
Today at Ignite, Microsoft announced the preview of SQL Server 2019. For 25 years, SQL Server has helped enterprises manage all facets of their relational data. In recent releases, SQL Server has gone beyond querying relational data by unifying graph and relational data and bringing machine learning to where the data is with R and Python model training and scoring. As the volume and variety of data increases, customers need to easily integrate and analyze data across all types of data.
Now, for the first time ever, SQL Server 2019 creates a unified data platform with Apache SparkTM and Hadoop Distributed File System (HDFS) packaged together with SQL Server as a single, integrated solution. Through the ability to create big data clusters, SQL Server 2019 delivers an incredible expansion of database management capabilities, further redefining SQL Server beyond a traditional relational database. And as with every release, SQL Server 2019 continues to push the boundaries of security, availability, and performance for every workload with Intelligent Query Processing, data compliance tools and support for persistent memory. With SQL Server 2019, you can take on any data project, from traditional SQL Server workloads like OLTP, Data Warehousing and BI, to AI and advanced analytics over big data.
SQL Server provides a true hybrid platform, with a consistent SQL Server surface area from your data center to public cloud—making it easy to run in the location of your choice. Because SQL Server 2019 big data clusters are deployed as containers on Kubernetes with a built-in management service, customers can get a consistent management and deployment experience on a variety of supported platforms on-premises and in the cloud: OpenShift or Kubernetes on premises, Azure Kubernetes Service (AKS), Azure Stack (on AKS) and OpenShift on Azure. With Azure Hybrid Benefit license portability, you can choose to run SQL Server workloads on-premises or in Azure, at a fraction of the cost of any other cloud provider.
SQL Server – Insights over all your data
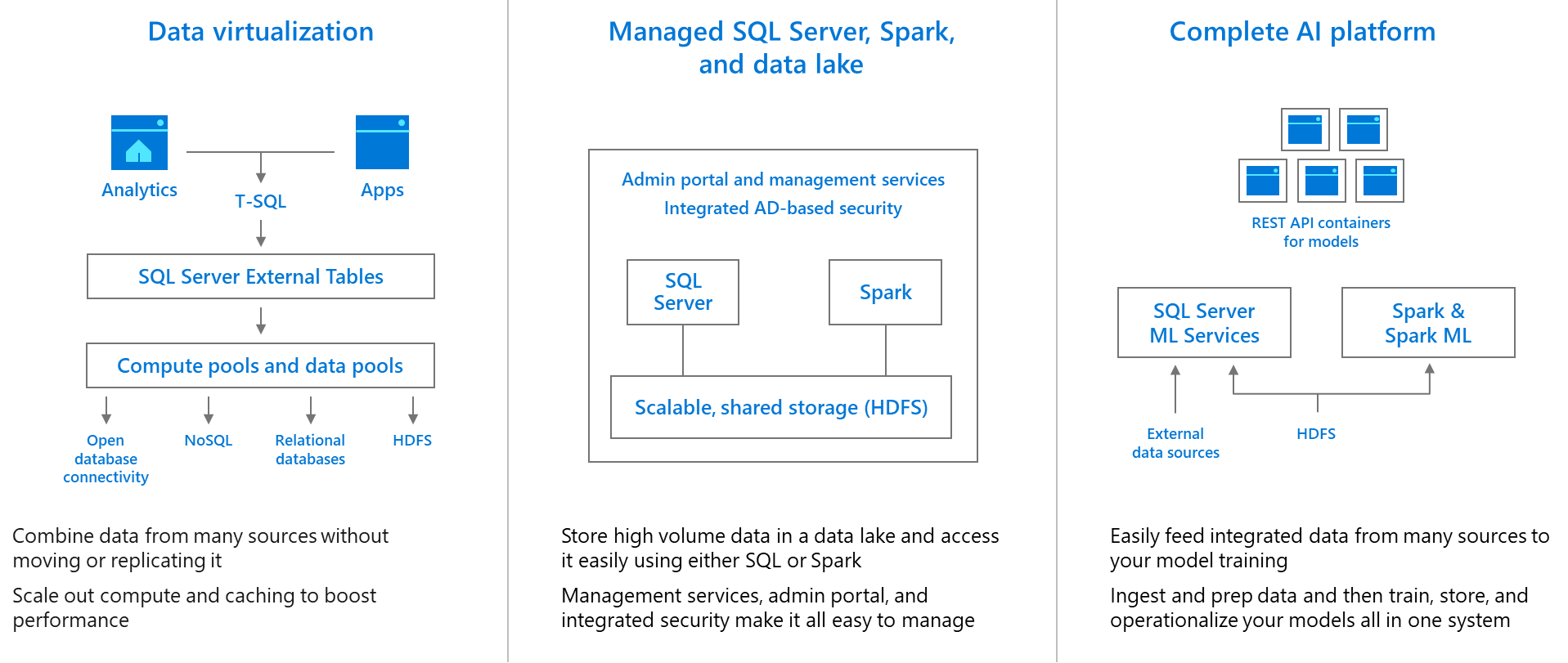
SQL Server continues to embrace open source, from SQL Server 2017 support for Linux and containers to SQL Server 2019 now embracing Spark and HDFS to bring you a unified data platform. With SQL Server 2019, all the components needed to perform analytics over your data are built into a managed cluster, which is easy to deploy and it can scale as per your business needs. HDFS, Spark, Knox, Ranger, Livy, all come packaged together with SQL Server and are quickly and easily deployed as Linux containers on Kubernetes. SQL Server simplifies the management of all your enterprise data by removing any barriers that currently exist between structured and unstructured data.
