
Change the Game with APS and PolyBase
 Guest blog post by: James Rowland-Jones (JRJ), SQL Server MVP, PASS Board Director, SQLBits organiser and owner of The Big Bang Data Company (@BigBangDataCo). James specializes in Microsoft Analytics Platform System and delivers scale-out solutions that are both simple and elegant in their design. He is passionate about the community, sitting on both the PASS Board of Directors and the SQLBits organising committee. He recently co-authored a book on Microsoft Big Data Solutions and also authored the APS training course for Microsoft. You can find him on LinkedIn (JRJ) and Twitter (@jrowlandjones).
Guest blog post by: James Rowland-Jones (JRJ), SQL Server MVP, PASS Board Director, SQLBits organiser and owner of The Big Bang Data Company (@BigBangDataCo). James specializes in Microsoft Analytics Platform System and delivers scale-out solutions that are both simple and elegant in their design. He is passionate about the community, sitting on both the PASS Board of Directors and the SQLBits organising committee. He recently co-authored a book on Microsoft Big Data Solutions and also authored the APS training course for Microsoft. You can find him on LinkedIn (JRJ) and Twitter (@jrowlandjones).
* * * * *
On April 15, 2014 Microsoft announced the next evolution of their Modern Data Warehouse strategy; launching the Analytics Platform System (APS). APS is an important step for many reasons. However, to me, the most important of those reasons is that it helps businesses complete the jigsaw on business data. In this blog post I am going to define what I mean by business data and explain how PolyBase has evolved; providing the bridge between heterogeneous data sources. In short, we are going to put the “Poly” in PolyBase.
Business Data
Business data comes in a variety of forms and exists in a diverse set of data sources. Those forms are sometimes described using terms such as relational, non-relational, structured, semi-structured or even un-structured. However, whatever term you choose to use doesn’t really matter. What matters is that the business has generated it and its employees (a.k.a. the users) need to be able to access said data, integrate it and draw data insights from it. This data is often disparate; spread liberally across the enterprise.
These users don’t see themselves as technical (although many are) and are often frustrated by the barriers created by having disparate data in a variety of forms. Having to write separate queries for different sources is difficult, time-consuming and raises many data quality challenges. I am sure you have seen this many times before. However, in the world of analytics the latency introduced by this kind of data integration is the real killer. By the time the data integration barrier has been solved the value of the insight has diminished. Consequently, business users need to have frictionless access to all of the data, all of the time.
In the modern world, there is only data, questions and a desire for answers. To enhance adoption we also need *something* that delivers using simple, familiar tools leveraging commodity technology and offering both high performance and low latency.
That *something* is PolyBase – underpinned by APS.
PolyBase
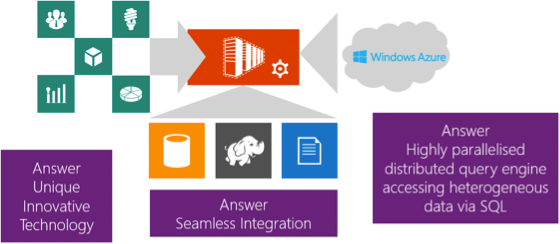
What is PolyBase, how does it work, and why is it such an important, innovative technology?
Put simply – it’s the bridge to your business data.
Why is it important? It is unique, innovative technology and it is available today in APS.
PolyBase was created by the team at the Jim Gray Systems Lab, led by Dr David DeWitt. Dr DeWitt is a technical fellow at Microsoft (i.e. he is important) and he’s also been a PASS Summit key-note speaker for several years. If you’ve never seen any of his presentations then you should absolutely address that. They are all free to watch and are available now; including a great session on PolyBase.
As I mentioned a moment ago, PolyBase is a bridge but it’s not just any old bridge. It is a fully parallelised super-highway for data. It’s like having your own fibre-optic bridge when everyone else has a copper ADSL bridge. It offers fast, run-time integration across relational data stored in APS and non-relational data stored in both Hadoop and Microsoft Azure Storage Blobs.
