AI agents are reshaping software development, from writing code to carrying out complex instructions. Yet LLM-based agents are prone to errors and often perform poorly on complicated, multi-step tasks. Reinforcement learning (RL) is an approach where AI systems learn to make optimal decisions by receiving rewards or penalties for their actions, improving through trial and error. RL can help agents improve, but it typically requires developers to extensively rewrite their code. This discourages adoption, even though the data these agents generate could significantly boost performance through RL training.
To address this, a research team from Microsoft Research Asia – Shanghai has introduced Agent Lightning. This open-source (opens in new tab) framework makes AI agents trainable through RL by separating how agents execute tasks from model training, allowing developers to add RL capabilities with virtually no code modification.
Capturing agent behavior for training
Agent Lightning converts an agent’s experience into a format that RL can use by treating the agent’s execution as a sequence of states and actions, where each state captures the agent’s status and each LLM call is an action that moves the agent to a new state.
This approach works for any workflow, no matter how complex. Whether it involves multiple collaborating agents or dynamic tool use, Agent Lightning breaks it down into a sequence of transitions. Each transition captures the LLM’s input, output, and reward (Figure 1). This standardized format means the data can be used for training without any additional steps.

Hierarchical reinforcement learning
Traditional RL training for agents that make multiple LLM requests involves stitching together all content into one long sequence and then identifying which parts should be learned and which ignored during training. This approach is difficult to implement and can create excessively long sequences that degrade model performance.
Instead, Agent Lightning’s LightningRL algorithm takes a hierarchical approach. After a task completes, a credit assignment module determines how much each LLM request contributed to the outcome and assigns it a corresponding reward. These independent steps, now paired with their own reward scores, can be used with any existing single-step RL algorithm, such as Proximal Policy Optimization (PPO) or Group Relative Policy Optimization (GRPO) (Figure 2).
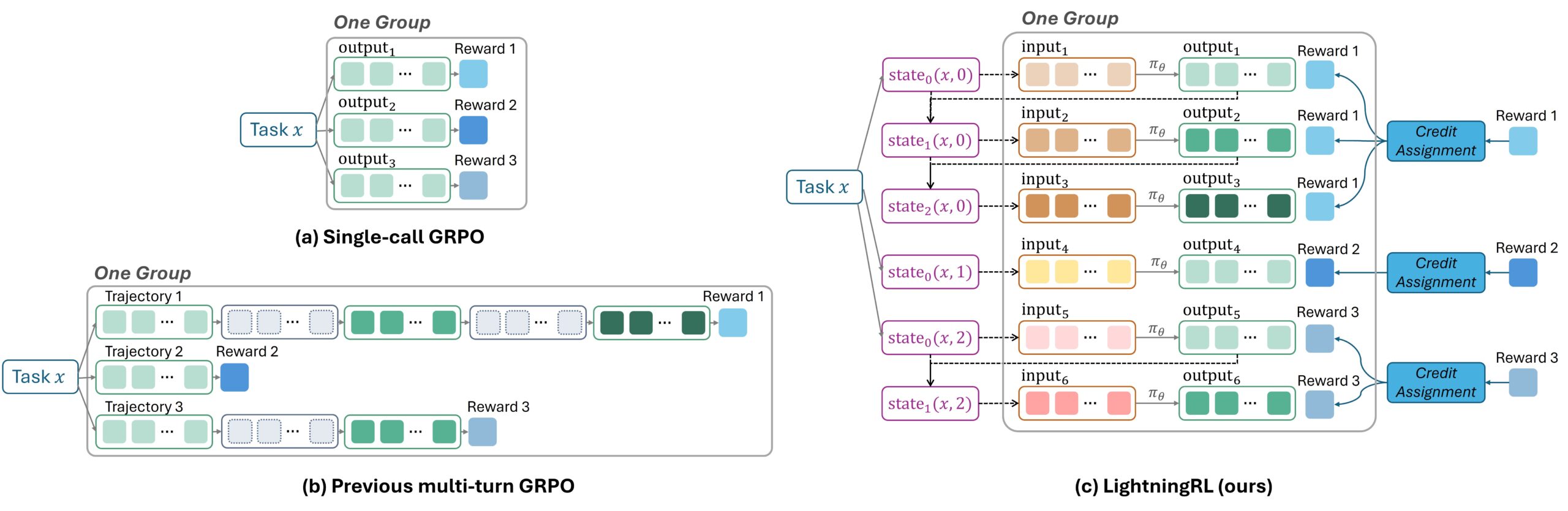
This design offers several benefits. It remains fully compatible with widely used single-step RL algorithms, allowing existing training methods to be applied without modification. Organizing data as a sequence of independent transitions lets developers flexibly construct the LLM input as needed, supporting complex behaviors like agents that use multiple tools or work with other agents. Additionally, by keeping sequences short, the approach scales cleanly and keeps training efficient.
Agent Lightning as middleware
Agent Lightning serves as middleware between RL algorithms and agent environments, providing modular components that enable scalable RL through standardized protocols and well-defined interfaces.
An agent runner manages the agents as they complete tasks. It distributes work and collects and stores the results and progress data. It operates separately from the LLMs, enabling them to run on different resources and scale to support multiple agents running concurrently.
An algorithm trains the models and hosts the LLMs used for inference and training. It orchestrates the overall RL cycle, managing which tasks are assigned, how agents complete them, and how models are updated based on what the agents learn. It typically runs on GPU resources and communicates with the agent runner through shared protocols.
The LightningStore (opens in new tab) serves as the central repository for all data exchanges within the system. It provides standardized interfaces and a shared format, ensuring that the different components can work together and enabling the algorithm and agent runner to communicate effectively.