Here’s how we make it easy for you to break down barriers to realized insights across all your data, providing one view of your data across the organization:
- Simplify big data analytics for SQL Server users. SQL Server 2019 makes it easier to manage big data environments. It comes with everything you need to create a data lake, including HDFS and Spark provided by Microsoft and analytics tools, all deeply integrated with SQL Server and fully supported by Microsoft. Now, you can run apps, analytics, and AI over structured and unstructured data – using familiar T-SQL queries or people familiar with Spark can use Python, R, Scala, or Java to run Spark jobs for data preparation or analytics – all in the same, integrated cluster.
- Give developers, data analysts, and data engineers a single source for all your data – structured and unstructured – using their favorite tools. With SQL Server 2019, data scientists can easily analyze data in SQL Server and HDFS through Spark jobs. Analysts can run advanced analytics over big data using SQL Server Machine Learning Services: train over large datasets in Hadoop and operationalize in SQL Server. Data scientists can use a brand new notebook experience running on the Jupyter notebooks engine in a new extension of Azure Data Studio to interactively perform advanced analysis of data and easily share the analysis with their colleagues.
- Break down data silos and deliver one view across all of your data using data virtualization. Starting in SQL Server 2016, PolyBase has enabled you to run a T-SQL query inside SQL Server to pull data from your data lake and return it in a structured format—all without moving or copying the data. Now in SQL Server 2019, we’re expanding that concept of data virtualization to additional data sources, including Oracle, Teradata, MongoDB, PostgreSQL, and others. Using the new PolyBase, you can break down data silos and easily combine data from many sources using virtualization to avoid the time, effort, security risks and duplicate data created by data movement and replication. New elastically scalable “data pools” and “compute pools” make querying virtualized data lighting fast by caching data and distributing query execution across many instances of SQL Server.
“From its inception, the Sloan Digital Sky Survey database has run on SQL Server, and SQL Server also stores object catalogs from large cosmological simulations. We are delighted with the promise of SQL Server 2019 big data clusters, which will allow us to enhance our databases to include all our big data sets. The distributed nature of SQL Server 2019 allows us to expand our efforts to new types of simulations and to the next generation of astronomical surveys with datasets up to 10PB or more, well beyond the limits of our current database solutions.”- Dr. Gerard Lemson, Institute for Data Intensive Engineering and Science, Johns Hopkins University.
