


How to future-proof and secure your organisation against cyberattacks
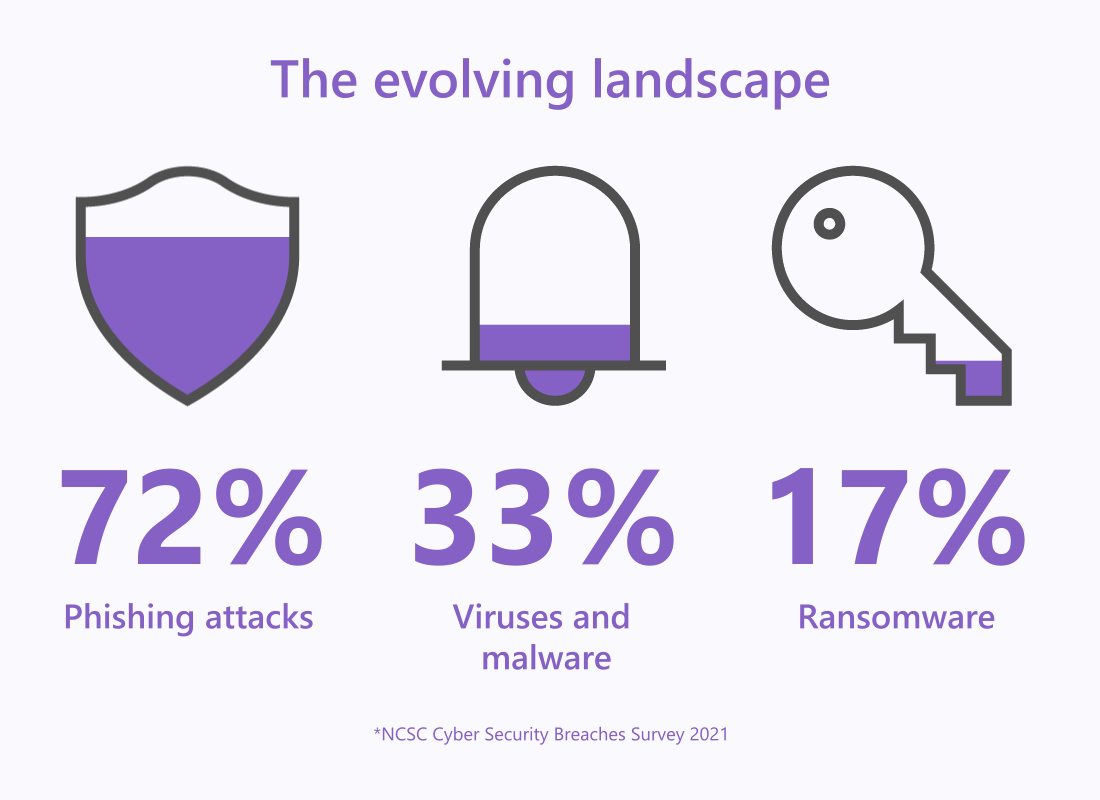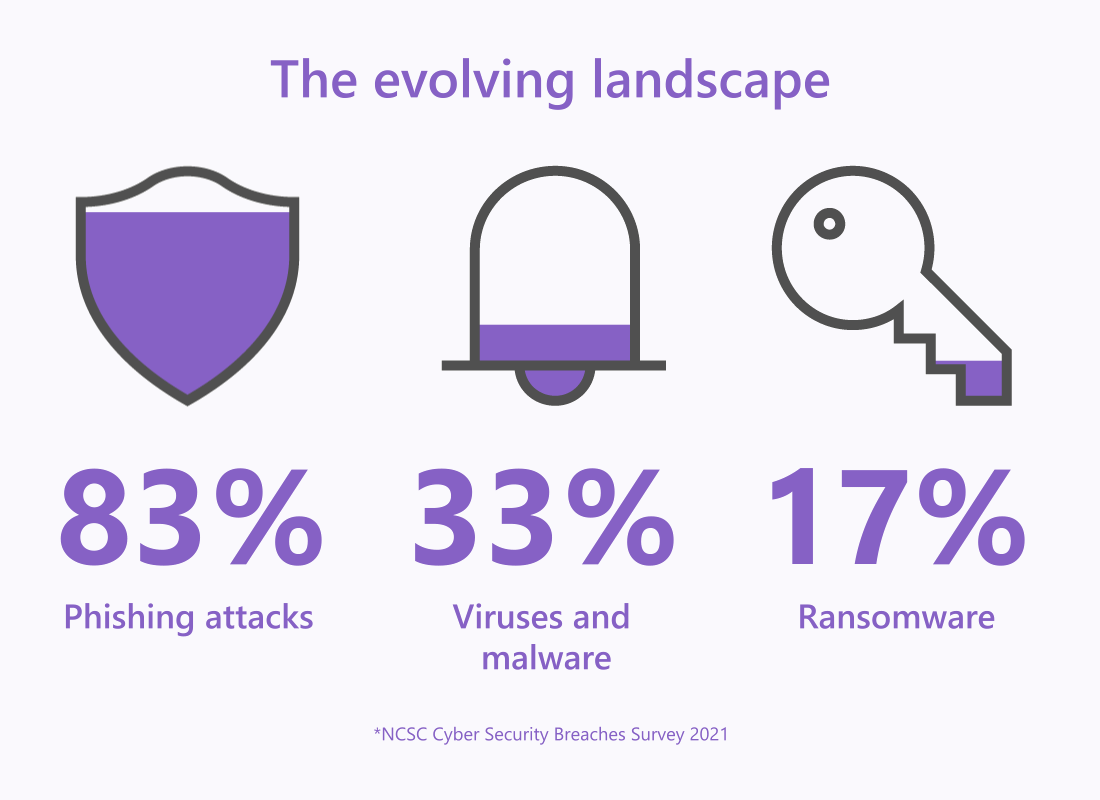