



To stay ahead of adversaries, who show no restraint in adopting tools and techniques that can help them attain their goals, Microsoft continues to harness AI and machine learning to solve security challenges. One area we’ve been experimenting on is autonomous systems. In a simulated enterprise network, we examine how autonomous agents, which are intelligent systems that independently carry out a set of operations using certain knowledge or parameters, interact within the environment and study how reinforcement learning techniques can be applied to improve security.
Today, we’d like to share some results from these experiments. We are open sourcing the Python source code of a research toolkit we call CyberBattleSim, an experimental research project that investigates how autonomous agents operate in a simulated enterprise environment using high-level abstraction of computer networks and cybersecurity concepts. The toolkit uses the Python-based OpenAI Gym interface to allow training of automated agents using reinforcement learning algorithms. The code is available here: https://github.com/microsoft/CyberBattleSim
CyberBattleSim provides a way to build a highly abstract simulation of complexity of computer systems, making it possible to frame cybersecurity challenges in the context of reinforcement learning. By sharing this research toolkit broadly, we encourage the community to build on our work and investigate how cyber-agents interact and evolve in simulated environments, and research how high-level abstractions of cyber security concepts help us understand how cyber-agents would behave in actual enterprise networks.
This research is part of efforts across Microsoft to leverage machine learning and AI to continuously improve security and automate more work for defenders. A recent study commissioned by Microsoft found that almost three-quarters of organizations say their teams spend too much time on tasks that should be automated. We hope this toolkit inspires more research to explore how autonomous systems and reinforcement learning can be harnessed to build resilient real-world threat detection technologies and robust cyber-defense strategies.
Applying reinforcement learning to security
Reinforcement learning is a type of machine learning with which autonomous agents learn how to conduct decision-making by interacting with their environment. Agents may execute actions to interact with their environment, and their goal is to optimize some notion of reward. One popular and successful application is found in video games where an environment is readily available: the computer program implementing the game. The player of the game is the agent, the commands it takes are the actions, and the ultimate reward is winning the game. The best reinforcement learning algorithms can learn effective strategies through repeated experience by gradually learning what actions to take in each state of the environment. The more the agents play the game, the smarter they get at it. Recent advances in the field of reinforcement learning have shown we can successfully train autonomous agents that exceed human levels at playing video games.
Last year, we started exploring applications of reinforcement learning to software security. To do this, we thought of software security problems in the context of reinforcement learning: an attacker or a defender can be viewed as agents evolving in an environment that is provided by the computer network. Their actions are the available network and computer commands. The attacker’s goal is usually to steal confidential information from the network. The defender’s goal is to evict the attackers or mitigate their actions on the system by executing other kinds of operations.

Figure 1. Mapping reinforcement learning concepts to security
In this project, we used OpenAI Gym, a popular toolkit that provides interactive environments for reinforcement learning researchers to develop, train, and evaluate new algorithms for training autonomous agents. Notable examples of environments built using this toolkit include video games, robotics simulators, and control systems.
Computer and network systems, of course, are significantly more complex than video games. While a video game typically has a handful of permitted actions at a time, there is a vast array of actions available when interacting with a computer and network system. For instance, the state of the network system can be gigantic and not readily and reliably retrievable, as opposed to the finite list of positions on a board game. Even with these challenges, however, OpenAI Gym provided a good framework for our research, leading to the development of CyberBattleSim.
How CyberBattleSim works
CyberBattleSim focuses on threat modeling the post-breach lateral movement stage of a cyberattack. The environment consists of a network of computer nodes. It is parameterized by a fixed network topology and a set of predefined vulnerabilities that an agent can exploit to laterally move through the network. The simulated attacker’s goal is to take ownership of some portion of the network by exploiting these planted vulnerabilities. While the simulated attacker moves through the network, a defender agent watches the network activity to detect the presence of the attacker and contain the attack.
