At a glance
- Today’s AI agents store long interaction histories but struggle to reuse them effectively.
- Raw memory retrieval can overwhelm agents with lengthy, low-value context.
- PlugMem transforms interaction history into structured, reusable knowledge.
- A single, general-purpose memory module improves performance across diverse agent benchmarks while using fewer memory tokens.
It seems counterintuitive: giving AI agents more memory can make them less effective. As interaction logs accumulate, they grow large, fill with irrelevant content, and become increasingly difficult to use.
More memory means that agents must search through larger volumes of past interactions to find information relevant to the current task. Without structure, these records mix useful experiences with irrelevant details, making retrieval slower and less reliable. The challenge is not storing more experiences, but organizing them so that agents can quickly identify what matters in the moment.
In our recent paper “PlugMem: A Task-Agnostic Plugin Memory Module for LLM Agents,” we introduce a plug-and-play memory system that transforms raw agent interactions into reusable knowledge. Rather than treating memory as text to retrieve, PlugMem organizes that history into structured knowledge designed to support decisions as the agent acts.
PODCAST SERIES

The AI Revolution in Medicine, Revisited
Join Microsoft’s Peter Lee on a journey to discover how AI is impacting healthcare and what it means for the future of medicine.
Cognitive science offers a useful framework here. It distinguishes between remembering events, knowing facts, and knowing how to perform tasks. Past events provide context, but effective decisions rely on the facts and skills extracted from those events.
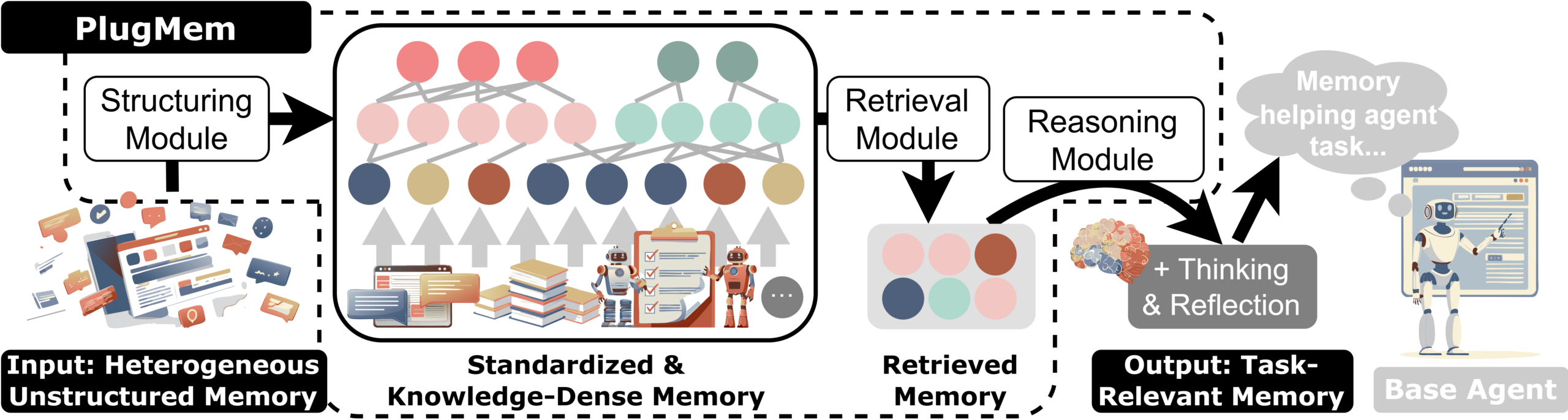
This distinction motivated a shift in how we decided to design memory for AI agents. PlugMem implements this shift by converting the agent’s interaction history, such as dialogues, documents, and web sessions, into structured, compact knowledge units that can be reused across tasks.
