

 We periodically update our stories, but we can’t verify that they represent the full picture of our current situation at Microsoft. We leave them on the site so you can see what our thinking and experience was at the time.
We periodically update our stories, but we can’t verify that they represent the full picture of our current situation at Microsoft. We leave them on the site so you can see what our thinking and experience was at the time.
Responding to site outages at Microsoft used to be very challenging.
Large organizations have a lot of moving parts, and when internal sites experience outages and connectivity problems, those moving parts can grind to a halt.
Getting things up and running again is priority one.
In the past, responding to site outages at Microsoft required immense manual effort from the Experience and Reliability Engineering (ERE) team, which manages the company’s global wide-area networks (WANs). But by working with Microsoft Digital Employee Experience’s AI Operations team, the company has developed a powerful new system for arriving at the root cause of an outage and remedying the issue before it results in serious downtime, disruption, or in worst-case scenarios, lost revenue.
A race to the root cause
Site outages occur when buildings lose connectivity and become isolated from the network, essentially cutting workers off from the WAN connection they need to do their jobs. They can arise from any number of issues. An outage might result from a network failure on the part of internet service providers, or there could be a localized power failure. In some cases, a simple physical disruption like a misplaced cable or an incorrectly flipped switch could knock out a network.
Depending on the site and the size of the outage in question, there’s a potential loss of productivity for hundreds or thousands of people. There are other threats in terms of security, and if we’ve got deadlines to meet from a product standpoint, we could potentially miss those dates. So, these kinds of outages tend to be very critical.
—Anand Meduri, project management lead, AI Operations team
When a site goes down, the resulting cascade of connectivity issues and communication failures trigger a flood of automated incident reports generated by a network monitoring tool called alert sources. Those alerts register as incident tickets for ERE, and it’s the responsibility of the team’s network developers to quickly identify the root cause of the tickets and discover whether the sudden uptick in incidents derives from an overarching site outage. They need to sift through the parent-child relationships of the outage and its resulting incident flood to ensure business continuity and reduce the negative impact.
“Depending on the site and the size of the outage in question, there’s a potential loss of productivity for hundreds or thousands of people,” says Anand Meduri, project management lead on Microsoft’s AI Operations (AIOps) team. “There are other threats in terms of security, and if we’ve got deadlines to meet from a product standpoint, we could potentially miss those dates. So, these kinds of outages tend to be very critical.”
Under the previous manual model, ERE network developers troubleshooting a site outage often didn’t have enough information to discover its root cause since their data came from unstructured logs, performance metrics, and alerts. They spent significant time validating the flood of tickets they received, searching for the single ticket corresponding to the parent outage. Once they determined the source, they would attempt to remedy the issue themselves. If it required a more intensive fix, they would turn the incident over to the Escalation Management team or a high-level Direct Response Individual (DRI) for remediation.
We looked into all of the narrow device signals and system logs, as well as the metrics and health measures we can gather from them, and we found some good signals that we could use. And we also found a pattern: when those signals are acting slightly differently from normal behavior, it should be related to a site outage.
—Eunsil Baik, data scientist, Microsoft Digital Employee Experience
ERE has a 15-minute target time for determining the root cause of any major outage. They have 30 minutes to engage the proper team and effect a repair—a demanding timeline considering the sheer number of alerts deriving from any parent outage. With around 15,000 tickets a month, each needing validation from an ERE member, their attention was spread extremely thin. As a result, network developers were spending more time validating downstream tickets than resolving the underlying issue, slowing a key metric for their team: mean time to resolve (MTTR).
The solution was to automate root-cause analysis with machine learning and AI.
Designing a solution from the data up
ERE partnered with Microsoft Digital Employee Experience’s AIOps team to develop an outage detection system based on machine learning and AI. They began by building out the data set from scratch, setting the standards for collecting and categorizing outage information. The core principle is simple: Any major site outage will reliably lead to a series of system alerts and tickets arising from downstream breakages. With enough training, machine learning should be able to correlate those signals and identify the root cause.
Data scientists and engineers collected and categorized the relevant data points. They identified alerts, device and system logs, and performance logs as signal sources since those would capture the wealth of data emerging from any cascading outage.
“We looked into all of the narrow device signals and system logs, as well as the metrics and health measures we can gather from them, and we found some good signals that we could use,” says Eunsil Baik, a data scientist in Microsoft Digital Employee Experience. “And we also found a pattern: when those signals are acting slightly differently from normal behavior, it should be related to a site outage.”