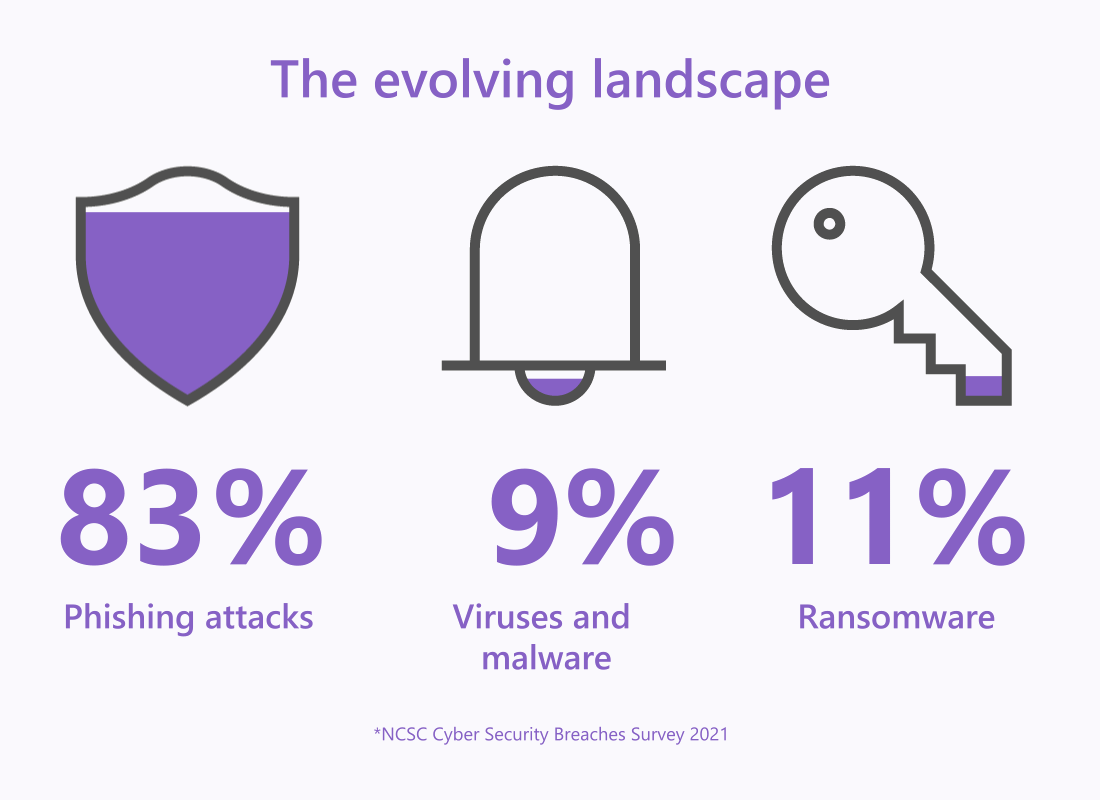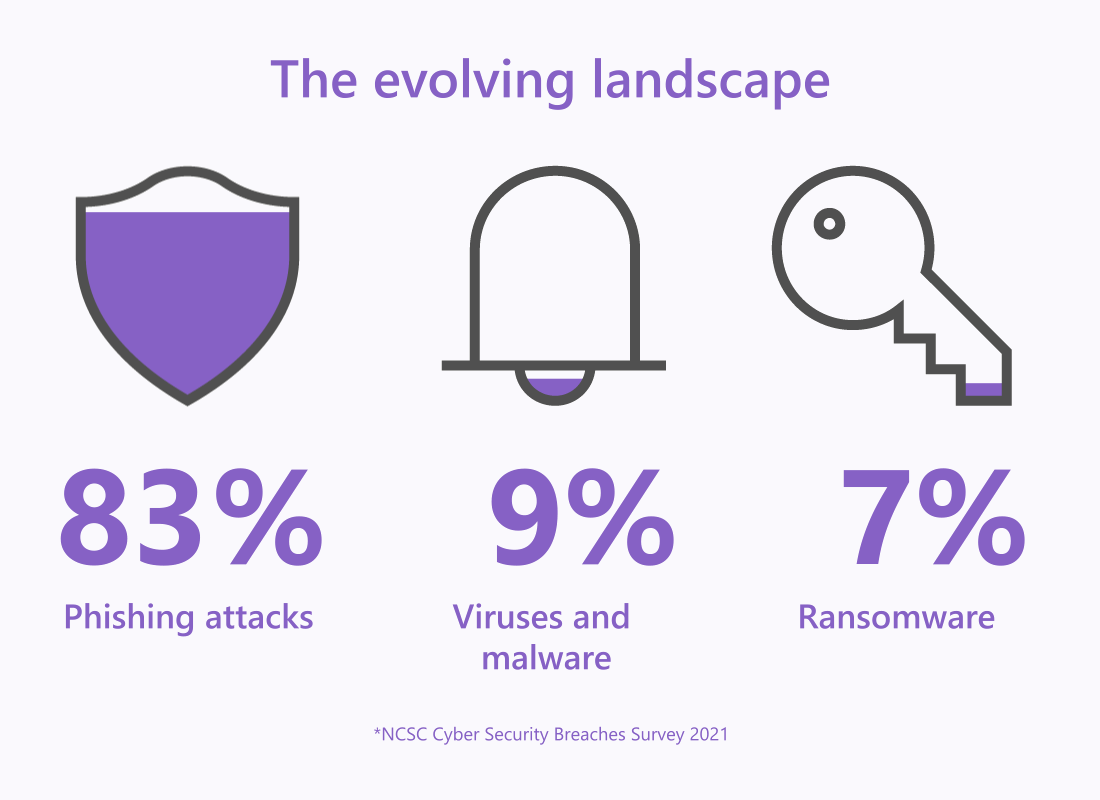
The evolving threat landscape has highlighted how attackers are refining their tactics and techniques. It also shows just how far they’re willing to go to disrupt organisations with cyberattacks.