To illustrate, the graph below depicts a toy example of a network with machines running various operating systems and software. Each machine has a set of properties, a value, and pre-assigned vulnerabilities. Black edges represent traffic running between nodes and are labelled by the communication protocol.
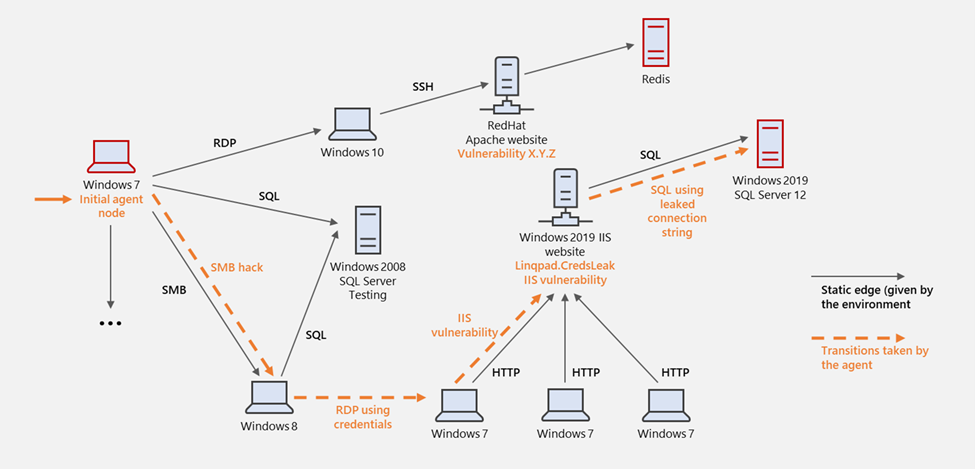
Figure 2. Visual representation of lateral movement in a computer network simulation
Suppose the agent represents the attacker. The post-breach assumption means that one node is initially infected with the attacker’s code (we say that the attacker owns the node). The simulated attacker’s goal is to maximize the cumulative reward by discovering and taking ownership of nodes in the network. The environment is partially observable: the agent does not get to see all the nodes and edges of the network graph in advance. Instead, the attacker takes actions to gradually explore the network from the nodes it currently owns. There are three kinds of actions, offering a mix of exploitation and exploration capabilities to the agent: performing a local attack, performing a remote attack, and connecting to other nodes. Actions are parameterized by the source node where the underlying operation should take place, and they are only permitted on nodes owned by the agent. The reward is a float that represents the intrinsic value of a node (e.g., a SQL server has greater value than a test machine).
In the depicted example, the simulated attacker breaches the network from a simulated Windows 7 node (on the left side, pointed to by an orange arrow). It proceeds with lateral movement to a Windows 8 node by exploiting a vulnerability in the SMB file-sharing protocol, then uses some cached credential to sign into another Windows 7 machine. It then exploits an IIS remote vulnerability to own the IIS server, and finally uses leaked connection strings to get to the SQL DB.
This environment simulates a heterogenous computer network supporting multiple platforms and helps to show how using the latest operating systems and keeping these systems up to date enable organizations to take advantage of the latest hardening and protection technologies in platforms like Windows 10. The simulation Gym environment is parameterized by the definition of the network layout, the list of supported vulnerabilities, and the nodes where they are planted. The simulation does not support machine code execution, and thus no security exploit actually takes place in it. We instead model vulnerabilities abstractly with a precondition defining the following: the nodes where the vulnerability is active, a probability of successful exploitation, and a high-level definition of the outcome and side-effects. Nodes have preassigned named properties over which the precondition is expressed as a Boolean formula.
Vulnerability outcomes
There are predefined outcomes that include the following: leaked credentials, leaked references to other computer nodes, leaked node properties, taking ownership of a node, and privilege escalation on the node. Examples of remote vulnerabilities include: a SharePoint site exposing ssh credentials, an ssh vulnerability that grants access to the machine, a GitHub project leaking credentials in commit history, and a SharePoint site with file containing SAS token to storage account. Meanwhile, examples of local vulnerabilities include: extracting authentication token or credentials from a system cache, escalating to SYSTEM privileges, escalating to administrator privileges. Vulnerabilities can either be defined in-place at the node level or can be defined globally and activated by the precondition Boolean expression.