The device signals and system logs that indicate outages came from three main sources:
- SMARTS: The tool for monitoring networked devices like routers, switches, and CPU processors, which generates alerts when it observes faults.
- Splunk: A collection of real-time logs related to power events, systems, audits, activities, and configuration changes.
- SevOne Performance: A monitor of different performance metrics, including availability, inflow, outflow, jitter, and connectivity from network devices polled at regular intervals.
Assembling and managing the information that these monitoring tools can provide required a variety of tools throughout the Microsoft Azure Data Stack:
- Azure Data Lake: Storing data for ingestion from different sources and storing gold data
- Event Hub: Streaming data ingestion
- Stream Analytics: Filtering data
- Blog Storage: Housing data
- Data Factory: Scheduling data processing and model training
- Azure Key Vault: Storing sensitive authentication data
- Azure Data Bricks: Developing notebooks for data processing and wrangling, conducting experiments, and building models
- Azure Monitor: Overseeing resource health
- Azure DevOps: Automating deployments and delivery
- Azure Web App: Deploying model as an endpoint
- Azure Functions: Processing data, combining signals, and creating single data points while doing real-time detection
Making the model work
Outage classification is fundamentally a binary problem, so the team designed the system to create an incident based on an alert received from its source. The signals related to that alert route to the machine learning service as an input and yield up a binary “yes” or “no” classification.
To establish that binary classification, they focused the machine learning model on determining whether an alert is a site-outage or non-site-outage through the three independent signal sources: SMARTS, Splunk, and SevOne.
By codifying the three signals associated with fault monitoring, real-time logs, and performance metrics into patterns, the team established the variables for training the AI to detect outages. In effect, the process transformed the manual actions that engineers would undertake during their search for an outage into static business rules. Those rules made up the labeled data set they used to train the machine learning model.
The AIOps team selected the XGBoost Classifier machine learning model to work on the data. From there, they had to wait a month for the model to accumulate enough data to begin developing a high-quality machine learning model.
The next step was evaluating and validating the model. When searching for site outages, the system could predict one of four results: a false negative, a false positive, a true negative, or a true positive. By assembling those results into a confusion matrix, it would be able to quantify the degree of accuracy. Finally, the team determined accuracy by generating a ratio of correct predictions—true positive or true negative—against all predictions made by the algorithm.
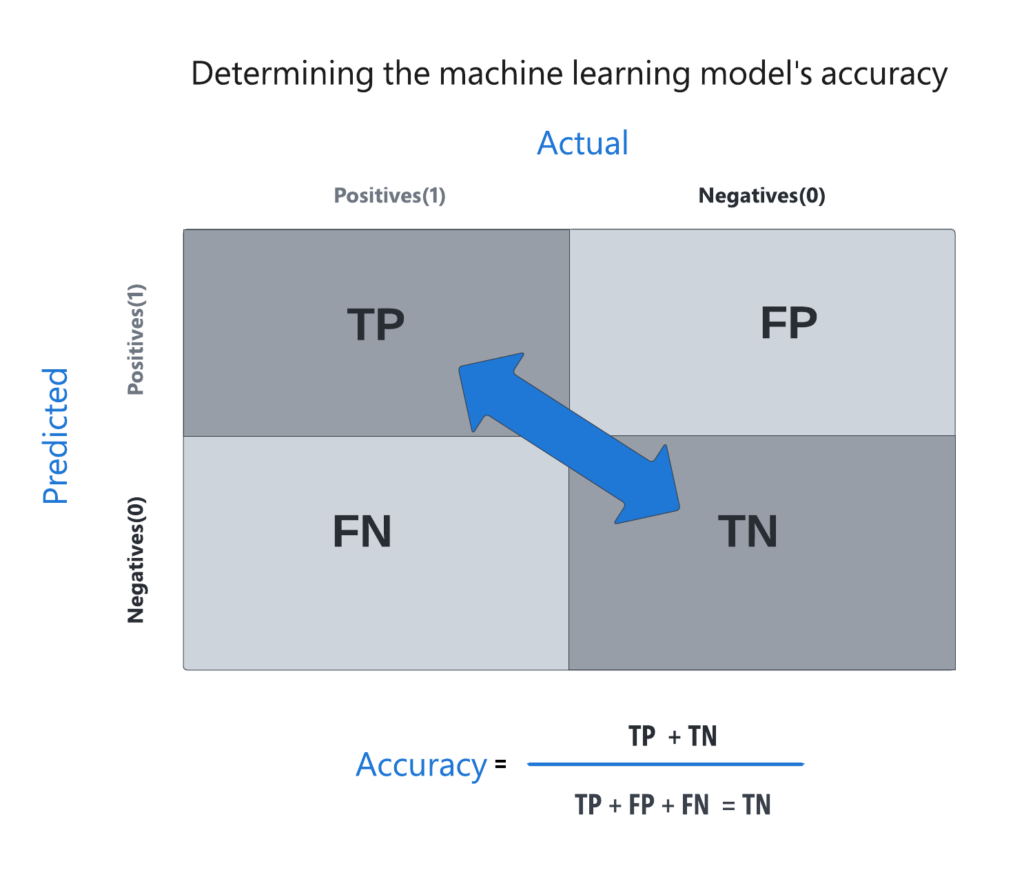
In its training environment, the team found that the model accurately identified a site outage 92 percent of the time, a level of accuracy on par with lab environments. The system has now been trained rigorously and deployed in a live environment for six months, and it successfully predicts 49 percent of real-world outages. As the algorithm trains over time, that number continues to improve.
