
Guest Blog: Delivering Transformational Outcomes with Hortonworks Data Platform 2.3
Guest post by Rohit Bakhshi, Product Manager at Hortonworks Inc.
Over the past two quarters, Hortonworks has been able to attract over 200 new customers. We are feeding the hunger our customers have shown for Open Enterprise Hadoop over the past two years. We are seeing truly transformational business outcomes delivered through the use of Hadoop across all industries. The most prominent use cases are focused on:
- Data Center Optimization – keeping 100% of the data at up to 1/100th of the cost while enriching traditional data warehouse analytics
- 360° View of Customers, Products, and Supply Chains
- Predictive Analytics – delivering behavioral insight, preventative maintenance, and resource optimization
- Data Discovery – exploring datasets, uncovering new findings, and operationalizing insights
What we have consistently heard from our customers and partners, as they adopt Hadoop, is that they would like Hortonworks to focus our engineering activities on three key themes: Ease of Use, Enterprise Readiness, and Simplification. During the first half of 2015, we have made significant progress on each of these themes and we are ready to share what we’ve done thus far. Keep in mind there is much more work to be done here and we plan on continuing our efforts throughout the remainder of 2015.
This week Hortonworks proudly announced Hortonworks Data Platform (HDP) 2.3 – which delivers a new breakthrough user experience along with increased enterprise readiness across security, governance, and operations. HDP 2.3 will simultaneously be available on Windows Server and Linux, and will be supported for deployment on Azure Infrastructure as a Service (IaaS) virtual machines.
In addition, we are offering an enhancement to our support subscription called Hortonworks Smartsense™.
Breakthrough User Experience
HDP 2.3 eliminates much of the complexity administering Hadoop and improves developer productivity. We employ a truly Open Source and Open Community approach with Apache Ambari to put a new face on Hadoop for the administrator, developer, and data architect.
We actually started this effort with the introduction of Ambari 1.7.0 which delivered an underlying framework to support the development of new web-based Views. Now, we would like to share with you some of the progress we’ve made leveraging that framework to deliver a breakthrough user experience for both cluster administrators and developers.
Enabling the Data Worker
With HDP 2.3 we focus on the SQL developer and provide an integrated experience that allows for SQL query building, displaying a visual “explain plan”, and allowing for an extended debugging experience when using the Tez execution engine. A screenshot of what we’ve developed shown below:
With the Hive View in Ambari, developers now have a web based tool to develop, debug and interact with remote clusters in Azure. Ambari’s web based tooling allows admins to securely and easily manage their clusters on Azure without having to log in and edit configuration files on the remote cluster.
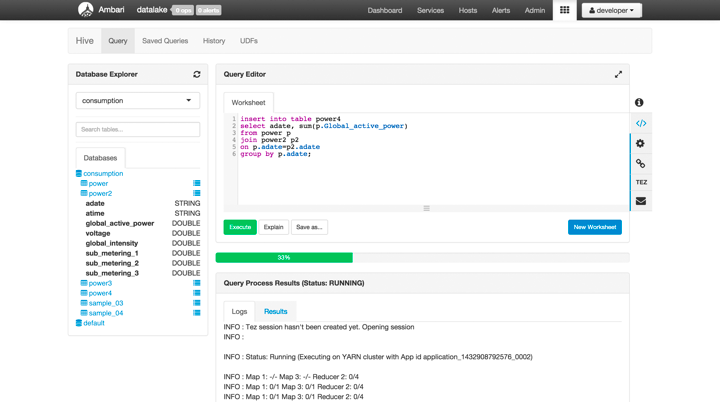
In addition to the SQL builder, we are providing a Pig Latin Editor which brings a modern browser-based IDE experience to Pig, as well as a File Browser for loading file datasets into HDFS.
HDP 2.3 brings an entirely new user experience for Apache Falcon, our Data Lifecycle Management component. The new Falcon UI allows you to search and browse processes that have executed, visualize lineage and setup mirroring jobs to replicate files between clusters and cloud storage – allowing enterprises to seamlessly backup data to Azure Blob Storage.
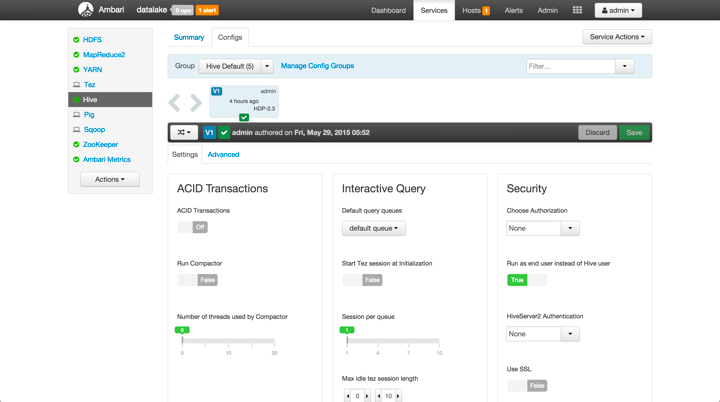
Smart Configuration
For the Hadoop Operator, we provide Smart Configuration for HDFS, YARN, HBase, and Hive. This entirely new user experience within Ambari is guided and more digestible than ever before.
