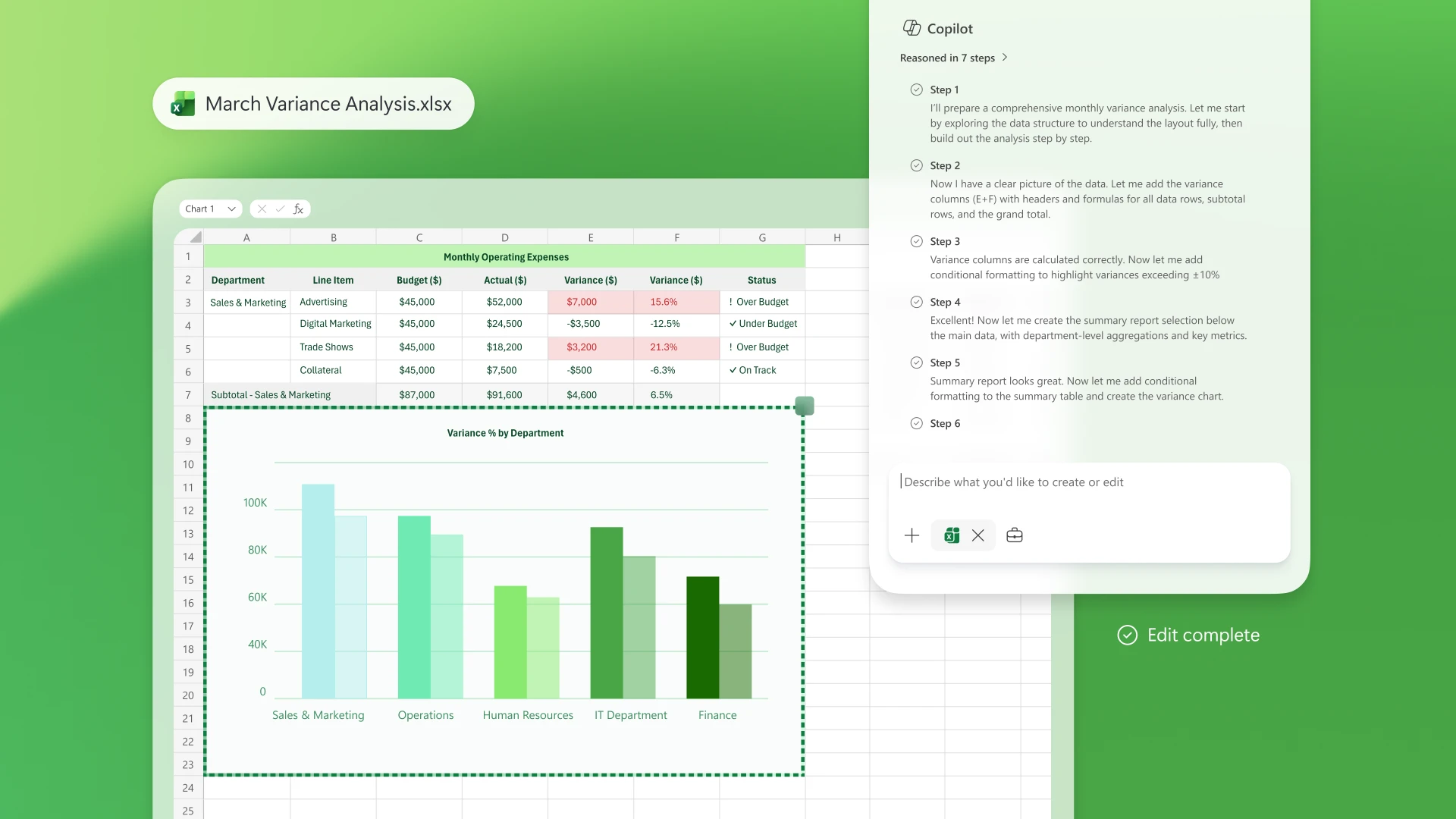
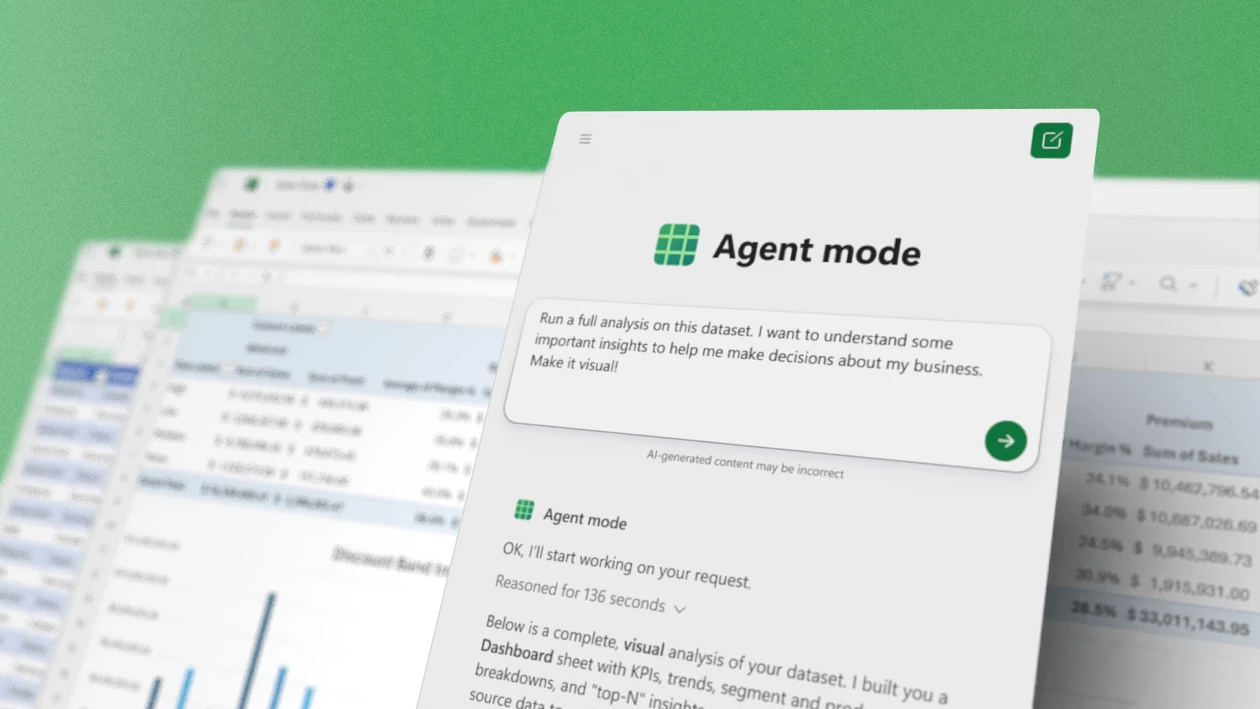
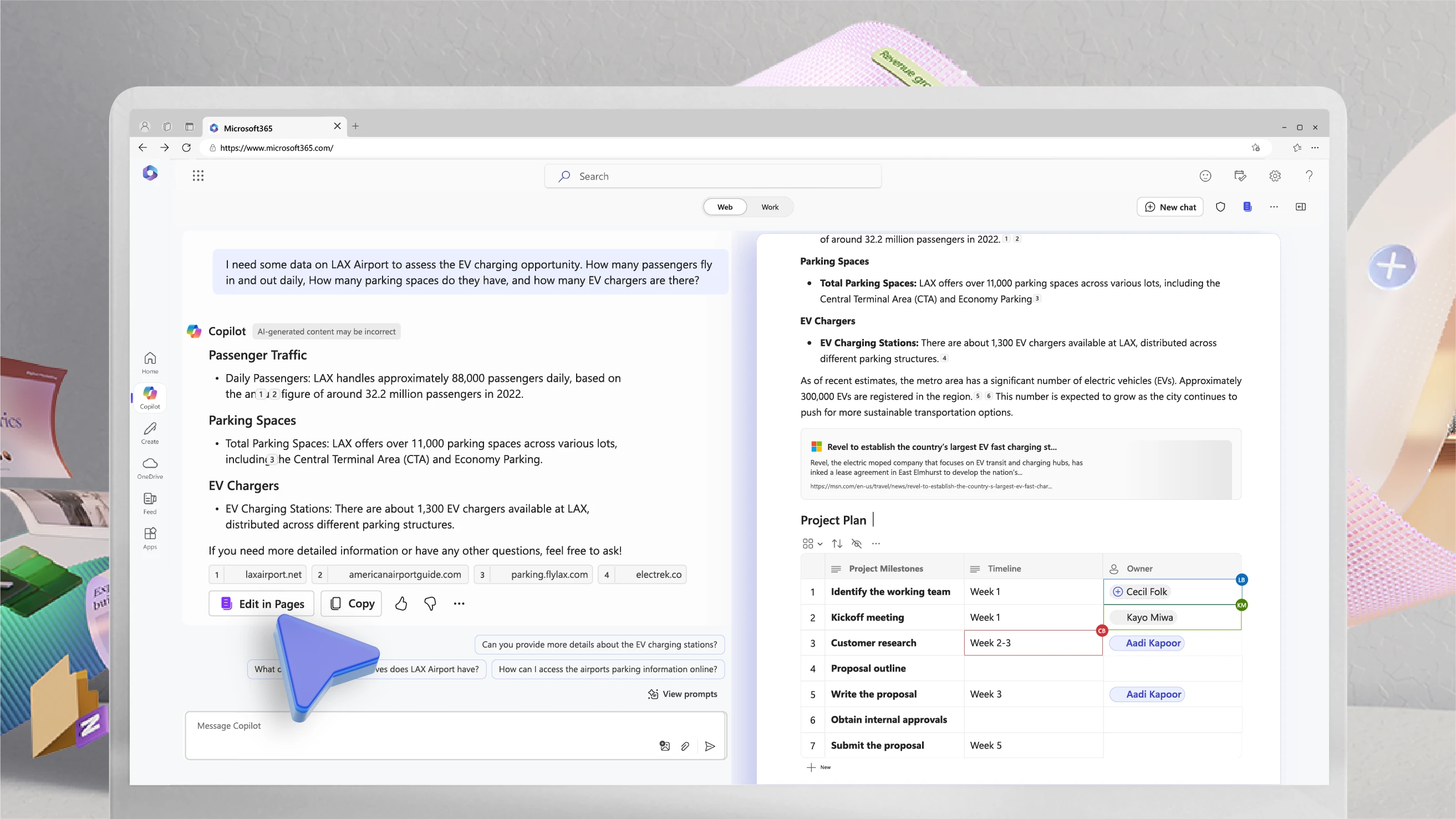
Copilot in Excel: Built for the era of Frontier Finance
Plenty of AI tools claim to be built for finance; Microsoft 365 Copilot in Excel is proving it in practice.
 Microsoft 365
Microsoft 365
Transform data into insightful spreadsheets to help you analyze trends and visualize information.