



We’re frequently asked how we operate our Security Operations Center (SOC) at Microsoft (particularly as organizations are integrating cloud into their enterprise estate). This is the first in a three part blog series designed to share our approach and experience, so you can use what we learned to improve your SOC.
In Part 1: Organization, we start with the critical organizational aspects (organizational purpose, culture, and metrics). In Part 2: People (Part 2a and 2b), we cover how we manage our most valuable resource—human talent. And finally Part 3: Technology, covers the technology that enables these people to accomplish their mission.
Overall SOC model
Microsoft has multiple security operations teams that each have specialized knowledge to protect the different technical environments at Microsoft. We use a “fusion center” model with a shared operating floor, which we call our Cyber Defense Operations Center (CDOC), to increase collaboration and facilitate rapid communication among these teams. Each team manages to the specific needs of their environment.
In this three part series, we focus on the operation of our corporate IT SOC team as they most closely reflect the challenges and approaches of our customers—having many users and endpoints, email attack vectors, and a hybrid of on-premises and cloud assets. In addition, we include a few lessons learned from the other SOCs and our Detection and Response Team (DART) that helps our customers respond to major incidents.
This SOC operates with three tiers of analysts plus automation as seen in Figure 1 below. (We’ll provide more details in Part 2: People.)
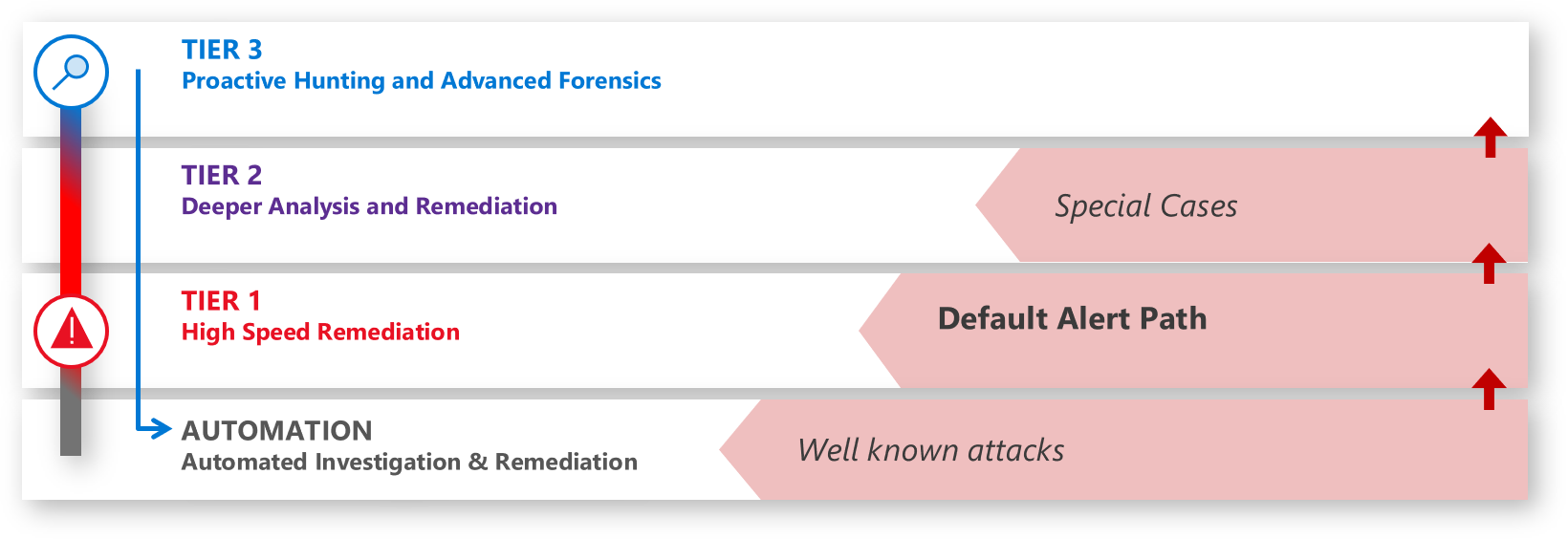
Figure 1. SOC analyst tiers plus automation.
The tooling in the SOC (Figure 2) is a mixture of centralized breadth capabilities and specialized tools to enable high quality alerts and an end-to-end investigation and remediation experience. (Part 3: Technology will provide more details.)
