Today, we are excited to announce that with our latest Turing universal language representation model (T-ULRv5), a Microsoft-created model is once again the state of the art and at the top of the Google XTREME public leaderboard (opens in new tab). Resulting from a collaboration between the Microsoft Turing team (opens in new tab) and Microsoft Research, the 2.2 billion-parameter T-ULRv5 XL outperforms the current 2nd best model by an average score of 1.7 points. It is also the state of the art across each of the four subcategories of tasks on the leaderboard. These results demonstrate the strong capabilities of T-ULRv5, which, in addition to being more capable, trains 100 times faster than its predecessors.
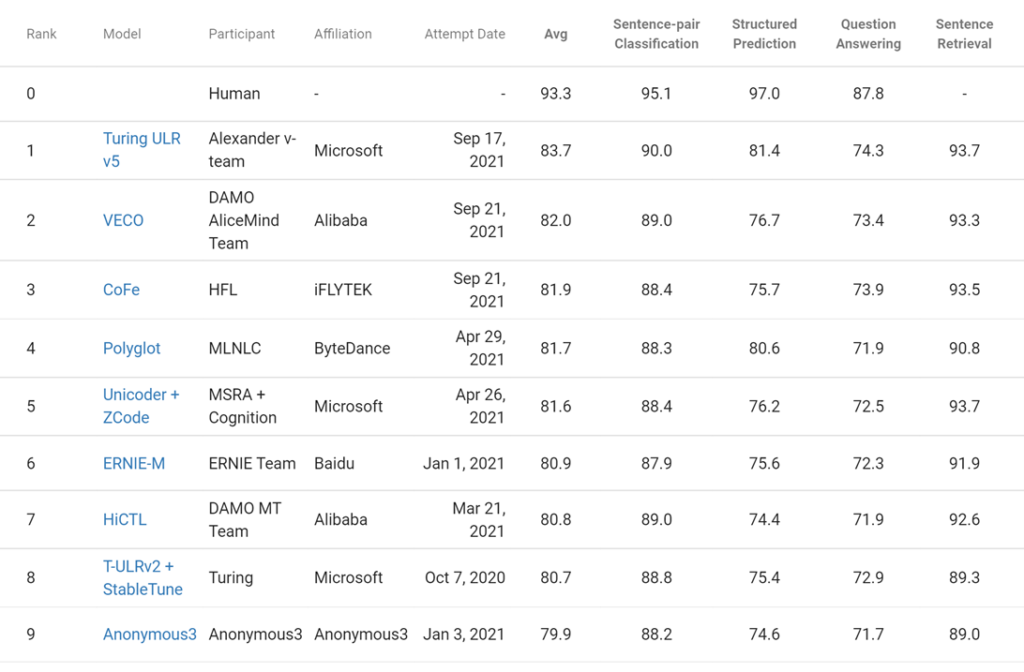
This marks a return to the top of this leaderboard for Microsoft. We have previously held the top position with Turing ULRv2 and other submissions. To reach this latest achievement, we scaled up our recent research on XLM-E (opens in new tab) into the 2.2 billion XL model and coupled it with breakthroughs across data, architecture, and optimization strategies to produce the final pretrained model. We also deployed our advanced fine-tuning technique, called XTune.
XTREME benchmark
The Cross-lingual TRansfer Evaluation of Multilingual Encoders (XTREME (opens in new tab)) benchmark covers 40 typologically diverse languages that span 12 language families and includes nine tasks that require reasoning about different levels of syntax or semantics. The languages in XTREME are selected to maximize language diversity, coverage in existing tasks, and availability of training data.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
The tasks included in XTREME cover a range of paradigms, including sentence text classification, structured prediction, sentence retrieval, and cross-lingual question answering. Consequently, for models to be successful on the XTREME benchmarks, they must learn representations that generalize to many standard cross-lingual transfer settings.
For a full description of the benchmark, languages, and tasks, please see the paper, “XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization (opens in new tab).”