Shown below is the new configuration panel for Hive:
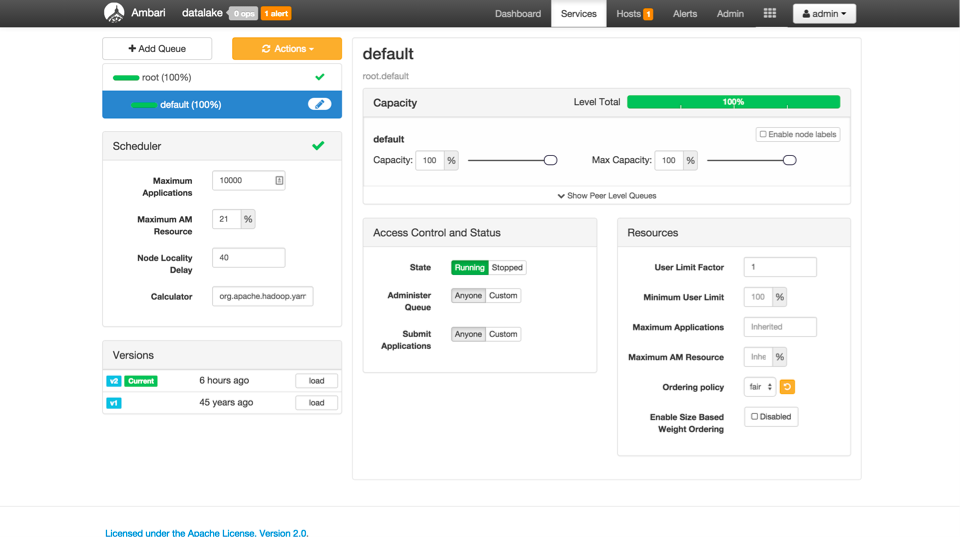
YARN Capacity Scheduler
The YARN Capacity Scheduler provides workload management across application types and tenants in a shared HDP cluster. HDP 2.3 delivers a new experience to configuring workload management policies.
Ambari Web based tooling allows admins to securely and easily manage their clusters on Azure without having to log in and edit configuration files on the remote cluster.
Customizable Dashboards
In HDP 2.3 we have developed customizable dashboards for a number of the most frequently used components. This allows for each customer to develop a tailored experience for their environment and decide which metrics they care about most. Shown below is the HDFS Dashboard:
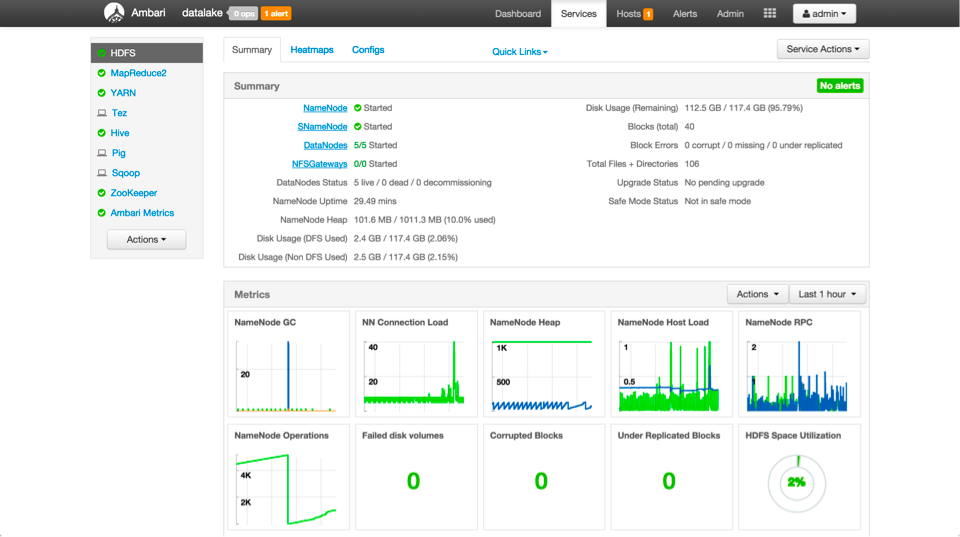
Enterprise Readiness: Enhancements to Security, Governance, and Operations
HDP 2.3 delivers new encryption of data-at-rest, extends the data governance initiative with Apache Atlas, and drives forward operational simplification for both on-premise and cloud-based deployments.
This release expands the fault tolerance capabilities of the platform to withstand failures – with high availability configuration options for Apache Storm, Apache Ranger, and Apache Falcon that power many mission critical applications and services.
