to each other. In order to reflect that in the calculation of the possible selectivity/density, we apply a new formula with a so called ‘exponential back-off’. The logic would work like:
- Sort the filters according to their density where the smallest density value is first. Since the density is expressed in a range between 0.xxxx and 1 the smaller values means lower density, better selectivity or more different values.
- We also would use the first four most selective filters only to calculate the combined density. Looking at the formula we use, it becomes clear why 5thand more density values will not make big impact anymore. In our cases the order would look like:
- 0.125, 0.3333, 0.5, 0.5 in single column density values of the filters which can be applied to the non-clustered index FILCA~1.
- The calculation formula now would d1 * d2^(1/2) * d3^(1/4) * d4^(1/8)
If we would calculate for 5th or even 6th filter value with d5^(1/16) or d6^(1/32), the values would be close to 1 and hence have little impact on the result anyway. Therefore the restriction to the 4 most selective values does not change the result significantly.
In our case this would be: 0.125 * 0.3333^(1/2) * 0.5^(1/4) * 0.5^(1/8) = 0.0556468
Applying the same formula of # of rows / (1/combined density), we would look at:
27776/(1/0.0556468 ) = 1539 rows estimated to get out of the non-clustered index.
Which of the estimates is more accurate certainly depends on the actual data distribution at the end.
Note: Be aware that the new calculation formula to calculate combined density of filters is not reflected in the index and column statistics. The section which shows ‘all density’ in the statistics is calculated and stored the same way it always has been. No changes there due to the new CE.
A second change with the new CE
The old CE had some problems in the case of ascending or descending key values. These are scenarios where data is getting added to the table and the keys are going into one direction, like a date or incrementing order number or something like that. As the CE, in the attempt to compile a query, is trying to estimate the number of rows to be returned, it looks into the column statistics to find indications about the value submitted for this column filter. If the histogram data does show the value directly or gives indications that the value could exist within the value range the statistics cover, we usually are fine and can come back with a reasonable estimate. The problem more or less starts where the value we are looking for is out of the upper or lower bounds of the statistics. The old CE is usually assuming then that there is no value existing. As a result we will calculate with one potential row that could return. Not a real problem if we perform a select that qualifies all the columns that define a primary key or only gets a small number rows back. This could, however, develop into a larger issue if that estimation of just one row decides that this table access is the inner table of a nested loop, but there happen to be 50K rows with that very value. The fact that a new sequential value falls outside the statistics range could happen because the statistics simply didn’t get updated recently. In order to mitigate the risk encountering such a situation, we introduced trace flag 2371 a while back that should force more frequent update of the statistics. We described this scenario in this blog.
The new CE should handle these cases differently now.
Let’s show it with an example. Let’s show it with the BUKRS column which contains the company code of a financial table of wide spread ISV application. Let’s assume we have one of those tables where we have 100 different company codes between 1000 and 1200 in 1 million rows. Now let’s go through a few different scenarios:
- An update statistics with fullscan was performed. If you issue a statement right after the update of the statistics that specifies a BUKRS value which would be out of the range of the column statistics on BUKRS, the behavior is the same as with the old CE. This means it would estimate 1 row would be returned. The reason is that because the statistics were based a full scan plus the row modification counter indicating zero changes affecting the column(s), we would know that there was no change to the table since updating the statistics. Therefore we know that there are no rows with a value that is out of the range of the column statistics of BUKRS. So in this scenario there is no change between the behaviors shown with the new CE and the old CE in general (which was independent of the state and creation of the statistics). Please keep in mind that the method in which the statistics was updated that holds the histogram of the column is important. E.g. if the existing statistics were updated in fullscan mode, but due to a new query a column statistics on a specific column got ‘autocreated’ (with default sampling), then the new CE will behave as described in the next point.
- Or, assume that the update statistics was done in the default manner which uses a sample of the data only. In this case, the new CE would differ in its behavior from the old CE by returning an estimate that is >1. In our particular scenario it returned an estimate of 1000 rows.
Now let’s assume we add another company code and give it a value beyond 1200 with around 10K rows
- In the case of having all statistics updated in a fullscan manner before the rows got added, the new CE also will now report an estimate of around 1000 rows when one specifies a value which is out of range of the current statistics. As the number of rows added increases, the estimate for the rows outside do increase, but not significantly. The # of rows estimated which are found outside the boundaries of the statistics will be majorly impacted by the # of values and their occurrence in the column according to the statistics. This means the 1000 rows in our example are just a result out of the selectivity on that column (100 different values), the # of rows in the table and an even distribution. The value of 1000 as estimated in our example should only be regarded with the background of our example and query and not as a generic kind of output for all purposes.