How PlugMem works
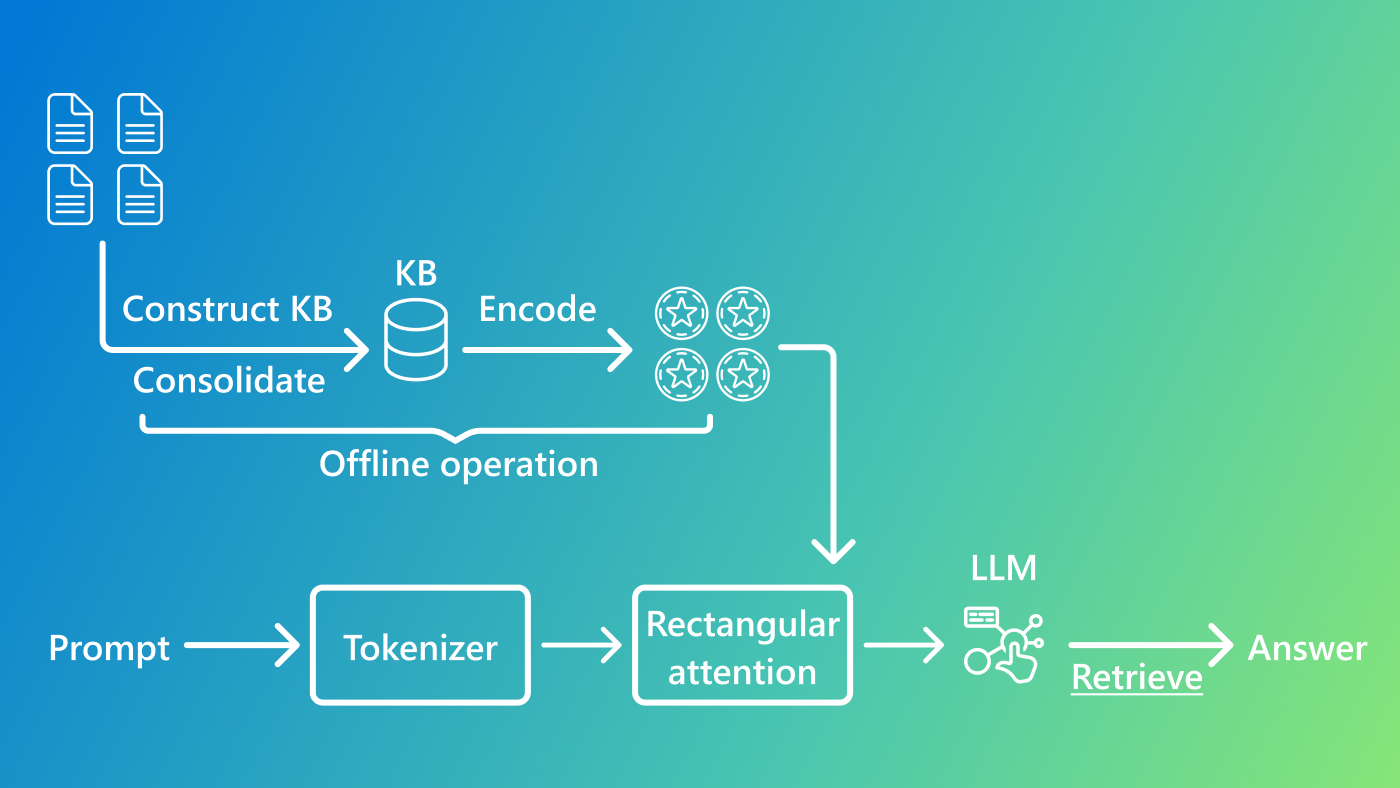
A key difference between PlugMem and conventional AI memory systems is what gets stored. Traditional approaches store text chunks or named entities (references to people, places, and concepts). PlugMem uses facts and reusable skills as the fundamental building blocks of memory. This design reduces redundancy, increases information density, and improves retrieval precision. It’s built around three core components:
Structure. Raw interactions are standardized and transformed into propositional knowledge (facts) and prescriptive knowledge (reusable skills). These knowledge units are organized into a structured memory graph, enabling knowledge to be stored in a form designed for reuse.
Retrieval. Rather than retrieving long passages of text, PlugMem retrieves knowledge units that are aligned with the current task. High-level concepts and inferred intents serve as routing signals, surfacing the most relevant information for the decision at hand.
Reasoning. Retrieved knowledge is distilled into concise, task-ready guidance before being passed to the base agent, ensuring that only decision-relevant knowledge enters the agent’s context window.
Figure 1 illustrates how these components work together.
One memory, any task
Most AI memory systems are built for one job. A conversational memory module is designed around dialogue. A knowledge-retrieval system is tuned to look up facts. A web agent’s memory is optimized for navigating pages. Each performs well in its target setting but rarely transfers without significant redesign.
PlugMem takes a different approach. It is a foundational memory layer that can be attached to any AI agent without needing to modify it for a specific task.