T-ULRv5: An advancement across multiple AI axes
T-ULRv5 is the latest addition to the family of Turing models, which represent a foundational part of Microsoft AI at Scale (opens in new tab). This cross-lingual model incorporates our recent research on XLM-E and is capable of encoding text from 94 languages and representing them in a shared vector space. In the realm of big neural network models, the research frontier has many axes of exploration. The most common axis is the model size, where larger models tend to perform better than their smaller counterparts.
However, increasing model size without innovations along other axes—like better vocabulary, higher quality data, novel training tasks and objectives, innovative network architecture, and training optimizations—usually results in highly inefficient use of expensive compute for a marginally better model. We have introduced and incorporated breakthrough innovations across all these axes to make T-ULRv5 a high-quality, highly efficient model.
Besides its size, T-ULRv5 introduces some key differences and innovations that set it apart from other pretrained multilingual language models and lead to state-of-the-art model performance and greatly improve training efficiency.
Model architecture, pretraining, and tasks
T-ULRv5 shares a similar transformer architecture that’s popular among the emerging foundation models (opens in new tab) and multilingual models like mBERT, mT5, XLM-R, and the previous version, T-ULRv2. Specifically, T-ULRv5 XL, the largest variant we pretrained, has 48 transformer layers, a hidden dimension size of 1,536, 24 attention heads, a 500,000-token multilingual vocabulary size, and a total parameter count of 2.2 billion.
The technology behind T-ULRv5, XLM-E, takes inspiration from ELECTRA (opens in new tab) and is a departure from the previously described InfoXLM. It moves away from InfoXLM’s MMLM (Multilingual Masked Language Modeling) and TLM (Translation Language Modeling) pretraining tasks and adopts two new tasks—MRTD (Multilingual Replaced Token Detection) and TRTD (Translation Replaced Token Detection)—with the goal of distinguishing real input tokens from corrupted tokens.
 pretraining task")
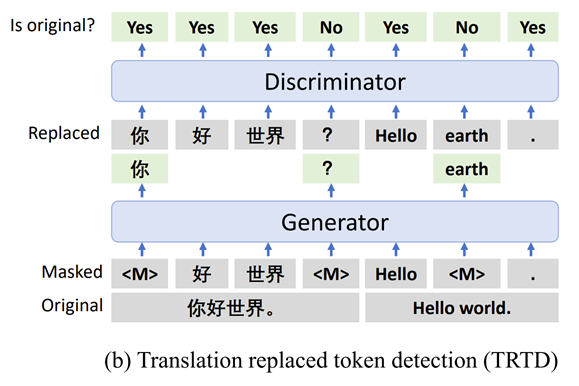
Like ELECTRA, T-ULRv5 training involves two transformer encoders, serving as generator and discriminator, respectively. Unlike ELECTRA, which was trained on only English datasets, T-ULRv5 was trained on large-scale multilingual datasets, including parallel text corpora. We encourage the model to better learn cross-lingual alignment and shared representation by making the generator predict the masked tokens on translation pairs in addition to mono-lingual input. After the pretraining is complete, only the discriminator is used as the text encoder to fine-tune downstream tasks.
100x better training efficiency
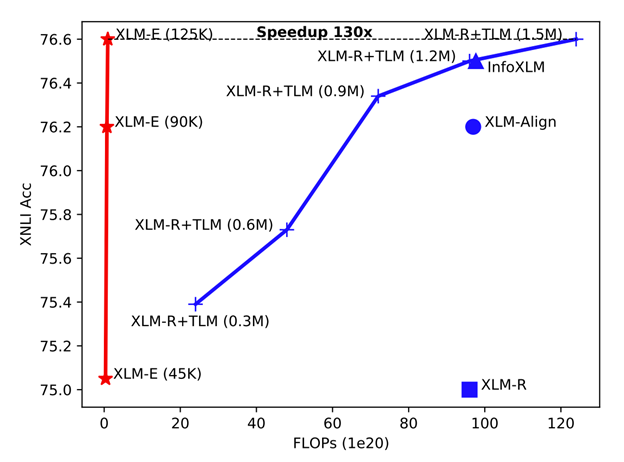
Existing approaches for cross-lingual pretraining based on Masked Language Modeling (MLM) usually require massive computation resources, rendering such models quite expensive. In contrast, XLM-E trains significantly faster and it outperforms the baseline models on various cross-lingual understanding tasks with much less computation cost. For example, with the same corpora, code base, and model size (12 layer), we compared XLM-E (indicated with a red line in Figure 4) with an in-house version of Facebook’s popular multilingual XLM-R (opens in new tab) model augmented with translation language modeling (XLM-R + TLM, indicated with a blue line in Figure 4).
