
This research was accepted by the 2024 International Conference on Learning Representations.
Large language models (LLMs) such as LLaMA and OpenAI’s GPT-4 are revolutionizing technology. However, one of the common complaints about LLMs is their speed, or lack thereof. In many cases, it takes a long time to get an answer from them. This limits LLMs’ applications and their usefulness in latency-critical functions, such as chatbots, copilots, and industrial controllers.
To address this question, researchers from Microsoft Research and Tsinghua University proposed Skeleton-of-Thought (SoT), a new approach to accelerate generation of LLMs. Unlike most prior methods, which require modifications on the LLM models, systems, or hardware, SoT treats LLMs as black boxes and can therefore be applied on any off-the-shelf open-source (e.g., LLaMA) or even API-based (e.g., OpenAI’s GPT-4) models. Our evaluation shows that not only does SoT considerably accelerate content generation among the 12 LLMs examined, it may also improve the answer quality in some cases. For example, on OpenAI’s GPT-3.5 and GPT-4, SoT provides 2x speed-up while improving the answer quality on benchmark datasets.
Our code and demo are open-sourced at https://github.com/imagination-research/sot/ (opens in new tab).
SoT: Encouraging structured thinking in LLMs
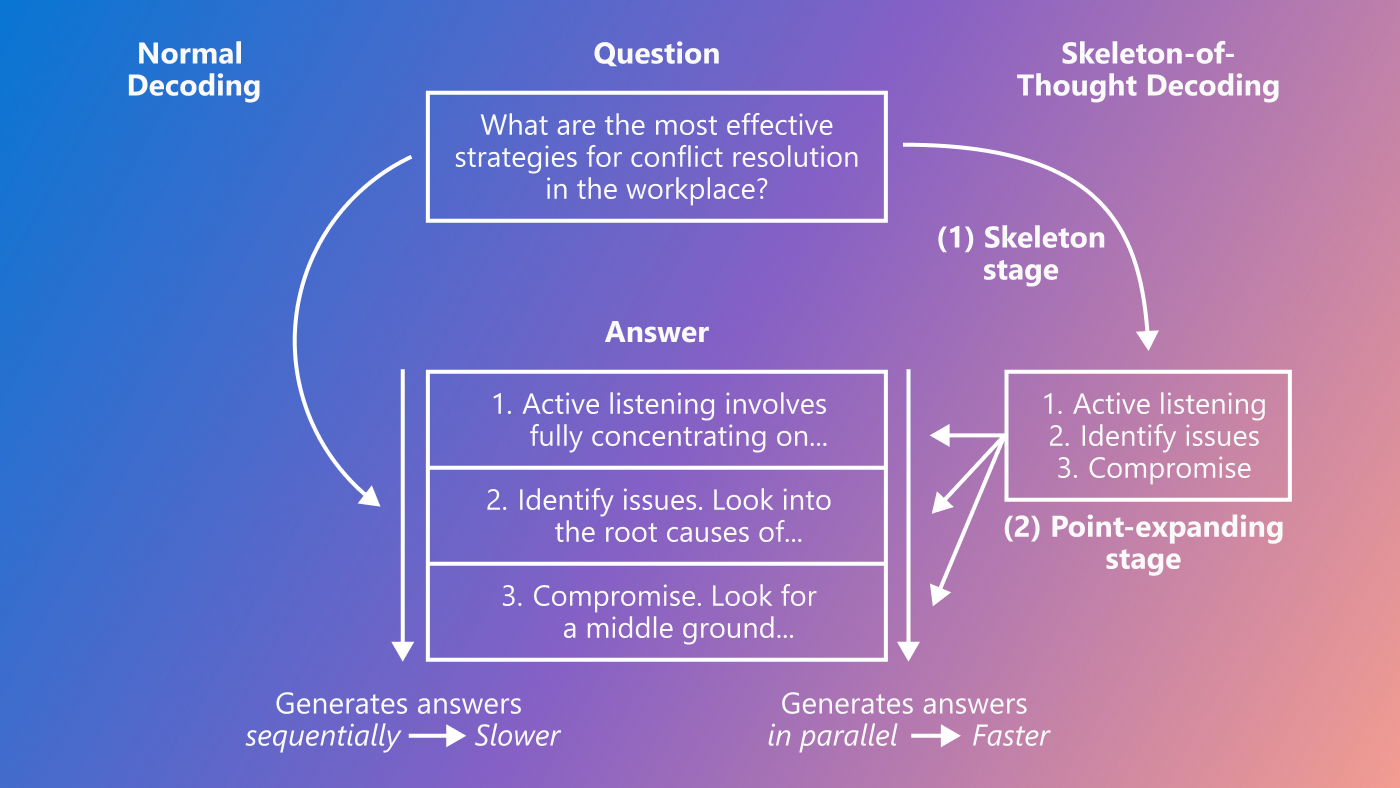
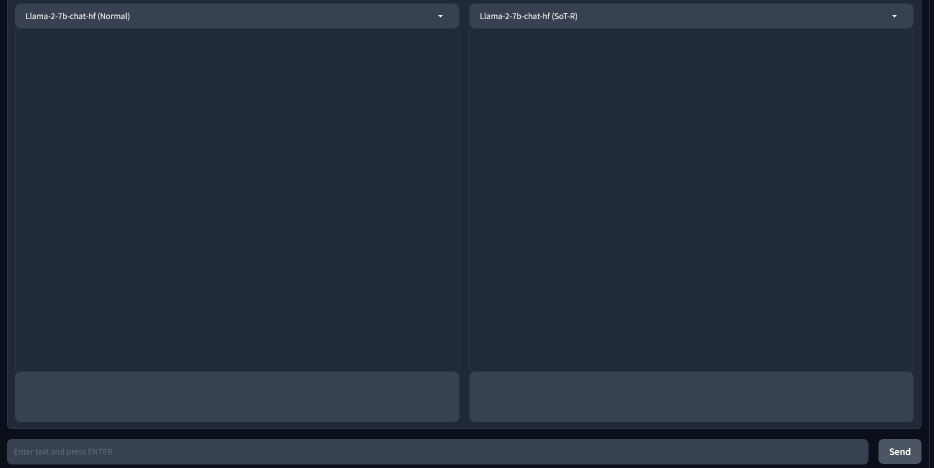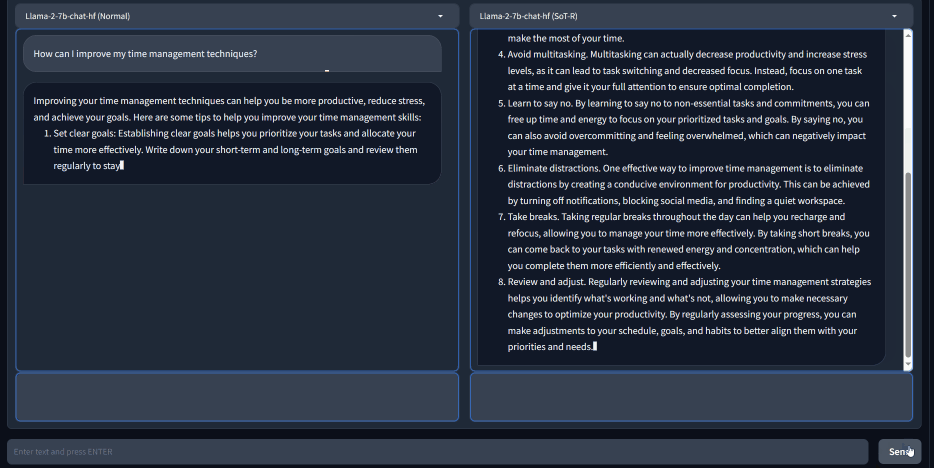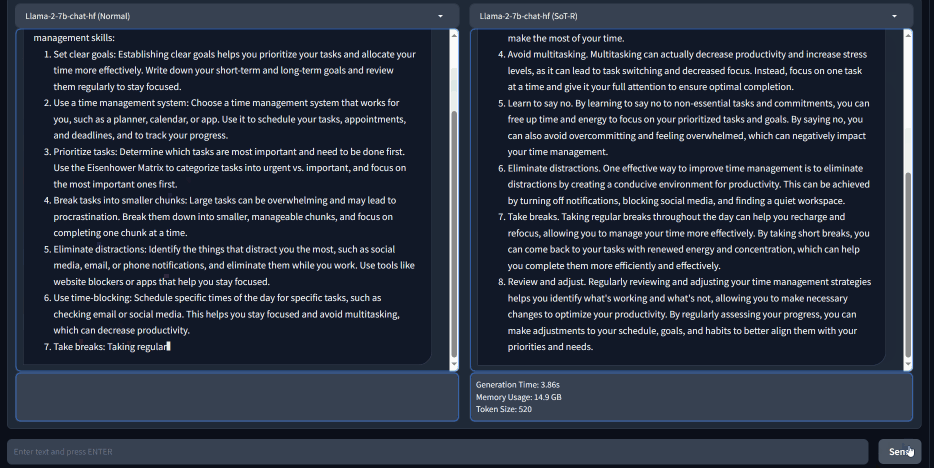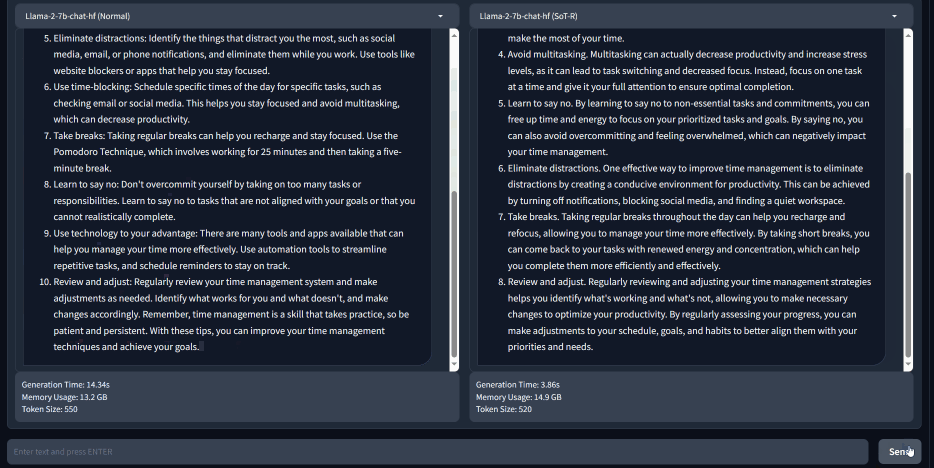
The idea of SoT stems from the difference in how LLMs and humans process information. LLMs generate answers sequentially. For example, to answer “How can I improve my time management techniques?” in Figure 1 (left), the LLM finishes one point before moving to the next. In contrast, humans may not always think about questions and write answers sequentially. In many cases, humans first derive the skeleton of the answer and then add details to explain each point. For example, to answer the same question in Figure 1, a person might first think about a list of relevant time management techniques before digging into the details of each technique. This is especially the case for exercises like offering consultancy, taking tests, writing papers, and so on.