Benchmark: Measuring progress
We provide a basic stochastic defender that detects and mitigates ongoing attacks based on predefined probabilities of success. We implement mitigation by reimaging the infected nodes, a process abstractly modeled as an operation spanning multiple simulation steps. To compare the performance of the agents, we look at two metrics: the number of simulation steps taken to attain their goal and the cumulative rewards over simulation steps across training epochs.
Modeling security problems
The parameterizable nature of the Gym environment allows modeling of various security problems. For instance, the snippet of code below is inspired by a capture the flag challenge where the attacker’s goal is to take ownership of valuable nodes and resources in a network:

Figure 3. Code describing an instance of a simulation environment
We provide a Jupyter notebook to interactively play the attacker in this example:
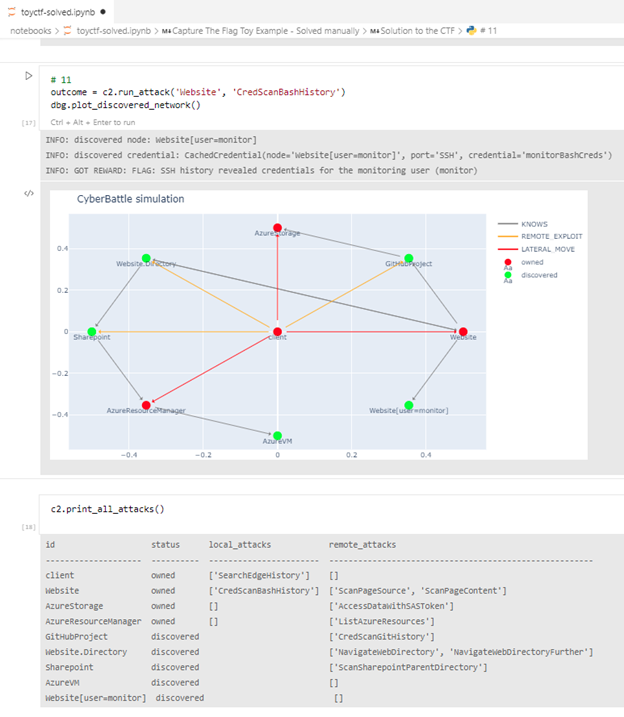
Figure 4. Playing the simulation interactively
With the Gym interface, we can easily instantiate automated agents and observe how they evolve in such environments. The screenshot below shows the outcome of running a random agent on this simulation—that is, an agent that randomly selects which action to perform at each step of the simulation.
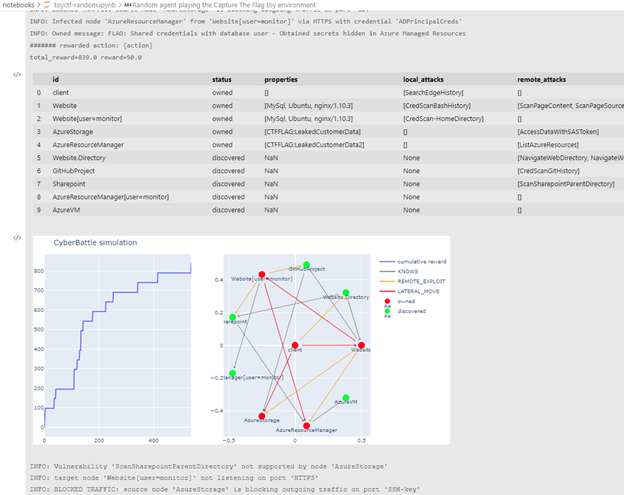
Figure 5. A random agent interacting with the simulation
The above plot in the Jupyter notebook shows how the cumulative reward function grows along the simulation epochs (left) and the explored network graph (right) with infected nodes marked in red. It took about 500 agent steps to reach this state in this run. Logs reveal that many attempted actions failed, some due to traffic being blocked by firewall rules, some because incorrect credentials were used. In the real world, such erratic behavior should quickly trigger alarms and a defensive XDR system like Microsoft 365 Defender and SIEM/SOAR system like Azure Sentinel would swiftly respond and evict the malicious actor.
