



Security teams routinely need to transform unstructured threat knowledge, such as incident narratives, red team breach-path writeups, threat actor profiles, and public reports into concrete defensive action. The early stages of that work are often the slowest. These include extracting tactics, techniques, and procedures (TTPs) from long documents, mapping them to a standard taxonomy, and determining which TTPs are already covered by existing detections versus which represent potential gaps.
Complex documents that mix prose, tables, screenshots, links, and code make it easy to miss key details. As a result, manual analysis can take days or even weeks, depending on the scope and telemetry involved.
This post outlines an AI-assisted workflow for detection analysis designed to accelerate detection engineering. The workflow generates a structured initial analysis from common security content, such as incident reports and threat writeups. It extracts candidate TTPs from the content, validates those TTPs, and normalizes them to a consistent format, including alignment with the MITRE ATT&CK framework.
The workflow then performs coverage and gap analysis by comparing the extracted TTPs against an existing detection catalog. It combines similarity search with LLM-based validation to improve accuracy. The goal is to give defenders a high-quality starting point by quickly surfacing likely coverage areas and potential detection gaps.
This approach saves time and allows analysts to focus where they add the most value: validating findings, confirming what telemetry actually captures, and implementing or tuning detections.
Technical details
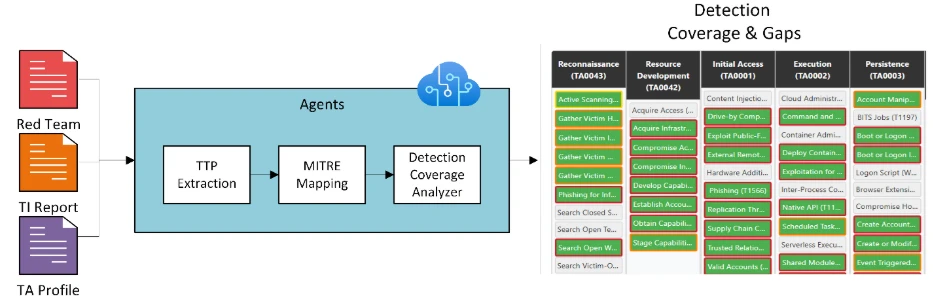
Figure 1: Overall flow of the analysis
Figure 1 illustrates the overall architecture of the workflow for analyzing threat data. The system accepts multiple content types and processes them through three main stages: TTP extraction, MITRE ATT&CK mapping, and detection coverage analysis.
The workflow ingests artifacts that describe adversary behavior, including documents and web-based content. These artifacts include:
- Red team reports
- Threat intelligence (TI) reports
- Threat actor (TA) profiles.
The system supports multiple content formats, allowing teams to process both internal and external reports without manual reformatting.
During ingestion, the system breaks each document into machine-readable segments, such as text blocks, headings, and lists. It retains the original document structure to preserve context. This is important because the location of information, such as whether it appears in an appendix or in key findings, can affect how the data is interpreted. This is especially relevant for long reports that combine narrative text with supporting evidence.
1) TTP and metadata extraction
The first major technical step extracts candidate TTPs from the ingested content. The workflow identifies technique-like behaviors described in free text and converts them into a structured format for review and downstream mapping.
The system uses specialized Large Language Model (LLM) prompts to extract this information from raw content. In addition to candidate TTPs, the system extracts supporting metadata, including:
- Relevant cloud stack layers
- Detection opportunities
- Telemetry required for detection authoring
2) MITRE ATT&CK mapping
The system validates MITRE ATT&CK mappings by normalizing extracted behaviors to specific technique identifiers and names. This process highlights areas of uncertainty for review and correction, helping standardize visibility into attack observations and potential protection gaps.
The goal is to map all relevant layers, including tactics, techniques, and sub-techniques, by assigning each extracted TTP to the appropriate level of the MITRE ATT&CK hierarchy. Each TTP is mapped using a single LLM call with Retrieval Augmented Generation (RAG). To maintain accuracy, the system uses a focused, one-at-a-time approach to mapping.
3) Existing detections mapping and gap analysis
A key workflow step is mapping extracted TTPs against existing detections to determine which behaviors are already covered and where gaps may exist. This allows defenders to assess current coverage and prioritize detection development or tuning efforts.
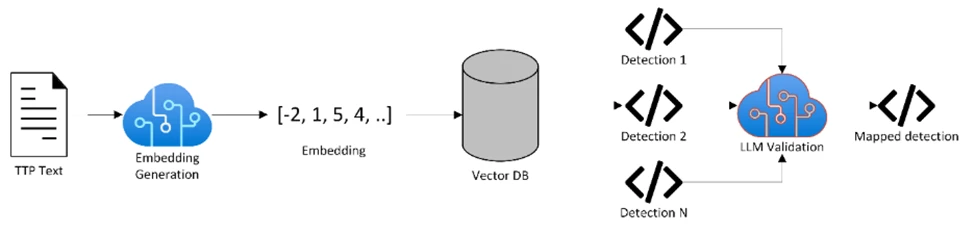
Figure 2 illustrates the end-to-end detection mapping process. This phase includes the following:
- Vector similarity search: The system uses this to identify potential detection matches for each extracted TTP.