Evaluating PlugMem
To test PlugMem, we evaluated the same memory module on three benchmarks that each make different demands on memory:
- Answering questions across long multi-turn conversations
- Finding facts that span multiple Wikipedia articles
- Making decisions while browsing the web
Across all three, PlugMem consistently outperformed both generic retrieval methods and task-specific memory designs while allowing the AI agent to use significantly less memory token budget in the process.
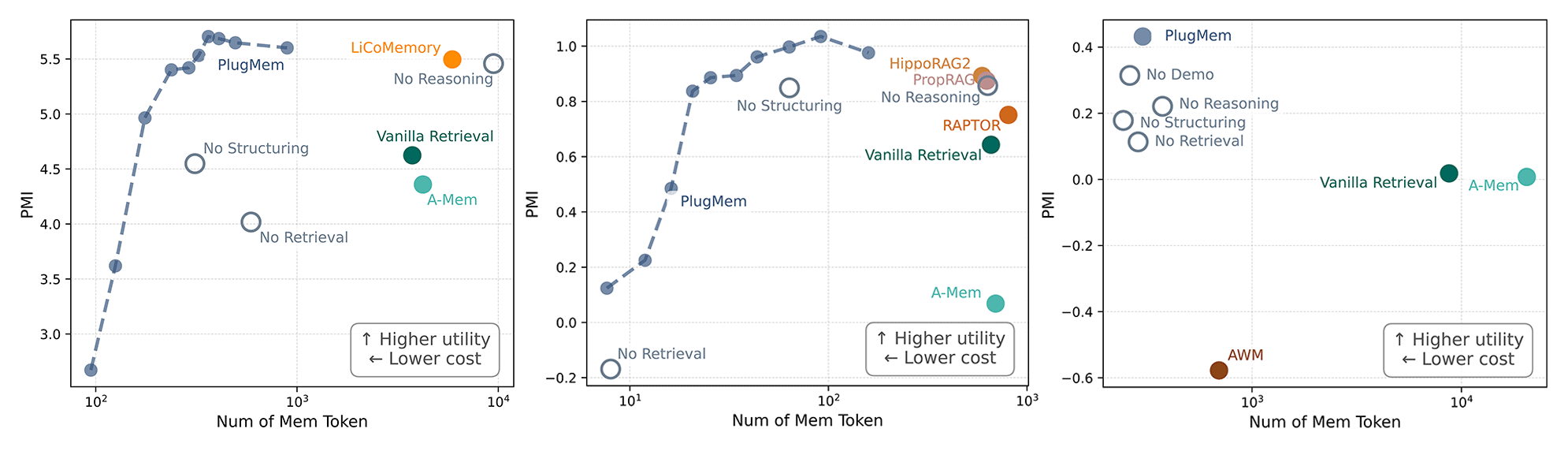
Measuring memory by utility, not size
We wanted to evaluate whether the right information was reaching the agent at the right moment, without overwhelming the model’s context window, which has limited capacity. To do this, we introduced a metric that measures how much useful, decision-relevant information a memory module contributes relative to how much context it consumes.
When we plotted utility against context consumption, PlugMem consistently came out ahead: it delivered more decision-relevant information while consuming less of the AI agent’s context than other approaches, as shown in Figure 2. These results suggest that transforming experience into knowledge—rather than storing and retrieving raw logs—produces memory that is more useful and efficient.
Why general-purpose memory can outperform task-specific designs
General-purpose memory modules can outperform systems tailored to specific tasks because the decisive factor is not specialization but whether memory can surface the right knowledge precisely when the agent needs it. Structure, retrieval, and reasoning each play a distinct role, and getting all three right matters more than optimizing for a single use case.
PlugMem is not meant to replace task-specific approaches. It provides a general memory foundation upon which task adaptations can be layered. Our experiments show that combining PlugMem with task-specific techniques yields further gains.
Toward reusable memory for agents
As AI agents take on longer and more complex tasks, its memory needs to evolve from storing past interactions to actively supplying reusable knowledge. The goal is for agents to carry useful facts and strategies from one task to the next rather than starting from scratch each time.
PlugMem represents a step in that direction, grounding memory design in cognitive principles and treating knowledge as the primary unit of reuse. As agent capabilities expand, knowledge-centric memory may prove to be a critical building block for the next generation of intelligent agents.
Code and experimental results are publicly available on GitHub (opens in new tab) so that others can reproduce the results and conduct their own research.