Such a toy example allows for an optimal strategy for the attacker that takes only about 20 actions to take full ownership of the network. It takes a human player about 50 operations on average to win this game on the first attempt. Because the network is static, after playing it repeatedly, a human can remember the right sequence of rewarding actions and can quickly determine the optimal solution.
For benchmarking purposes, we created a simple toy environment of variable sizes and tried various reinforcement algorithms. The following plot summarizes the results, where the Y-axis is the number of actions taken to take full ownership of the network (lower is better) over multiple repeated episodes (X-axis). Note how certain algorithms such as Q-learning can gradually improve and reach human level, while others are still struggling after 50 episodes!

Figure 6. Number of iterations along epochs for agents trained with various reinforcement learning algorithms
The cumulative reward plot offers another way to compare, where the agent gets rewarded each time it infects a node. Dark lines show the median while the shadows represent one standard deviation. This shows again how certain agents (red, blue, and green) perform distinctively better than others (orange).
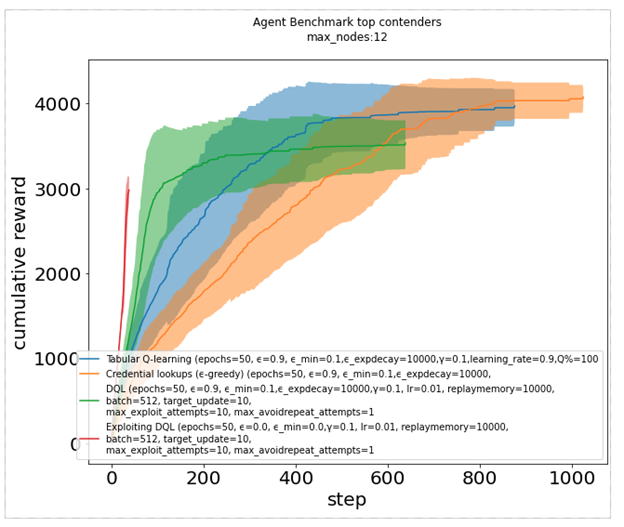
Figure 7. Cumulative reward plot for various reinforcement learning algorithms
Generalizing
Learning how to perform well in a fixed environment is not that useful if the learned strategy does not fare well in other environments—we want the strategy to generalize well. Having a partially observable environment prevents overfitting to some global aspects or dimensions of the network. However, it does not prevent an agent from learning non-generalizable strategies like remembering a fixed sequence of actions to take in order. To better evaluate this, we considered a set of environments of various sizes but with a common network structure. We train an agent in one environment of a certain size and evaluate it on larger or smaller ones. This also gives an idea of how the agent would fare on an environment that is dynamically growing or shrinking while preserving the same structure.
To perform well, agents now must learn from observations that are not specific to the instance they are interacting with. They cannot just remember node indices or any other value related to the network size. They can instead observe temporal features or machine properties. For instance, they can choose the best operation to execute based on which software is present on the machine. The two cumulative reward plots below illustrate how one such agent, previously trained on an instance of size 4 can perform very well on a larger instance of size 10 (left), and reciprocally (right).