In HDP 2.3, a number of significant security enhancements are being delivered. The first of which is the HDFS Transparent Data at Rest Encryption. This is a critical feature for Hadoop and we have been performing extensive testing as part of an extended technical preview. As part of providing support for HDFS Transparent Data at Rest Encryption, Apache Ranger provides a key management service (KMS) that leverages the Key Management Provider API and can be directly leveraged to provide a central key service for Hadoop. There is more work to be done related to encrypting data at rest, but we have confidence that a core set of use cases are ready for customers to adopt and we will continue to expand the capabilities and eliminate a variety of limitations over the coming months.
Other important additions related to Apache Ranger included providing centralized authorization for Apache Solr and Apache Kafka. Security administrators can now define and manage security policies and capture security audit information for HDFS, Hive, HBase, Knox, and Storm along with Solr and Kafka.
Shifting to data governance, we launched the Data Governance Initiative (DGI) in January of 2015 and then delivered the first set of technology along with an incubator proposal to the Apache Software Foundation in April. Now the core set of metadata services are being delivered along with HDP 2.3. This is really the first step on a journey to address data governance in a holistic way for Hadoop. Some of the initial capabilities will ease data discovery with a focus on Hive and establish a strong foundation for the future feature additions as we look to tackle Kafka, Storm, and integrating dynamic security policies based on the available metadata tags.
In addition to the new user interface elements described earlier, Apache Falcon enables Apache Hive database replication in HDP 2.3. Previously, Falcon provided support for replication of files (and incremental Hive partitions) between clusters, primarily to support disaster recovery scenarios. Now customers can use Falcon to replicate Hive databases, tables and their underlying metadata — complete with bootstrapping and reliably applying transactions to targets.
Finally on the operations front, the pace of Apache Ambari innovations continues to astonish. As part of HDP 2.3, Ambari arrives with support for significantly wider range of component deployment and monitoring support than ever before. This includes the abilities to install and manage: Accumulo, DataFu, Mahout, and the Phoenix Query Server (Tech Preview) along with expanding its ability to configure the NFS Gateway capability of HDFS. In addition, Ambari now provides support for rack awareness – allowing you to define and support the visualization of your data topology by rack.
We introduced the automation for rolling upgrade as part of Ambari 2.0, but this was primarily focused on automating the application of maintenance releases to your running cluster. Now, Ambari expands its reach to support rolling upgrade for feature bearing releases as well. Automating the ability for you to roll from HDP 2.2 to HDP 2.3.
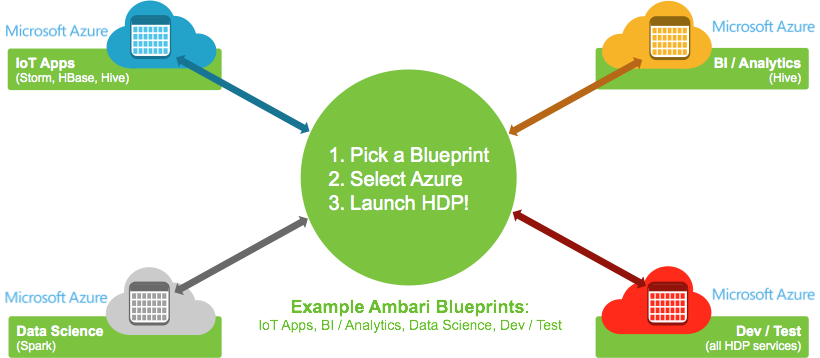
Following the general availability of HDP 2.3, Cloudbreak will also become generally available. Since the acquisition of SequenceIQ, the integrated team has been working hard to complete the deployment automation for public clouds like Microsoft Azure.
With Cloudbreak, operators will be able to seamlessly deploy elastic HDP clusters to Azure IaaS virtual machines. HDP will efficiently utilize Azure resources, with policy-based autoscaling to expand and contract clusters based upon actual usage metrics.
Operators will be able to deploy using a Cloudbreak web interface as well as a RESTful API.
Proactive Support with Hortonworks SmartSense™
In addition to all of the tremendous platform innovation, Hortonworks is proud to announce Hortonworks SmartSense which adds proactive cluster monitoring and delivers critical recommendations to customers who opt into this extended support capability. The addition of Hortonworks SmartSense further enhances Hortonworks’ world-class support for Hadoop.
Hortonworks’ support subscription customers simply download the Hortonworks Support Tool (HST) from the support portal and deploy it to their cluster. HST then collects configuration and other operational information about their HDP cluster and packages it up into a bundle. After uploading this information bundle to the Hortonworks’ support team, we use our platform to analyze all the information it provides using more than 80 distinct checks performed across the underlying operating system, HDFS, YARN, MapReduce, Tez, and Hive components.
Of course, there is so much more that I didn’t cover here which is also part of HDP 2.3! There has been meaningful innovation within Hive for supporting Union within queries and using interval types in expressions, additional improvements for HBase, Phoenix, and more. But, for now, I’ll leave those for subsequent blog posts that will highlight them all in more detail.
In closing, I would like to thank the entire Hortonworks team and the Apache community – including Microsoft developers – for the hard work put in over the past six to eight months. That hard work is about to pay off in a big way for folks adopting Hadoop today as much as it will delight those who have been using Hadoop for years.