We observed 130x training speedup from XLM-E to achieve the same XNLI accuracy, with the 12-layer base XLM-E model completing its training in only 1.7 days on 64 NVIDIA A100 GPUs. At 2.2 billion parameters, the top-performing T-ULRv5 XL model benefitted from the much-improved training efficiency of XLM-E and finished its training in less than two weeks on 256 NVIDIA A100 GPUs. The combination of introducing new TRTD tasks along with RTD tasks and changes in network architecture accelerated the convergence and quality of the model.
Multilingual training data
Part of the T-ULRv5 quality improvement comes from better training data and a bigger vocabulary. Training a 2.2 billion parameter model supporting 94 languages requires datasets in greater quantity and with high quality. Multilingual corpora, many from the web, usually have a large representation disparity between high-resource and low-resource languages, particularly on data volume, cleanness, and diversity.
In addition, parallel language corpora that consist of translated text pairs can also suffer from mixed translation quality and alignment issues, negatively affecting the resulting model performance. We put significant effort into data engineering and cleaning steps to produce high-quality datasets at scale to support T-ULRv5 training.
Expanded vocabulary
Along with the dataset updates, we also constructed a new vocabulary with 500,000 tokens, two times larger than that of T-ULRv2, which further improved model performance on all languages. Increasing vocabulary size and retraining with a fair representation of all languages is not a trivial task. We describe our method and results on the vocabulary expansion work in this recent research paper.
T-ULRv5: Release information
The Turing team strongly believes in bringing the best of our AI technology into the hands of Microsoft customers as soon as possible. T-ULRv5 will soon deliver benefits to many of our existing product scenarios across products such as Microsoft Bing, Microsoft 365, Microsoft Edge, Microsoft Azure, and more. At Microsoft, our mission is to empower every person and every organization on the planet to achieve more—regardless of where they live and what languages they speak. Thanks to the universal capabilities of T-ULRv5, we hope to one day make these benefits available to our customers.
Microsoft Turing models are also available for custom application building through our private preview program. If you are interested in learning more about this and other Turing models, please complete the early access request form (opens in new tab). We work closely with Azure Cognitive Services to power current and future language services with Turing models. Therefore, existing Azure Cognitive Services customers will start to see these benefits as they become available.
If you are a researcher who would like to work with us in assessing and improving Turing models, Microsoft Turing Academic Program (MS-TAP) allows you to submit a proposal and get access to these models in greater detail.
Building and democratizing more inclusive AI
We are exploring multilingual technology to help democratize AI by addressing barriers, such as the lack of training data, the high cost of language modeling, and the complexity of multilingual systems. T-ULRv5 is an important milestone in this endeavor, as its cross-lingual transferability and zero-shot application paradigm provide a much more efficient and scalable framework for developing cross-lingual systems.
We are motivated by the opportunity to further advance the state of the art and develop new multilingual capabilities to build more inclusive AI. For example, we are excited about exploring neural machine translation (NMT) and language generation with a cross-lingual encoder, as you can read in this research paper (opens in new tab). We hope that our work will contribute to the community’s progress towards making AI more inclusive and accessible to all.
The Microsoft Turing team welcomes your feedback and comments and looks forward to sharing more developments in the future.