
PolyBase in APS – Yet another SQL over Hadoop solution?
This blog post will highlight PolyBase’s truly unique approach focusing on:
- Query capabilities across various heterogeneous data sources – on-premises and cloud (Microsoft Azure) bringing Microsoft data services together forming one complete data platform solution
- Total freedom for users with no lockdown, agnostic to the actual Hadoop distribution and/or underlying operating system
- Faster insights from all your data in a simple and performing fashion allowing users to leverage their existing tools and SQL scripts
1. Bringing the relational world together with Hadoop & Cloud (Azure)
In the very recent past, various SQL over Hadoop/HDFS solutions have been developed, such as Impala, HAWQ, Stinger, SQL-H, Hadapt to name just a few. While there are clear technical differences between the various solutions, at a high level, they are similar in offering a SQL-like front end over data stored in HDFS.
So, is PolyBase yet another similar solution competing with these approaches? The answer is yes and no. On first glance, PolyBase is a T-SQL front end that allows customers to query data stored in HDFS. However, with the recently announced Analytics Platform System (APS), we have updated PolyBase with new syntax to highlight our extensible approach. With PolyBase, we bring various Microsoft data management services together and allow appliance users to leverage a variety of Azure services. This enables a new class of hybrid scenarios and reflects the evolution of PolyBase to a true multi-data source query engine. It allows users to query their big data – regardless of whether it is stored in an on-premises Hadoop/HDFS cluster, Azure storage, Parallel Data Warehouse, and other relational DBMS systems (offered in a future PolyBase release).
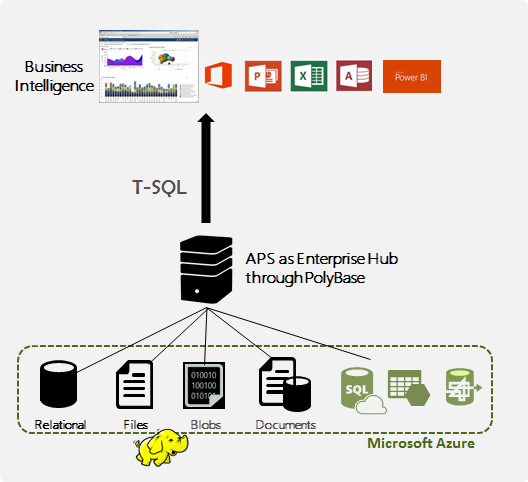
Complete Data Platform with PolyBase as key integrative component
2. Freedom of Choice
Openness
One important key differentiator of PolyBase compared to all of the existing competitive approaches is ‘openness’. We do not force users to decide on a single solution, like some Hadoop providers are pursuing. With PolyBase, you have the freedom to use an HDInsight region as a part of your APS appliance, to query an external Hadoop cluster connected to APS, or to leverage Azure services from your APS appliance (such as HDInsight on Azure).
To achieve this openness, PolyBase offers these three building blocks.
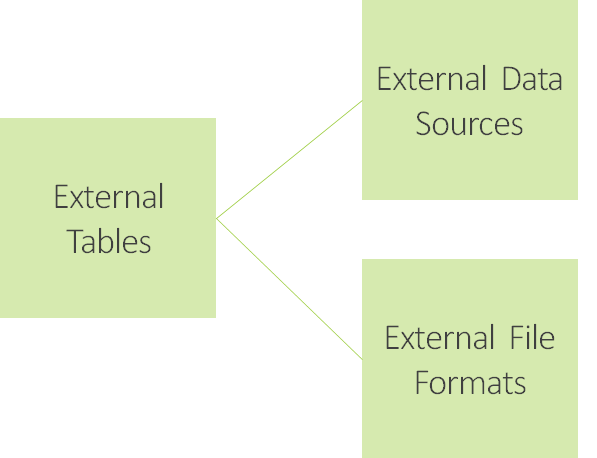
Building blocks for PolyBase
The syntax for using PolyBase is simple and follows familiar T-SQL language constructs.