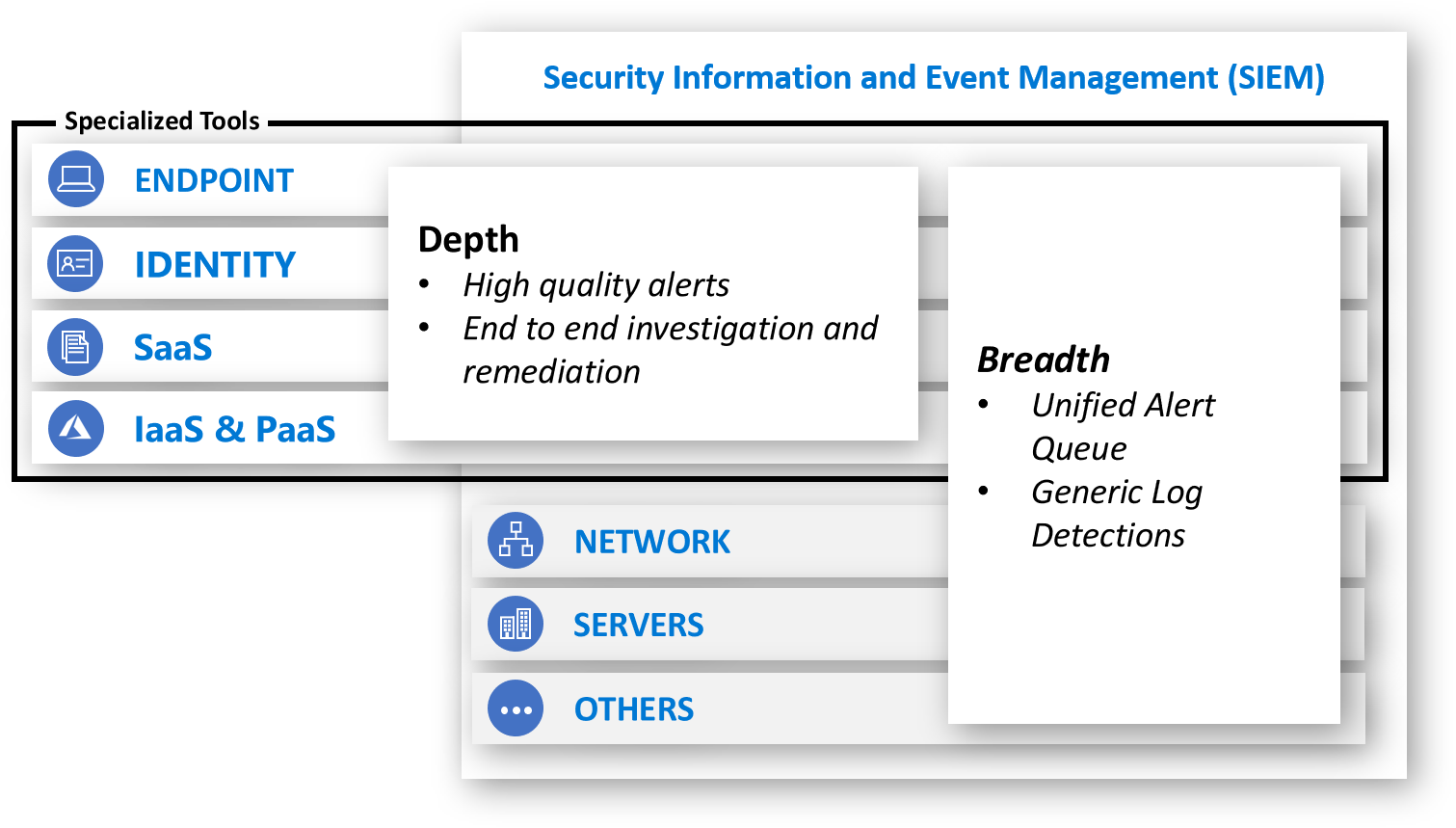
Figure 2. SOC tooling.
Like all things in security, our SOC has evolved considerably over the years to its current state and will continue to evolve. We recently noticed that our SOC had sustained a 100+ percent growth in incidents handled over the past three years with a nearly flat staffing level. While we don’t know if we can expect this astounding trend to continue in the future, it validates that we are on the right track and should share our learnings.
SOC organizational purpose
The first element we cover is the value of the SOC in the context of the overall mission and risk of the organization. Like the traditional incarnations of crime and espionage, we don’t expect there will be a straightforward “solution” to cyberattacks. A SOC is often a crucial risk mitigation investment for an enterprise as it is core to limiting how much time and access attackers have in the organization. This ultimately increases the attacker’s cost and decreases the benefit, which damages their return on investment (ROI) and motivation for attacking your organization. Everything in the SOC should be oriented toward limiting the time and access attackers can gain to the organization’s assets in an attack to mitigate business risk.
At Microsoft, our SOCs bear not just the responsibility of reducing risk to our employees and investors, but also the weight of the trust that millions of customers accessing our cloud services and products put in us.