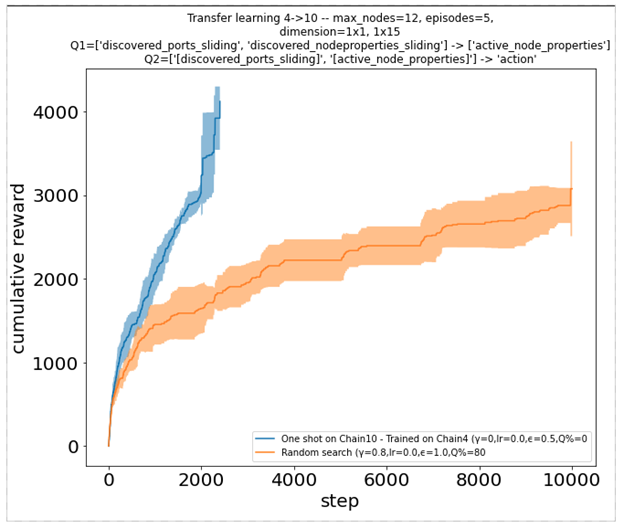
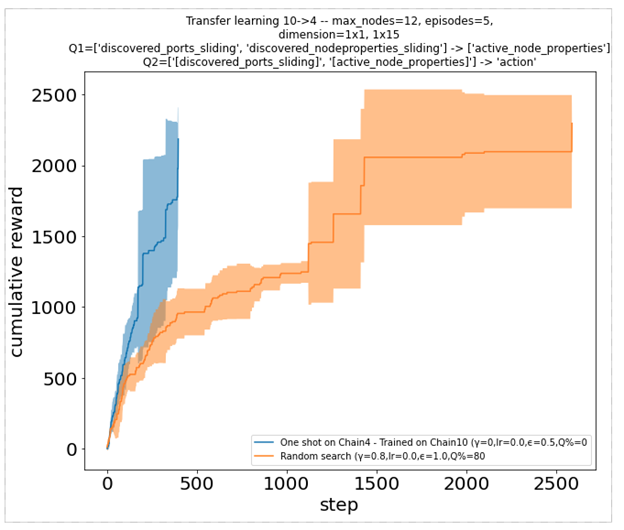
Figure 8. Cumulative reward function for an agent pre-trained on a different environment
An invitation to continue exploring the applications of reinforcement learning to security
When abstracting away some of the complexity of computer systems, it’s possible to formulate cybersecurity problems as instances of a reinforcement learning problem. With the OpenAI toolkit, we could build highly abstract simulations of complex computer systems and easily evaluate state-of-the-art reinforcement algorithms to study how autonomous agents interact with and learn from them.
A potential area for improvement is the realism of the simulation. The simulation in CyberBattleSim is simplistic, which has advantages: Its highly abstract nature prohibits direct application to real-world systems, thus providing a safeguard against potential nefarious use of automated agents trained with it. It also allows us to focus on specific aspects of security we aim to study and quickly experiment with recent machine learning and AI algorithms: we currently focus on lateral movement techniques, with the goal of understanding how network topology and configuration affects these techniques. With such a goal in mind, we felt that modeling actual network traffic was not necessary, but these are significant limitations that future contributions can look to address.
On the algorithmic side, we currently only provide some basic agents as a baseline for comparison. We would be curious to find out how state-of-the art reinforcement learning algorithms compare to them. We found that the large action space intrinsic to any computer system is a particular challenge for reinforcement learning, in contrast to other applications such as video games or robot control. Training agents that can store and retrieve credentials is another challenge faced when applying reinforcement learning techniques where agents typically do not feature internal memory. These are other areas of research where the simulation could be used for benchmarking purposes.
The code we are releasing today can also be turned into an online Kaggle or AICrowd-like competition and used to benchmark performance of latest reinforcement algorithms on parameterizable environments with large action space. Other areas of interest include the responsible and ethical use of autonomous cybersecurity systems. How does one design an enterprise network that gives an intrinsic advantage to defender agents? How does one conduct safe research aimed at defending enterprises against autonomous cyberattacks while preventing nefarious use of such technology?
With CyberBattleSim, we are just scratching the surface of what we believe is a huge potential for applying reinforcement learning to security. We invite researchers and data scientists to build on our experimentation. We’re excited to see this work expand and inspire new and innovative ways to approach security problems.
William Blum
Microsoft 365 Defender Research Team




