

AI assistants, designed to perform actions on behalf of users, may not be as capable as current benchmarks suggest. New research reveals that existing tests for UI grounding—the ability of assistants to locate elements in the graphical user interface (GUI)—have been overestimating the performance of visual language models (VLMs), which power these assistants.
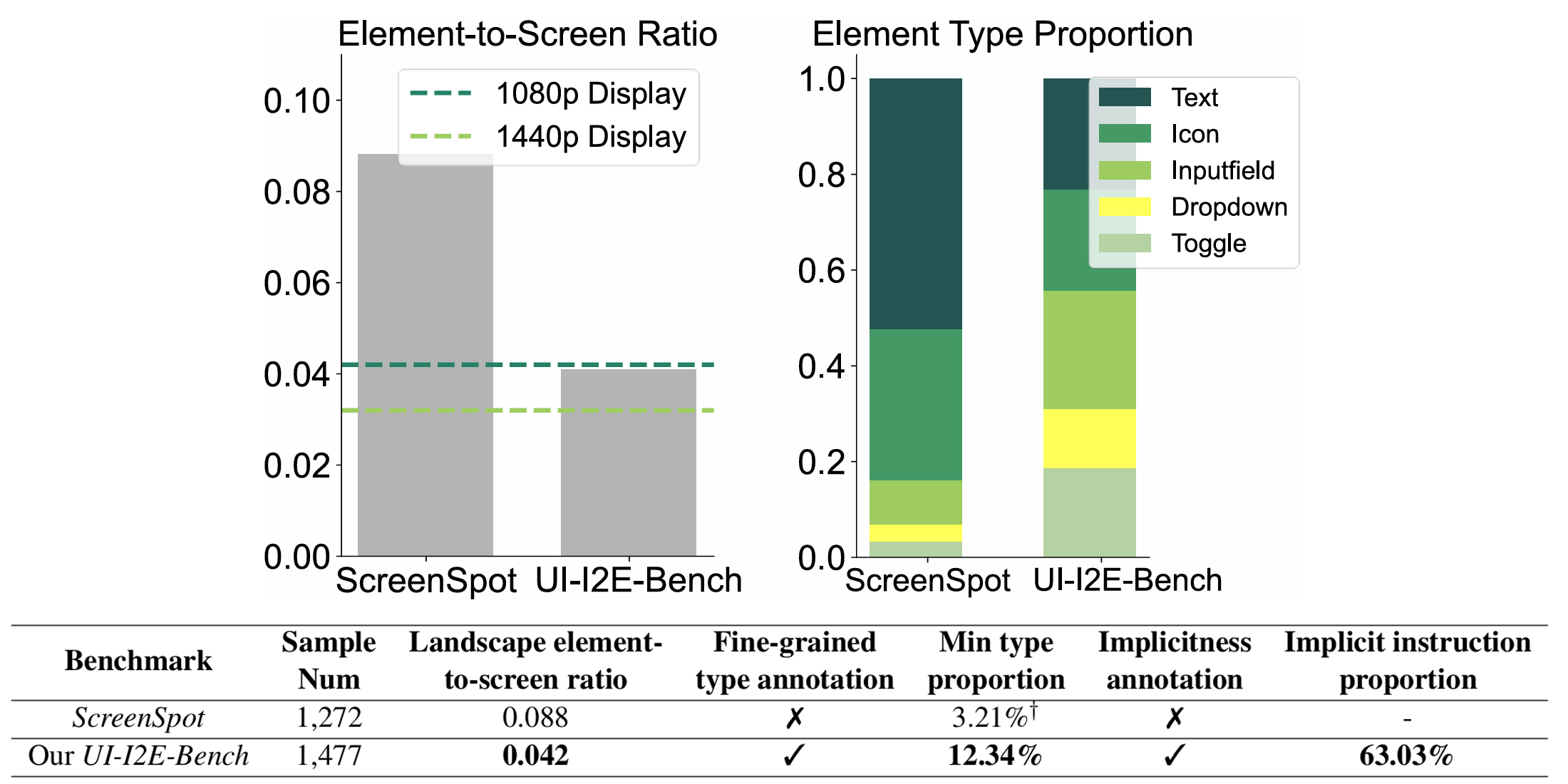
This becomes clear when comparing test conditions to real-world use. Current benchmarks use unrealistically large GUI elements—on a typical monitor, buttons and icons occupy a much smaller fraction of the screen—and test only a limited subset of element types like checkboxes and Submit buttons. Moreover, these benchmarks rely on simple, explicit instructions like “click the Save button” while neglecting the implicit language people actually use, like “click where I can change my password.”