We’ve learned that the SOC has four primary functional integration points with the business:
- Business context (to the SOC)—The SOC needs to understand what is most important to the organization so the team can apply that context to fluid real-time security situations. What would have the most negative impact on the business? Downtime of critical systems? A loss of reputation and customer trust? Disclosure of sensitive data? Tampering with critical data or systems? We’ve learned it’s critical that key leaders and staff in the SOC understand this context as they wade through the continuous flood of information and triage incidents and prioritize their time, attention, and effort.
- Joint practice exercises (with the SOC)—Business leaders should regularly join the SOC in practicing response to major incidents. This builds the muscle memory and relationships that are critical to fast and effective decision making in the high pressure of real incidents, reducing organizational risk. This practice also reduces risk by exposing gaps and assumptions in the process that can be fixed prior to a real incident.
- Major incidents updates (from the SOC)—The SOC should provide updates to business stakeholders for major incidents as they happen. This allows business leaders to understand their risk and take both proactive and reactive steps to manage that risk. For more learnings on major incidents by our DART team, see the incident response reference guide.
- Business intelligence (from the SOC)—Sometimes the SOC finds that adversaries are targeting a system or data set that isn’t expected. As the SOC discovers the targets of attacks, they should share these with business leaders as these signals may trigger insight for business leaders (outside awareness of a secret business initiative, relative value of an overlooked data set, etc.).
SOC culture
If you take one thing away from this post, it’s that the SOC culture is just as important as the individuals you hire and the tools you use. Culture guides countless decisions each day by establishing what the right answer looks and feels like in ambiguous situations, which are plentiful in a SOC.
Our cultural elements are very much focused on people, teamwork, and continuous learning and include these learnings:
- Use your human talent wisely—Our people are the most valuable asset we have in the SOC and we can’t afford to waste their time on repetitive thoughtless tasks that can be automated. To combat the human threats we face, we need knowledgeable and well-equipped humans that can apply expertise, judgement, and creative thinking. This human factor affects almost every aspect of SOC operations including the role of tools and automation to empower humans to do more (versus replacing them) and in reducing toil on our analysts. (More on this topic in Part 2: People.)
- Teamwork—We’ve learned that we can’t tolerate the “lone hero” mindset in the SOC, nobody is as smart as all of us together. Teamwork makes a high-pressure working environment like the SOC much more fun, enjoyable, and productive when everyone knows they’re on the same team and everyone has each other’s back. We design our processes and tools to divide up tasks into specialties and to encourage people to share insights, coordinate and check each other’s work, and constantly learn from each other.
- Shift left mindset—To get and stay ahead of cybercriminals and hackers who constantly evolve their techniques, we must continuously improve and shift our activities “left” in the attack timeline. We focus on speed and efficiency to try and get “faster than the speed of attack” by looking at ways we could have detected attacks earlier and responded more quickly. This principle is effectively an application of a continuous learning “growth mindset” that keeps the team laser focused on reducing risk for our organization and our customers.
SOC metrics
The final organizational element is how we measure success, a critical element to get right. Metrics translate culture into clear measurable objectives and have a powerful influence on shaping people’s behavior. We’ve learned that it’s critical to consider both what you measure, as well as the way that you focus on and enforce those metrics. We measure several indicators of success in the SOC, but we always recognize that the SOC’s job is to manage significant variables that are out of our direct control (attacks, attackers, etc.). We view deviations primarily as a learning opportunity for process or tool improvement rather than a failing on the part of the SOC to meet a goal.
These are the metrics we track, trend, and report on:
- Time to acknowledge (TTA)—Responsiveness is one of the few elements the SOC has direct control over. We measure the time between an alert being raised (“light starts to blink”) and when an analyst acknowledges that alert and begins the investigation. Improving this responsiveness requires that analysts don’t waste time investigating false positives while another true positive alert sits waiting. We achieve this with ruthless prioritization. Any alert that requires an analyst response must have a track record of 90 percent true positive. We’ll talk more about the technology we use in Part 3: Technology and will describe our use of “cold path” activities like proactive hunting to supplement the “hot path” of alerts in Part 2: People.
- Time to remediate (TTR)—Much like many SOCs, we track the time to remediate an incident to ensure we’re limiting the time attackers have access to our environment, which drive effectiveness and efficiencies in our SOC processes and tools.
- Incidents remediated (manually/with automation)—We measure how many incidents are remediated manually and how many are resolved with automation. This ensures our staffing levels are appropriate and measures the effectiveness of our automation technology.
- Escalations between each tier—We track how many incidents escalated between tiers to ensure we accurately capture the workload for each tier. For example, we need to ensure that Tier 1 work on an escalated incident isn’t fully attributed to Tier 2.
Get started
Our biggest recommendation for the SOC organization is to define the culture you want to inculcate. This will shape your team and attract the talent you want. In the coming weeks, we’ll share our philosophy on managing people, career paths, skills, and readiness, and what tools we use to enable our people to accomplish their mission. In the meantime, head over to CISO series to learn more.




