

Computer-use agents are AI systems that autonomously navigate and interact with software applications through graphical user interfaces (GUIs), and they are emerging as a new capability in artificial intelligence. By navigating and manipulating the same visual interfaces that people use, they can perform complex tasks on behalf of users, from filling out forms to managing workflows.
Yet despite their promise, these agents perform poorly in practice. They typically draw on external knowledge—information retrieved from the web that describes how to navigate the interfaces in question—and use it to interpret what’s on the screen and adapt to different environments. However, these agents often fail to translate this knowledge into successful action—a problem researchers call the “knowledge–action gap.”
A recent study shows that even when the instructions are 90% correct, agents perform tasks successfully only 41% of the time. This disconnect between having the needed information and effectively applying it, illustrated at the top of Figure 1, can lead to a frustrating user experience.
To address this, researchers at Microsoft Research Asia developed UI-Evol, a ready-to-use component that integrates into an agent’s workflow and relies on the actual user interface for guidance. UI-Evol continuously updates its interface knowledge, helping make agents more accurate and reliable when completing tasks, as shown in the bottom of Figure 1.

This work has been recognized by the research community, with the team’s findings accepted at the ICML 2025 Workshop on Computer Use Agents (opens in new tab).
How UI-Evol works
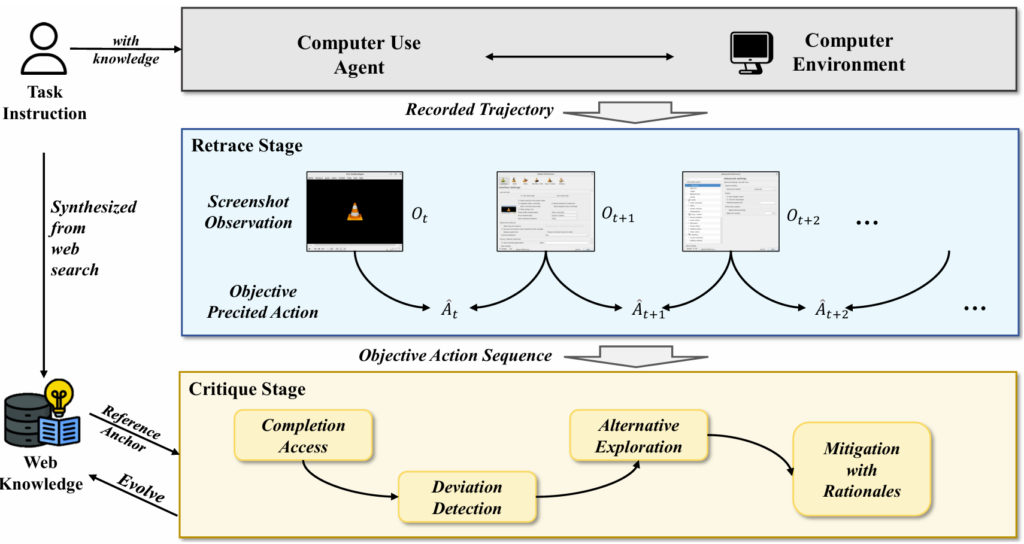
UI-Evol addresses the knowledge-action gap through a two-stage process. The first stage, called retrace, records the exact steps an agent takes to finish a task. In this way, the system captures the specific clicks, keystrokes, and other actions that led to the result.
The second stage, critique, reviews those actions against instructions drawn from outside the application. If it finds mismatches, it adjusts the knowledge so that the steps reflect what actually works in practice. Together, these two stages turn external instructions into tested, reliable guidance for agents. This process is illustrated in Figure 2.
Assessing UI-Evol’s effect on performance, reliability
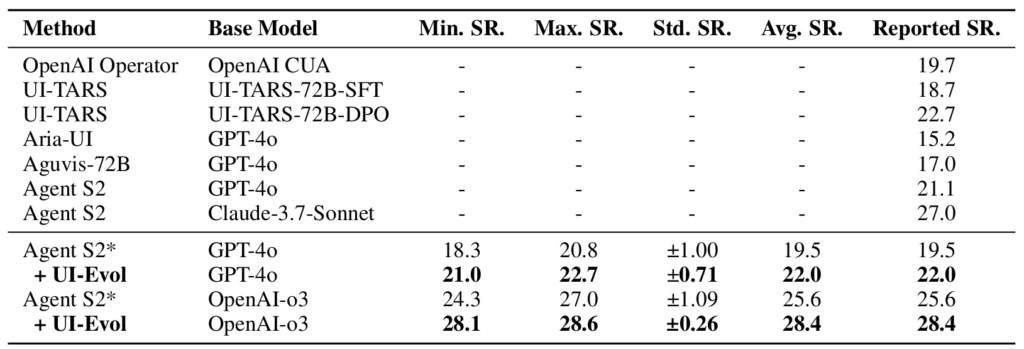
The research team tested UI-Evol on Agent S2, a state-of-the-art computer-use agent. They used the OSWorld benchmark, designed to evaluate multimodal agents on open-ended computer tasks involving real software and workflows. They found that UI-Evol not only improved performance but also made the agent’s behavior more dependable.
Computer-use agents have long shown what researchers call “high behavioral standard deviation.” In plain terms, the same agent, given the same task, may act differently each time it tries to carry it out. This unpredictability has not been a central focus of earlier work, yet it is precisely what limits agents’ usefulness in real-world applications.
With UI-Evol, that pattern shifted. Experiments with agents based on leading LLMs, like GPT-4o and OpenAI-o3, showed not only higher success rates (Table 1) but also greater consistency with UI-Evol.
What this means for practical AI
The introduction of UI-Evol tackles a problem that has long challenged computer use agents since their inception: the gap between what they know and what they can reliably do. As these agents move from research labs to real-world settings such as office automation, virtual assistants, and robotic process automation on software, consistency matters as much as capability.
UI-Evol’s approach—learning from actual agent behavior rather than relying on external knowledge alone—offers a path forward. It’s not only about making agents smarter; it’s about making them dependable enough to trust with real work.