All RL cycles follow two steps: (1) Agent Lightning collects agent execution data (called “spans”) and store them in the data store; (2) it then retrieves the required data and sends it to the algorithm for training. Through this design, the algorithm can delegate tasks asynchronously to the agent runner, which completes them and reports the results back (Figure 4).

One key advantage of this approach is its algorithmic flexibility. The system makes it easy for developers to customize how agents learn, whether they’re defining different rewards, capturing intermediate data, or experimenting with different training approaches.
Another advantage is resource efficiency. Agentic RL systems are complex, integrating agentic systems, LLM inference engines, and training frameworks. By separating these components, Agent Lightning makes this complexity manageable and allows each part to be optimized independently
A decoupled design allows each component to use the hardware that suits it best. The agent runner can use CPUs while model training uses GPUs. Each component can also scale independently, improving efficiency and making the system easier to maintain. In practice, developers can keep their existing agent frameworks and switch model calls to the Agent Lightning API without changing their agent code (Figure 5).

Evaluation across three real-world scenarios
Agent Lightning was tested on three distinct tasks, achieving consistent performance improvements across all scenarios (Figure 6):
Text-to-SQL (LangChain): In a system with three agents handling SQL generation, checking, and rewriting, Agent Lightning simultaneously optimized two of them, significantly improving the accuracy of generating executable SQL from natural language queries.
Retrieval-augmented generation (OpenAI Agents SDK implementation): On the multi-hop question-answering dataset MuSiQue, which requires querying a large Wikipedia database, Agent Lightning helped the agent generate more effective search queries and reason better from retrieved content.
Mathematical QA and tool use (AutoGen implementation): For complex math problems, Agent Lightning trained LLMs to more accurately determine when and how to call the tool and integrate the results into its reasoning, increasing accuracy.

Enabling continuous agent improvement
By simplifying RL integration, Agent Lightning can make it easier for developers to build, iterate, and deploy high-performance agents. We plan to expand Agent Lightning’s capabilities to include automatic prompt optimization and additional RL algorithms.
The framework is designed to serve as an open platform where any AI agent can improve through real-world practice. By bridging existing agentic systems with reinforcement learning, Agent Lightning aims to help create AI systems that learn from experience and improve over time.