To address this gap, a research team at Microsoft Research Asia has developed UI-E2I-Synth (opens in new tab), a large-scale data synthesis method that generates more realistic data, and UI-I2E-Bench (opens in new tab), a benchmark that better reflects actual computer use. The related paper has been accepted by The 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025) Annual Meeting of the Association for Computational Linguistics (ACL 2025)
Specifically, UI-I2E-Bench reflects typical 1080p and 1440p displays, labels whether each instruction is explicit or implicit, and includes a broader, more balanced range of UI elements compared with leading benchmarks, as shown in Figure 1.
How the system training data
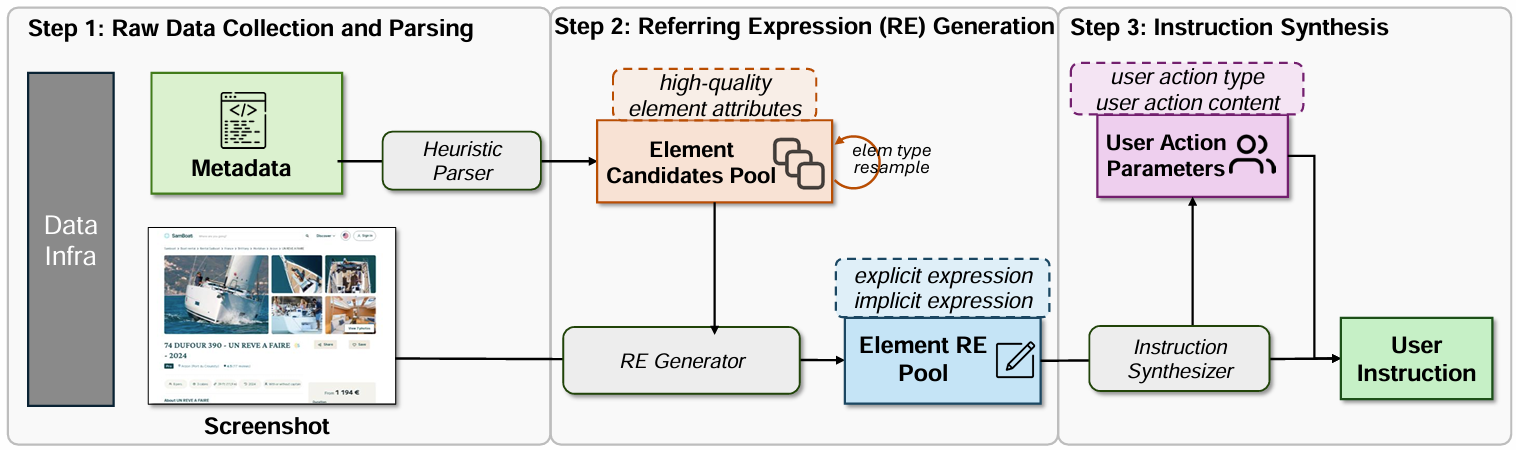
UI-E2I-Synth uses large language models (LLMs) to automatically generate realistic user instructions, reducing the manual effort required to label screenshots. The system works in three stages, each building on the previous one.
Gathering and organizing interface data. First, it collects UI screenshots and accompanying metadata from various platforms, including web pages, Windows applications, and Android interfaces. An automated tool then identifies and catalogs each UI element, recording details like whether it’s a button or text field, what it displays, and where it appears on screen. This step produces an organized catalog of UI elements that serves as the foundation for generating instructions.
Generating natural descriptions. Next, OpenAI’s GPT-4o analyzes these cataloged elements to create different ways users might realistically describe them, both explicit descriptions (e.g., “the blue Submit button in the top-right corner”) and implicit ones (e.g., “the confirmation button” or “the button next to the username”). This variety captures the range of ways users might refer to the same interface element.
Creating complete instructions. Finally, GPT-4o pairs these descriptions with specific actions to create complete, natural-sounding user instructions that reflect how people actually interact with interfaces, for example, “Click Send” or “Enter my password.” The result is a diverse set of instructions that more accurately reflects user behavior.
This process is illustrated in Figure 2.