The outcomes of automation
By successfully identifying around half of all site outages, the machine learning model eliminates an immense amount of manual labor associated with sifting through cascading alerts and tickets. Instead, ERE can go straight to the parent issue—the primary site outage—and quickly repair it themselves or pass it along to Escalation Management or DRIs.
When the system correctly traces a flood of alerts to a single site outage, identifying and repairing that outage clears 99 percent of the tickets associated with the disruption. As a result, ticket clearance has increased in both quantity and speed. In an organization where revenue and reputation are on the line, speed is central to outage response, and the machine learning model has drastically accelerated ERE’s response to incidents.
If I’m spending my energy on fixing access point issues or downed switch issues, those are less critical, and they can wait. But site outages are super critical, and we want to detect them as soon as possible so we can fix them right away. This AIOps solution accomplishes that.
—Laxman Rao Bhinnale, problem manager, Experience and Reliability Engineering
15,000 tickets per month work out to around 500 tickets per day, and on average, an ERE member would take about one minute to validate each incident. With machine learning eliminating the need to validate almost all those tickets and pointing directly to the parent site outage, the average number of tickets requiring validation is down from 15,000 to typically under 50, saving around 240 hours of work in an average month.
In addition, the machine learning site outage detection system saves an average of 10 minutes during the process of identifying and triaging an outage. That time savings represents a substantial portion of ERE’s 15-minute target for determining an outage and their 30-minute target to engage the proper team for a repair.
The success we’ve achieved has taken us from manual to automated, and we’ve built this solution for just one use case. This collaboration will definitely drive the data-driven discussion and expand its scope to other scenarios.
—Satish Aradhya, senior service engineering manager, Experience and Reliability Engineering
Ultimately, the system’s value comes from eliminating the need for human intervention and the possibility of error, freeing ERE’s network developers to focus on the most critical aspect of their work: repairing outages and resolving complex tickets.
“If I’m spending my energy on fixing access point issues or downed switch issues, those are less critical, and they can wait,” says Laxman Rao Bhinnale, problem manager for ERE. “But site outages are super critical, and we want to detect them as soon as possible so we can fix them right away. This AIOps solution accomplishes that.”
Extending the applications of automation
Now that AI and machine learning are supporting outage detection, potential applications for the system are on the horizon.
“The success we’ve achieved has taken us from manual to automated, and we’ve built this solution for just one use case,” says Satish Aradhya, senior service engineering manager for ERE. “This collaboration will definitely drive the data-driven discussion and expand its scope to other scenarios.”
A system like this could be useful for any number of infrastructure challenges. Teams might use a similar model to correlate other scenarios or even work toward self-healing solutions that eliminate the need for human intervention in outages at all.
“Our vision is very ambitious,” Bhinnale says. “We have a lot of things in the pipeline, and this is just the beginning.”

- Stay laser-focused on customer outcomes to help guide your process.
- Choose the right data sources and patterns to mimic what a human would do.
- Engage with stakeholders to reduce churn through frequent course corrections.
- Be aware that in large systems, you won’t have complete data.
- Leverage subject-matter experts across teams to get input from diverse engineers on the ground.
- Start thinking about the applications from the outset and infuse those techniques early on.
- Recognize that you’re creating a data-driven solution and start with the “why.”

See how Azure Anomaly Detector is helping Microsoft examine SAP transactions.
Learn how Microsoft applied Azure Cognitive Services to automate partner claim validation.