Notice I didn’t just say the new Hadoop Region in APS – I just said Hadoop. That’s because PolyBase is different. It is agnostic, not proprietary, in its approach and in its architecture. PolyBase integrates with Hadoop clusters that reside outside the appliance just as it does with the new Hadoop Region that exists inside the appliance. This agnostic approach is also evident in its Hadoop distribution support; covering both Hortonworks (HDP) on both Windows and Linux and Cloudera (CDH) on Linux.
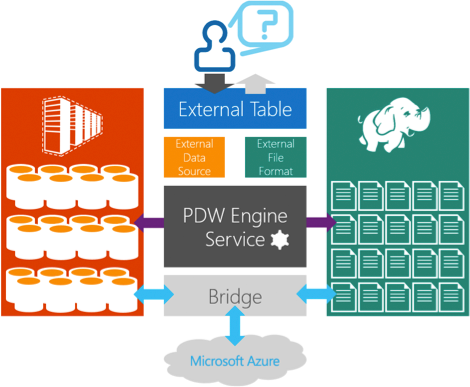
To achieve this unparalleled level of agnosticism, PolyBase uses a well-established enterprise pattern of employing “external tables” to provide the metadata of the external data. However, PolyBase takes this concept further by de-coupling the format and the data source from the definition of the external table.

This enables PolyBase to access data in a variety of sources and data formats, including RCFiles and Microsoft Azure Storage Blobs using wasb[s]. This is a key step. This process lays the foundation for other data sources to be plugged into the PolyBase architecture; putting the “Poly” in PolyBase.
Building Bridges
PolyBase builds the bridges to where the data is. Once the bridge has been defined (a simple case of a few DDL commands), PolyBase enables users to simply write queries using T-SQL. These queries can be against data in APS, Hadoop and/or Azure all at the same time. How amazing is that? I call this dynamic hybrid query execution. You can do some really clever things using hybrid queries. For example, you can read data from Hadoop, transform and enrich it in APS and persist the data back in Hadoop or Azure. That’s called round-tripping the data and that is just a taster of what is possible with hybrid query support.
There is more.
PolyBase can also leverage the computational resources available at the data source. In other words it can selectively issue MapReduce jobs against a Hadoop cluster. This is called split query execution. Like a true data surgeon, PolyBase is able to dissect a query into push-able and non-pushable expressions. The push-able ones are considered for submission as MapReduce jobs and the non-push-able parts are processed by APS.
It gets better.
The decision to push an expression is made on cost by the APS distributed query engine: Cost based split query execution against APS, Hadoop and Azure. Fantastic.
To achieve this feat PolyBase is able to hold detailed statistical information in the form of table and column level statistics. This level of knowledge about the data is lacking in Hadoop today. By having a mechanism for generating statistics APS and PolyBase can selectively assess when it is appropriate to use MapReduce and when it would be more cost-effective to simply import the data.
The results can be dramatic. Even with “small” data you can see huge data volume reduction through the MapReduce split query process and significant delegation of computation to low-cost Hadoop clusters; providing maximum efficiency and business value. Plus if you are using the APS Hadoop Region you can also draw comfort from the ultra-low latency Infiniband connection between the two regions – leading to unparalleled data transfer speeds. This offers a completely new paradigm to the world of Hadoop.
Simple, Familiar Tools
Did I mention that all this is possible with just T-SQL? Literally there is nothing to really “learn” in order to be able to write PolyBase queries. If you can write T-SQL then you can query any PolyBase-enabled data source.
That is really important.
Think about how many users know T-SQL. Having a technology that is SQL-based is massive for adoption. Many projects have failed in the adoption phase only to wither on the vine. Imagine how many of your users would be able to simply access all of their data, gaining new insights, using nothing but their existing T-SQL skills thanks to PolyBase.
PolyBase changes the game and is available now in APS.