T-SQL for creating external data sources (Azure, external Hadoop cluster, HDI region)
CREATE EXTERNAL DATA SOURCE Azure_DS WITH (TYPE=Hadoop, LOCATION= 'wasbs://<youraccount>.blob.core.windows.net');CREATE EXTERNAL DATA SOURCE External_HDP_DS WITH (TYPE=Hadoop, LOCATION='hdfs://…’, JOB_TRACKER_LOCATION='…');CREATE EXTERNAL DATA SOURCE HDI_DS WITH (TYPE=Hadoop, LOCATION = 'hdfs://…’, JOB_TRACKER_LOCATION = '…’);
T-SQL for creating external file formats (delimited text files and Hive RCFiles)
CREATE EXTERNAL FILE FORMAT DelimText1 WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR =','));CREATE EXTERNAL FILE FORMAT DelimText2 (FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR ='|', USE_TYPE_DEFAULT = TRUE));CREATE EXTERNAL FILE FORMAT HiveRC WITH (FORMAT_TYPE = RCFILE, SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe')
T-SQL for creating external tables (for Azure, external Hadoop cluster, HDI region)
CREATE EXTERNAL TABLE [dbo].[Old_SensorData_Azure] (…)
WITH (LOCATION='//Sensor_Data/May2009/sensordata.tbl', DATA_SOURCE Azure_DS, FILE_FORMAT = DelimText2, REJECT_TYPE = VALUE, REJECT_VALUE = 100)CREATE EXTERNAL TABLE [dbo].[SensorData_ExternalHDP] (…)
WITH (LOCATION='//Sensor_Data/May2014/sensordata.tbl', DATA_SOURCE = External_HDP_DS, FILE_FORMAT = DelimText1, REJECT_TYPE = VALUE, REJECT_VALUE = 0)CREATE EXTERNAL TABLE [dbo].[SensorData_HDI] (…)
WITH (LOCATION='//Sensor_Data/Year2013', DATA_SOURCE = HDI_DS, FILE_FORMAT = HiveRC)
A user can now create statistics for each of the external tables shown above to improve the query performance. We extended SQL Server’s mature stats framework to work against external tables in the same way it works against regular tables. Statistics are crucial for the PolyBase query engine in order to generate optimal execution plans and to decide when pushing computation into the external data source is beneficial.
Performance
While other SQL over Hadoop solutions (e.g. Impala, Stinger, and HAWQ) have improved, it remains true that they still cannot match the query performance of a mature relational MPP system. With PolyBase, the user can import data in a very simple fashion into PDW (through a CTAS statement, see below), use the fast SQL Server column store technology along with the MPP architecture, or let the PDW/PolyBase query optimizer decide which parts of the query get executed in Hadoop and which parts in PDW. This optimized querying, called split-based query processing, allows parts of the query to be executed as Hadoop MR jobs that are generated on-the-fly completely transparent for the end user. Thereby, the PolyBase query optimizer takes into account parameters such as the spin-up time for MR jobs and the generated statistics to determine the optimal query plan.
In general, if it comes to performance the answer usually is ‘it depends on the actual use case/query’. With PolyBase, the user has total freedom and can leverage capabilities of PDW and/or Hadoop based on their actual needs and application requirements.
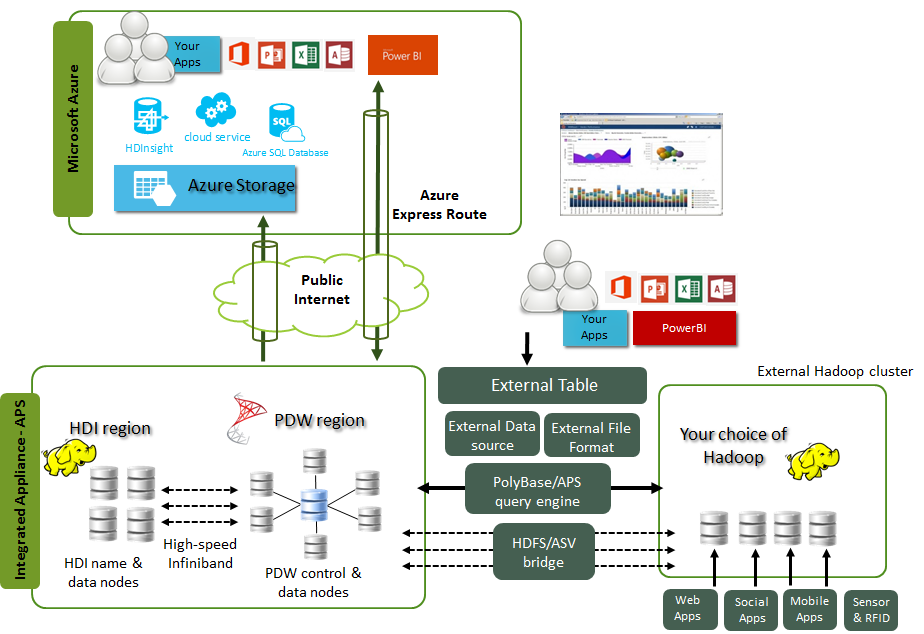
PolyBase in APS bridging the gap between the relational world, Hadoop (external or internal) and Azure
The T-SQL statement below will run across all data sources combining structured appliance data with un/semi-structured data in external Hadoop, internal HDInsight region, and Azure (e.g. historical data) –
T-SQL SELECT querying external Hadoop, HDInsight & PDW regions, and Azure
SELECT machine_name, machine.location
FROM Machine_Information_PDW, Old_SensorData_Azure, SensorData_HDI, SensorData_ExternalHDP WHERE Machine_Information_PDW.MachineKey = Old_SensorData_Azure.MachineKey and Machine_Information_PDW.MachineKey = SensorData_HDI.MachineKey and Machine_Information_PDW.MachineKey = SensorData_ExternalHDP.MachineKey and SensorData_HDI.Temperature> 80 and Old_SensorData_Azure.Temperature > 80 and SensorData_ExternalHDP.Temperature > 80
This query example shows how simplicity and performance are combined at the same time. It shows three external tables referring to three different locations plus one regular (distributed) PDW table. While executing the query, the PolyBase/PDW query engine will decide, based on the statistics, whether or not to push computation to the external data source (i.e. Hadoop).