- For the case of having update statistics performed in the default sampling one ends up with a similar behavior as with having the update statistics done in fullscan. The initial estimate is a touch different, but completely insignificant from a pure number difference. As one adds more and more rows, the estimate of the rows expected from outside the range does increase slightly. This increase would be the same as seen in the example above. It is also not significant enough to have major impact in the plan choice. Not, at least, in this generic example.
What if we would create a new company code within the range of an index? The question is whether the new CE would behave differently if we would create a new company code within the range of existing company codes. The behavior here is not too much different between the old and the new CE. Assuming that the statistics did catch all the company codes, and assuming that there are less than 200 company codes, the statistics would indicate that no values exist between the different values documented in the histogram in the statistics. Hence the new as well as the old CE would return an estimate of 1 row only. This same estimation would happen even if there were quite a few changes to the table after update statistics was performed. This means the specific problem class of:
- Having a small number of different values which are all captured in the stats and are all documented in the histogram part of the statistics in their own bucket
- Another object gets added within the range of the existing data
Is not getting solved by the new CE either, because the logic applied for out of range values is not applied for values which are in-range of the statistics.
Whereas if there are that many values within a column that the 200 buckets are not able to keep all values in the histogram, the old and the new CE estimate a number of rows for a non-existing value which is within the range of the column statistics. The value estimated will be calculated mainly based on values stored as RANGE_ROWS and DISTINCT_RANGE_ROWS in the column statistics.
The small amount of examples and scenarios described here should give an idea of the most significant changes the new CE introduces. Of course, these are hypothetical explanations and dependent on the structure and dependencies between values of different columns, it might or might not be close to the truth. But especially with accesses through non-clustered indexes it can mean that with the new CE one moves a bit earlier to use the clustered index instead of the non-clustered index. But since we today have data mostly present in memory, the difference might not play out to be too significant.
On the other side, due to the way the new CE treats ascending key scenarios, table joins might benefit with better plans. Therefore more complex table joins could perform better, or have less query latency, using the new CE. This is usually caused due to a different plan being generated that provides faster execution.
How can we detect whether a plan got generated with the new or old CE?
The best way checking is to look at the XML showplan text (not the graphic representation of it). In the top section you can see a section like this:
<?xml version=”1.0″ encoding=”utf-16″?>
<ShowPlanXML xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” xmlns:xsd=”http://www.w3.org/2001/XMLSchema” Version=”1.2″ Build=”12.0.1525.0″ xmlns=”http://schemas.microsoft.com/sqlserver/2004/07/showplan”>
<BatchSequence>
<Batch>
<Statements>
<StmtSimple StatementCompId=”1″ StatementEstRows=”289.333″ StatementId=”1″ StatementOptmLevel=”FULL” StatementOptmEarlyAbortReason=”GoodEnoughPlanFound” CardinalityEstimationModelVersion=“70“ StatementSubTreeCost=”0.854615″
Or like
<?xml version=”1.0″ encoding=”utf-16″?>
<ShowPlanXML xmlns:xsi=”http://www.w3.org/2001/XMLSchema-instance” xmlns:xsd=”http://www.w3.org/2001/XMLSchema” Version=”1.2″ Build=”12.0.1525.0″ xmlns=”http://schemas.microsoft.com/sqlserver/2004/07/showplan”>
<BatchSequence>
<Batch>
<Statements>
<StmtSimple StatementCompId=”1″ StatementEstRows=”1350.86″ StatementId=”1″ StatementOptmLevel=”FULL” CardinalityEstimationModelVersion=“120“
When CardinalityEstimationModelVersion is set to 70 the old CE is in use. When it is set to 120 then the new CE is in use.
Summary
- SQL Server introduces a new CE which is active for all databases with compatibility level of SQL Server 2014
- The new CE is calculating combined filter density/selectivity differently
- The new CE is treating ascending/descending key scenarios differently
- There are significant changes in how column densities of different tables in join situations are evaluated and density between those calculated. These changes were not described in details in this article.
- The different changes in calculation can end up in different plans for a query compared with the old cardinality estimation
- Dependent on the workload or the application used, there might be the need for more intensive testing of the new CE algorithms in order to analyze the impact on business processes
- Microsoft will support either the new or old CE
- Customers are highly encouraged to test the new CE thoroughly and if the testing shows beneficial or neutral impact on performance of the business processes then you should use it productively