Training and testing more realistic models
From UI-E2I-Synth’s synthesized data, the team created UI-I2E-Bench, a new benchmark that reflects real-world conditions. It includes labels identifying the type of element and whether instructions are explicit or implicit, along with a realistic element-to-screen ratio—providing a rigorous test of vision-language models’ (VLMs) GUI grounding capabilities.
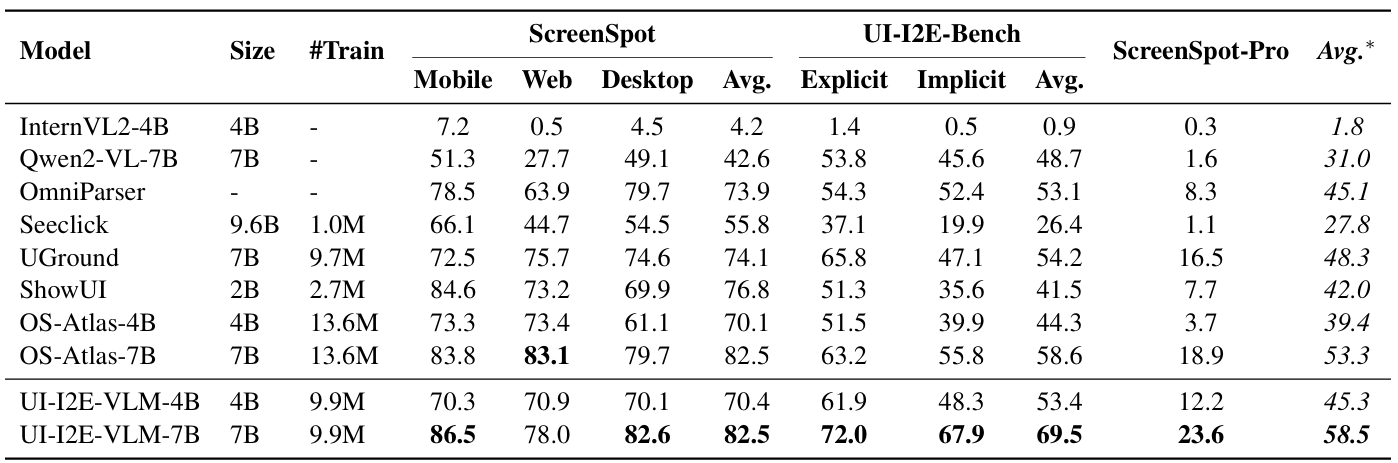
To evaluate the effectiveness of the proposed data synthesis pipeline, the team used almost 10 million individual instructions generated by UI-E2I-Synth to train two VLMs: UI-I2E-VLM-4B and UI-I2E-VLM-7B. UI-I2E-VLM-7B performed well across multiple benchmarks, including UI-I2E-Bench, using only 72% of the training data required by comparable state-of-the-art models.
The models performed especially well at handling indirect instructions and locating small elements, and more easily recognized challenging element types like icons and text entry fields. The results also confirmed that existing benchmarks overestimate model capabilities due to their unrealistically simple test conditions. The details of these results are shown in Table 1.
Diagnosing model strengths and weaknesses
The detailed labels of UI-I2E-Bench enabled the research team to analyze where models succeed and fail. The analysis revealed several key patterns.
Instruction complexity. Models showed the most improvement in handling implicit instructions. As shown in Table 2 leading models struggled with these realistic instructions, with lagging by 12 percentage points, compared with on explicit instructions. Interestingly, systems powered by GPT-4o performed well on implicit instructions but struggled with explicit ones, primarily due to difficulty in locating small elements and uncommon interface components.
Element size matters. The smaller the interface element, the more accuracy dropped across all models. This confirms that small elements and high-resolution images are critical factors in model testing. Models trained with UI-E2I-Synth, which uses more training data and processes images with higher detail, performed better in locating these small elements.
Underrepresented element types. Existing models showed clear shortcomings with less common interface elements like icons and text entry fields. By balancing the distribution of element types in training data, UI-E2I-Synth directly addresses this gap and improves model performance.

Raising the bar for UI Grounding
UI-E2I-Synth and UI-I2E-Bench address fundamental gaps in how GUI grounding models are trained and evaluated. Rather than relying on oversimplified benchmarks, this approach prepares models for the messy reality of actual computer interfaces—where elements are small, diverse, and instructions are often ambiguous.
The research establishes more rigorous standards for the field and could pave the way for AI assistants that can reliably navigate real-world software, moving these tools closer to practical deployment.