Rewriting & Migrating existing applications
Finally, you may have heard that Hadoop is ‘cheaper’ than more mature MPP DBMS systems. However, what you might not have heard about is the cost associated with rewriting existing applications and ensuring continued tool support. This goes beyond simple demos showing that tool ‘xyz’ works on top of Hadoop/HDFS.
PolyBase does not require you to download and install different drivers. The beauty of our approach is that external tables appear like regular tables in your tool of choice. The information about the external data sources and file formats is abstracted away. Many Hadoop-only solutions are not fully SQL-ANSI compliant and do not support various SQL constructs. With PolyBase, however, you don’t need to rewrite your apps because it uses T-SQL and preserves its semantics. This is specifically relevant when users are coming from a ‘non-Java/non-Hadoop world’. You can explore and visualize your data sets either by using the Microsoft BI solutions (initiated on-premises or through corresponding Azure services) or by using the visualization tool of your choice. PolyBase keeps the user experience the same.
3. Simplified ETL & Fast Insights
It’s already a painful reality that many enterprises store and maintain data in different systems that are optimized for different workloads and applications, respectively. Admins are spending much time moving, organizing, and keeping data in sync. This reality imposes another key challenge which we are address with PolyBase – in addition to querying data in external data sources, a user can achieve a simpler and more performant ETL (extraction, transformation, loading). Different than existing connector technologies, such as SQOOP, a PolyBase user can use T-SQL statements to either import data from external data sources (CTAS) or export data to external data sources (CETAS).
T-SQL CETAS statement to age out Hadoop & PDW data to Azure
CREATE EXTERNAL TABLE Old_Data_2008_Azure WITH (LOCATION='//Sensor_Data/2008/sensordata.tbl', DATA_SOURCE=Azure_DS, FILE_FORMAT=DelimText2) AS SELECT T1.* FROM Machine_Information_PDW T1 JOIN SensorData_ExternalHDP T2 ON (T1.MachineKey = T2.MachineKey) WHERE T2.YearMeasured = 2008
Combines data from external Hadoop and PDW sources and stores the results in Azure
Under-the-covers, the PolyBase query engine is not only leveraging the parallelism of an MPP system, it also pushes computation to the external data source to reduce the data volume that needs to be moved. The entire procedure remains totally transparent for the user while ensuring a very fast import & export of data that greatly outperforms any connector technology offered today. With the CTAS statement, a user can import data into the relational PDW region where it stores the data as column store. This way, users can immediately leverage the column store technology in APS without any further action.
T-SQL CTAS statement for importing Hadoop data into PDW
CREATE TABLE Hot_Machines_2011 WITH (Distribution = hash(MachineKey), CLUSTERED COLUMNSTORE INDEX) AS SELECT * FROM SensorData_HDI where SensorData_HDI.YearMeasured = 2011 and SensorData_HDI.Temperature > 150
Combines PolyBase with column store – Imports data from Hadoop into PDW CCI tables
In summary, PolyBase is more than just another T-SQL front end over Hadoop. It has evolved into a key integrative component that allows users to query, in a simple fashion, data stored in heterogeneous data stores. There is no need to maintain separate import/export utilities. PolyBase ensures great performance by leveraging the computation power available in external data sources. Finally, the user has freedom in almost every dimension whether it’s about tuning the system and getting the best performance, choosing their tools of choice to derive valuable insights, and to leverage data assets stored both on-premises and within the Azure data platform.
Watch how APS seamlessly integrates data of all sizes and types here
Learn more about APS here