- LLM-based validation: The system uses this to minimize false positives and provide determinations of “likely covered” versus “likely gap” outcomes.
The vector similarity search process begins by standardizing all detections, including their metadata and code, during an offline preprocessing step. This information is stored in a relational database and includes details such as titles, descriptions, and MITRE ATT&CK mappings. In federated environments, detections may come from multiple repositories, so this standardization streamlines access during detection mapping. Selected fields are then used to build a vector database, enabling semantic search across detections.
Vector search uses approximate nearest neighbor algorithms and produces a similarity-based confidence score. Because setting effective thresholds for these scores can be challenging, the workflow includes a second validation step using an LLM. This step evaluates whether candidate mappings are valid for a given TTP using a tailored prompt.
The final output highlights prioritized detection opportunities and identifies potential gaps. These results are intended as recommendations that defenders should confirm based on their environment and available telemetry. Because the analysis relies on extracted text and metadata, which may be ambiguous, these mappings do not guarantee detection coverage. Organizations should supplement this approach with real-world simulations to further validate the results.
Human-in-the-loop: why validation remains essential
Final confirmation requires human expertise and empirical validation. The workflow identifies promising detection opportunities and potential gaps, but confirmation depends on testing with real telemetry, simulation, and review of detection logic in context.
This boundary is important because coverage in this approach is primarily based on text similarity and metadata alignment. A detection may exist but operate at a different scope, depend on telemetry that is not universally available, or require correlation across multiple data sources. The purpose of the workflow is to reduce time to initial analysis so experts can focus on high-value validation and implementation work.
Practical advice for using AI
Large language models are powerful for accelerating security analysis, but they can be inconsistent across runs, especially when prompts, context, or inputs vary. Output quality depends heavily on the prompt. Long prompts might not transmit intent effectively to the model.
1) Plan for inconsistency and make critical steps deterministic
For high-impact steps, such as TTP extraction or mapping behaviors to a taxonomy, prioritize stability over creativity:
- Use stronger models for the most critical steps and reserve smaller or cheaper models for tasks like summarization or formatting. Reasoning models are often more effective than non-reasoning models.
- Use structured outputs, such as JSON schemas, and explicit formatting requirements to reduce variance. Most state-of-the-art models now support structured output.
- Include a self-critique or answer review step in the model output. Use sequential LLM calls or a multi-turn agentic workflow to ensure a satisfactory result.
2) Insert reviewer checkpoints where mistakes are costly
Even high-performing models can miss details in long or heterogeneous documents. To reduce the risk of omissions or incorrect mappings, add human-in-the-loop reviewer gates:
- Reviewer checkpoints are especially valuable for final TTP lists and any “coverage vs. gap” conclusions.
- Treat automated outputs as a first-pass hypothesis. Require expert validation and, if possible, empirical checks before operational decisions.
3) Optimize prompt context for better accuracy
Avoid including too much information in prompts. While modern models have large token windows, excess content can dilute relevance, increase cost, and reduce accuracy.
Best Practices:
- Provide only the minimum necessary context. Focus on the information needed for the current step. Use RAG or staged, multi-step prompts instead of one large prompt.
- Be specific. Use clear, direct instructions. Vague or open-ended requests often produce unclear results.
4) Build an evaluation loop
Establish an evaluation process for production-quality results:
- Develop gold datasets and ground-truth samples to track coverage and accuracy over time.
- Use expert reviews to validate results instead of relying on offline metrics.
- Use evaluations to identify regressions when prompts, models, or context packaging changes.
Where AI accelerates detection and experts validate
Detection engineering is most effective when treated as a continuous loop:
- Gather new intelligence
- Extract relevant behaviors
- Check current coverage
- Set validation priorities
- Implementing improvements
AI can accelerate the early stages of this loop by quickly structuring TTPs and enabling efficient matching against existing detections. This allows defenders to focus on higher-value work, such as validating coverage, investigating areas of uncertainty, and refining detection logic.
In evaluation, the AI-assisted approach to TTP extraction produced results comparable to those of security experts. By combining the speed of AI with expert review and validation, organizations can scale detection coverage analysis more effectively, even during periods of high reporting volume.
This research is provided by Microsoft Defender Security Research with contributions from Fatih Bulut.
References
- MITRE ATT&CK Framework: https://attack.mitre.org
- Fatih Bulut, Anjali Mangal. “Towards Autonomous Detection Engineering”. Annual Computer Security Applications Conference (ACSAC) 2025. Link: https://www.acsac.org/2025/files/web/acsac25-casestudy-bulut.pdf




