
New challenges
Businesses have always used data and analytics for improved business decisions. As the new age of the IOT (Internet of Things) approaches, businesses are experiencing exponential data growth and the challenges that come along with managing large data sets. At the same time, tools like Power Pivot democratize data access to these large data sets across the whole business. As more employees have access to these large data sets, the analytics queries asked by these employees tends to be more ad-hoc rather than queries easily answered by pre-aggregated cubes. In-Memory analytics improvements in SQL Server 2016 addresses these new challenges by providing significant data compression and speeding up analytics query performance up to 100x.
Common configuration
Traditionally, customers have modeled the data using multidimensional online analytical processing (MOLAP) with pre-aggregated data or with Tabular Model and the source of data in the database with periodic ETL (Extract, Transform and Load). The picture below shows a typical deployment using SQL Server for relational DW and SQL Server Analysis Server (SSAS) for data modelling.
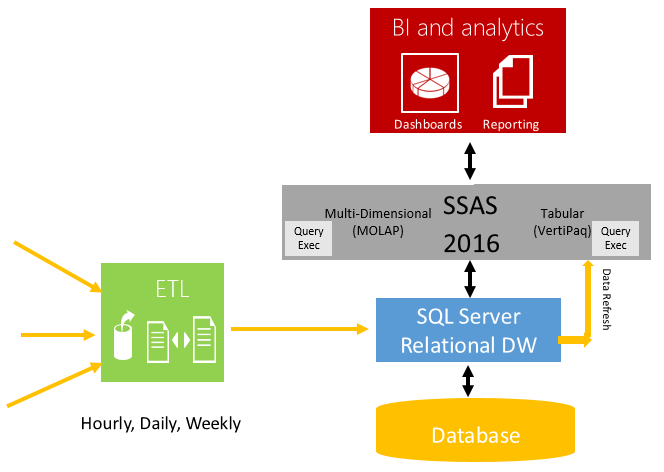 For both MOLAP and Tabular models the analytical queries run inside SSAS as shown by the blue box. This allows customers to gain the best analytical performance, even when their data sources are slow, but this approach has some challenges as described below.
For both MOLAP and Tabular models the analytical queries run inside SSAS as shown by the blue box. This allows customers to gain the best analytical performance, even when their data sources are slow, but this approach has some challenges as described below.
- Cube Processing: The data needs to be refreshed and aggregated periodically.
- Data Latency: Data is as fresh as of the last refresh cycle. For many businesses, this is increasingly unacceptable. They want the ability to run analytics immediately after the data has been loaded.
- Very Large Database Support: For massive data warehouses, it may not be feasible to load the data to a separate BI server due to resource and time limits.
In-Memory Analytics addresses these challenges by leveraging updateable clustered columnstore index (CCI) available since SQL Server 2014. Clustered columnstore indexes (CCIs) store the data in columnar storage format as shown below storing each column independently. The two key benefits of storing data in columnar storage are:
- All values of a column are stored together, and they can be compressed really well, typically 10x. This can not only reduce the storage footprint significantly, but reduces the IO/memory usage proportionally and improve the performance of analytics queries.
- Only the columns referenced in the query are read into the memory, which further reduces both IO and memory needed. This further improves the performance of analytics queries.

SQL Server executes queries on columnstore index in a special batch mode that processes set of rows together for execution efficiency. For example, when aggregating total sales for a quarter, SQL Server can aggregate around 1000 values together instead of aggregating one value at a time.
With the combination of reduced IO and BatchMode processing, analytics query performance can see up to a 100x improvement. The compression achieved and query performance will vary with workloads. Here are couple customer case studies with the usage of clustered columnstore index with SQL Server 2014. Customers can expect to get better query performance with columnstore indexes in SQL Server 2016.
- Nasdaq OMX Group
- Eastman Chemical Company
Recommended configuration
Column store indexes remove the necessity of pre-aggregating data for reporting queries, allowing configurations as shown in the picture below.
When compared with previous configuration, Analysis Services can be configured to use either ROLAP (Multi-Dimensional) or DirectQuery Mode (Tabular) mode that sends the query directly to SQL Server with data as clustered columnstore index which with 10x data compression and up to 100x speed up in analytics query processing, can reduce storage requirements significantly and eliminate the need to pre-aggregate the data for many workloads. This means the data is available for analytics immediately after it is loaded through ETL. Another point to note that SSAS Tabular (DirectQuery) mode has been improved in SQL Server 2016 to generate better queries that can give order of magnitude query performance over SSAS 2014.
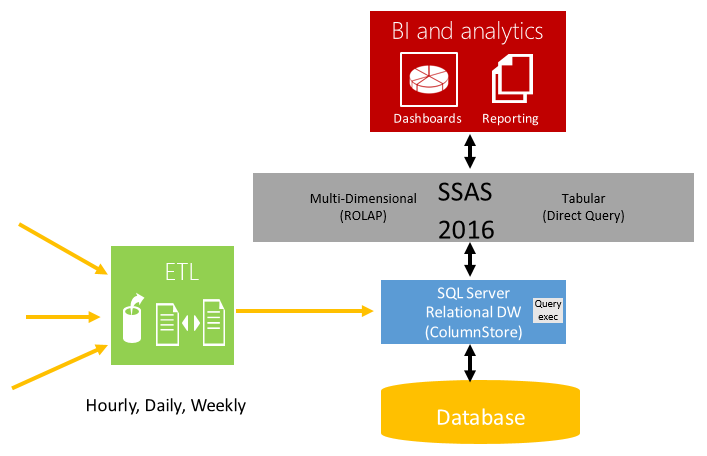 Migrating workload to use columnstore index
Migrating workload to use columnstore index
To add a column store index, simply execute the following command, dropping the existing columnstore index if it exists. Also, with columnstore indexes, you may not need some of the other indexes so you can consider dropping them.
Create clustered columnstore index <index-name> on <table>
with (drop_existing=ON)
Changes in SQL Server 2016
SQL Server 2016 has significant advancements over SQL Server 2014 for In-Memory analytics. Some highlights are functionality (e.g. ability to create traditional nonclustered indexes to enforce PK/FK constraints, performance (e.g. addition of new BatchMode operators, Aggregate pushdown), Online index defragmentation, and supportability (e.g. new DMVs, Perfmon counters and XEvents).
Recommendation
We recommend using Clustered columnstore Indexes (CCIs) for all Data Warehouse workloads. It is available in Enterprise Edition in SQL Server and in Azure SQL Database. It will benefit you in all configurations with or without Analysis Server or with any other third party visualization tools.
See the other posts in the SQL Server 2016 blogging series.