Let’s take the example of human-operated ransomware, and the deliberate targeting of critical infrastructure. This is designed to cause as much financial, operational and societal impact as possible. Additionally, this is often compounded by the pressure from consumers, media and government – and one where core supply chains are cut off or severely disrupted. While the motivation of the cyberattack varies, there is a rise of recklessness. Attackers go beyond disruption into destruction as they learn how to combat and evade security defences. This puts business leaders in a position where they feel they have limited options. With the response likely to play out in the public domain, they often feel like they must pay the extortion demands either to restore services or prevent further disruption.

Enterprise resilience is needed to recover from human-operated cyberattacks. This goes beyond just cyber resilience. It requires a multi-faceted business, technology and operational response to recover services as quickly and effectively as possible across all domains. Resilience is the ability of the business to recover from failures and continue to function, in adverse conditions. It’s not about avoiding failures. It’s about taking proactive action to detect and respond to failures in a way that reduces downtime or data loss.
In the Microsoft Societal Resilience research program, we define resilience as the capacity to anticipate, absorb, and adapt to disruption. As Dr Peter Lee, Microsoft CVP of Research and innovations, says: “If we don’t acknowledge our risks, we can’t anticipate and prepare for them”. This is especially true in today’s world of radical innovation, where the threat actors often move faster than organisations do.

Planning for enterprise resilience against cyberattacks
Business continuity and information protection are absolute requirements for every business. But it can often entail cost, complexity, compliance, and resource to maintain. Using a cloud-based strategy helps to mitigate many of these issues. Building reliable and secure systems in the cloud is a shared responsibility. The reliability ‘of ‘the cloud is the responsibility of the cloud service provider. The reliability ‘in’ the cloud is the responsibility of the organisation. However, according to the National Cyber Security Centre, only three in 10 businesses have business continuity plans that cover cybersecurity.
How to build a secure cloud strategy

Those new to cloud should begin with Azure’s Cloud Adoption Framework, to determine business drivers and strategy. The Microsoft Azure Well-Architected Framework is a set of guiding tenants that architects, developers and solution owners can use to build and optimise reliable, secure and resilient services in the cloud.
Design for reliability and security
Designing for reliability requires an assume failure mindset. Designing for security requires an assume compromise mindset.
Cybersecurity is hard to mitigate for. Adversaries are working to counteract the business continuity strategy by actively adapting and navigating the controls that the business has implemented. If a plan is too rigid and does not anticipate change, it can often fail as the business is not able to react and pivot quickly enough to the ferocity of change or cyberattacks.
Machine learning and AI can take the pressure off IT or security teams with real-time threat detection and automation. This allows them to focus on higher value tasks, such as designing resilient workloads.
Choose the right workload
Designing workloads that are resistant to both natural disasters and malicious human intervention such as cyberattacks requires a thoughtful combination of high availability, disaster recovery and backup solutions. Across the whole environment, you need to consider how likely the primary control is to fail and the potential organisational risk if it does. Additionally, you need to counteract any of these with mitigating factors.
- High availability (HA): The ability of the application or service to continue running in a healthy state, without significant downtime.
- Disaster recovery (DR): The ability to recover from rare but wide-scale failures. For example, service disruption that affects an entire region.
- Data backup: A critical part of resiliency, distinct from storage redundancy solutions.
You can specifically address HA and DR needs with storage redundancy solutions that simultaneously replicate data and services to an alternative location. However, a secondary location can be impacted at the same time a near-real-time attack encrypts data in a primary location. This results in data loss or corruption.