Enhanced performance, security, and availability
The SQL Server 2019 relational engine will deliver new and enhanced features in the areas of mission-critical performance, security and compliance, and database availability, as well as additional features for developers, SQL Server on Linux and containers, and general engine enhancements.
Industry-leading performance – The Intelligent Database
- The Intelligent Query Processing family of features builds on hands-free performance tuning features of Adaptive Query Processing in SQL Server 2017 including Row mode memory grant feedback, approximate COUNT DISTINCT, Batch mode on rowstore, and table variable deferred compilation.
- Persistent memory support is improved in this release with a new, optimized I/O path available for interacting with persistent memory storage.
- The Lightweight query profiling infrastructure is now enabled by default to provide per query operator statistics anytime and anywhere you need it.
Advanced security – Confidential Computing
- Always Encrypted with secure enclaves extends the client-side encryption technology introduced in SQL Server 2016. Secure enclaves protect sensitive data in a hardware or software-created enclave inside the database, securing it from malware and privileged users while enabling advanced operations on encrypted data.
- SQL Data Discovery and Classification is now built into the SQL Server engine with new metadata and auditing support to help with GDPR and other compliance needs.
- Certification Management is now easier using SQL Server Configuration Manager.
Mission-critical availability – High uptime
- Always On Availability Groups have been enhanced to include automatic redirection of connections to the primary based on read/write intent.
- High availability configurations for SQL Server running in containers can be enabled with Always On Availability Groups using Kubernetes.
- Resumable online indexes now support create operations and include database scoped defaults.
Developer experience
- Enhancements to SQL Graph include match support with T-SQL MERGE and edge constraints.
- New UTF-8 support gives customers the ability to reduce SQL Server’s storage footprint for character data.
- The new Java language extension will allow you to call a pre-compiled Java program and securely execute Java code on the same server with SQL Server. This reduces the need to move data and improves application performance by bringing your workloads closer to your data.
- Machine Learning Services has several enhancements including Windows Failover cluster support, partitioned models, and support for SQL Server on Linux.
Platform of choice
- Additional capabilities for SQL Server on Linux include distributed transactions, replication, Polybase, Machine Learning Services, memory notifications, and OpenLDAP support.
- Containers have new enhancements including use of the new Microsoft Container Registry with support for RedHat Enterprise Linux images and Always On Availability Groups for Kubernetes.
You can read more about what’s new in SQL Server 2019 in our documentation.
SQL Server 2019 support in Azure Data Studio
Expanded support for more data workloads in SQL Server requires expanded tooling. As Microsoft has worked with users of its data platform we have seen the coming together of previously disparate personas: database administrators, data scientists, data developers, data analysts, and new roles still being defined. These users increasingly want to use the same tools to work together, seamlessly, across on-premises and cloud, using relational and unstructured data, working with OLTP, ETL, analytics, and streaming workloads.
Azure Data Studio offers a modern editor experience with lightning fast IntelliSense, code snippets, source control integration, and an integrated terminal. It is engineered with the data platform user in mind, with built-in charting of query result sets, an integrated notebook, and customizable dashboards. Azure Data Studio currently offers built-in support for SQL Server on-premises and Azure SQL Database, along with preview support for Azure SQL Managed Instance and Azure SQL Data Warehouse.
Azure Data Studio is today shipping a new SQL Server 2019 Preview Extension to add support for select SQL Server 2019 features. The extension offers connectivity and tooling for SQL Server big data clusters, including a preview of the first ever notebook experience in the SQL Server toolset, and a new PolyBase Create External Table wizard that makes accessing data from remote SQL Server and Oracle instances easy and fast.
Getting started
Find additional resources and get started today by visiting the links below:
- Preview SQL Server 2019 for Windows, Linux, or Docker.
- Sign up for the Early Adoption Program to get advice and support for your project from SQL Server engineering, or to try SQL Server 2019 big data clusters.
- Download Azure Data Studio to get started with new SQL Server big data features like data virtualizations and notebooks.