When designing a backup solution for business-critical data in the cloud consider a tertiary, immutable backup (write-once-read-many). This is both physically and logically held away from any primary and secondary backups. As a result, there is another layer of protection against data loss, corruption, or malicious encryption. This is a good option for highly sensitive and regulated entities who are required to legally hold data. Azure Backup provides security features to help protect backup data even after deletion; one such feature is soft delete. If a backup is accidentally or maliciously deleted, soft delete retains it for an extra 14 days. Remember, regularly validate and test backup and restore procedures.
Protect privileged identities against cyberattacks
Often one of the most overlooked part of resilience is protecting the identities that have access to backups. As a result, compromised accounts can be used maliciously to encrypt or delete backups. Even in the example of soft delete, a compromised account with the appropriate rights can disable the feature before deleting backups.
Attackers deliberately target these resources because it impacts the ability to recover. Mitigate this by granting accounts the minimum privilege required to accomplish their assigned tasks. Limit the number of accounts with access to backups (but with a break-glass account included). Protect these with multi-factor authentication (MFA), which stops 99.9% of account compromise attacks. You should also consider just-in-time and just-enough access using dedicated privileged access workstations (PAWS). Log and monitor all changes for verification and compliance.
Validate your response to cyberattacks
 To truly know if your strategy can hold up against cyberattacks, you need to successfully measure reliability and security to and understand the resilience of that system. This means testing end-to-end workloads against a range of severe but plausible scenarios.
To truly know if your strategy can hold up against cyberattacks, you need to successfully measure reliability and security to and understand the resilience of that system. This means testing end-to-end workloads against a range of severe but plausible scenarios.
Chaos engineering is the practice of subjecting cloud applications and services to real world failures and dependency disruptions to build, measure and improve resilience. Fault injection is the deliberate introduction of a failure into a system to validate robustness and error handling.
We use fault injection at Microsoft to induce a major failure or disaster and validate both the recovery and incident management processes. We place strict access controls around this capability to prevent accidents or malicious attacker abuse to safeguard and limit the impact of the testing. This enables the business and IT to consider and prepare for a range of scenarios that determine the robustness and design of the overall solution in a safe environment. It also increases the resilience and confidence in Azure and our services.
Microsoft Ignite 2021 provided a first look at Azure Chaos Studio which is our upcoming native chaos engineering and fault injection service. This will help organisations to measure, understand, and improve the resilience of their Azure applications.
Anticipate and adapt
Organisations require a level of preparedness that anticipates and adapts to a range of scenarios, whether accidental or malicious. The strategy needs to be flexible to adapt to the evolving threat landscape and be capable of delivering effective and scalable enterprise-wide recovery.
The good news is that cloud architectures can help improve enterprise resilience goals whilst enabling effective business continuity.
Find out more
Learn more about backup and disaster recovery
Human-operated ransomware attacks: A preventable disaster
Rapidly protect against ransomware and extortion
Resources to empower your development team
Cybersecurity best practices to implement highly secured devices
Introduction to cybersecurity learning path
Data discovery, classification and protection learning path
About the authors

Sarah Armstrong-Smith is Chief Security Advisor in Microsoft’s Cybersecurity Solutions Area. She principally works with strategic customers across Europe, to help them evolve their security strategy and capabilities to support digital transformation and cloud adoption.
Sarah has a background in business continuity, disaster recovery, data protection and privacy, as well as crisis management. Combining these elements means she operates holistically to understand the cybersecurity landscape, and how this can be proactively enabled to deliver effective operational resilience.
Sarah is recognised as one of the most influential women in UK Tech and UK cybersecurity. She regularly contributes to thought leadership and industry publications.

Previously lead investigator for Microsoft’s detection and response team (DART), Lesley Kipling has spent more than 17 years responding to our customers’ largest and most impactful cybersecurity incidents. As Chief Cybersecurity Advisor, she now provides customers, partners and agencies around the globe with deep insights into how and why security incidents happen, how to harden defences and more importantly, how to automate response and contain attacks with the power of the cloud and machine learning. She holds a Master of Science in Forensic Computing from Cranfield University in the United Kingdom.