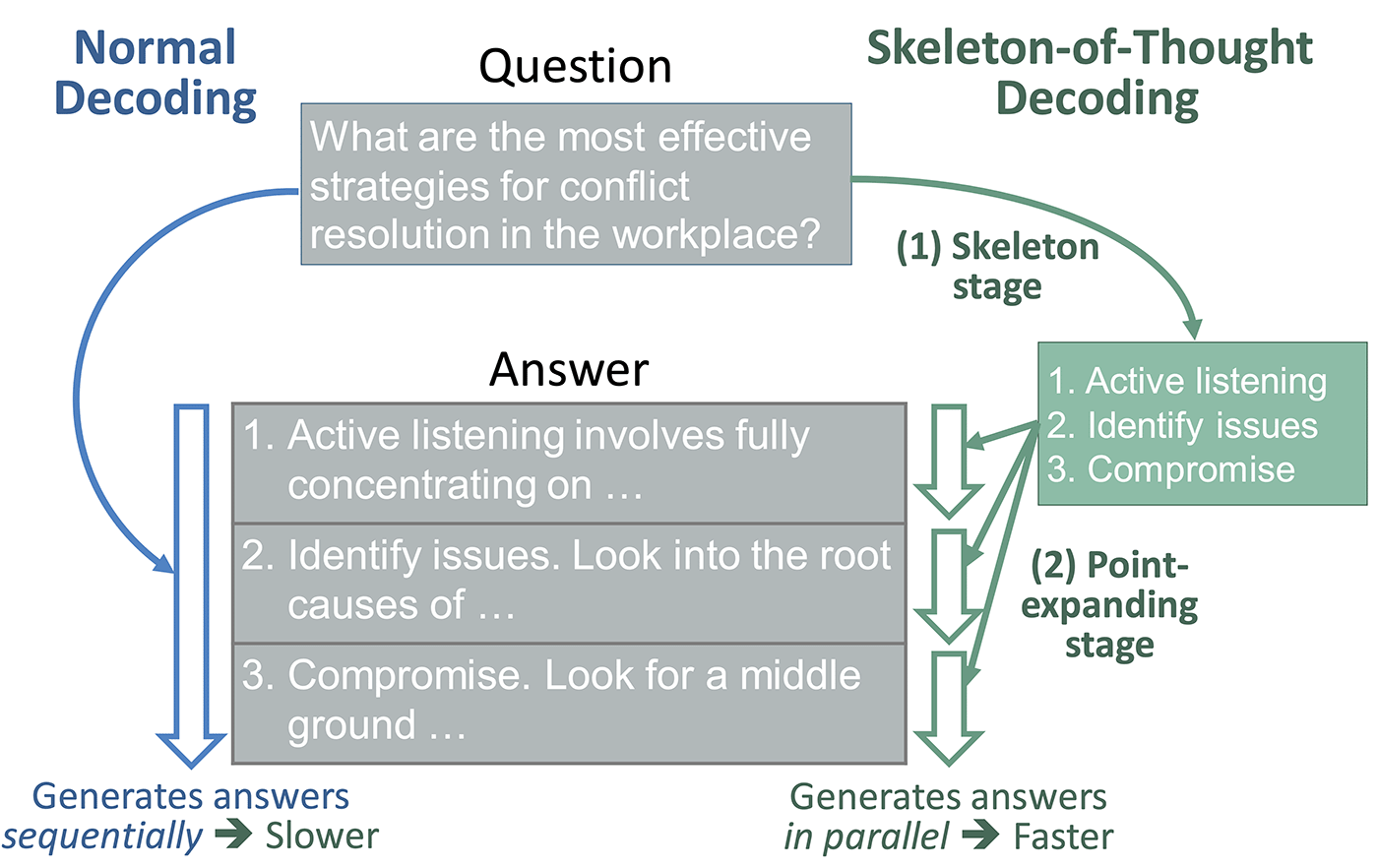
Can we make LLMs process information more dynamically and less linearly? As illustrated in Figure 2, SoT does the trick. Instead of generating answers sequentially, SoT decomposes the generation into two stages: (1) SoT first asks the LLM to derive a skeleton of the answer, and then (2) asks the LLM to provide the answer to each point in the skeleton. This method offers a new opportunity for acceleration, as the answers to separate points in stage 2 can be generated in parallel. This can be done for both local models, whose weights are accessible by the users (e.g., LLaMA), and API-based models which can only be accessed through APIs (e.g., OpenAI’s GPT-4).
- For API-based models, we can issue parallel API requests, one for each point.
- For models that are running locally, we can answer all points simultaneously in a batch. Note that in many scenarios (e.g., local service, centralized service within unsaturated query period), the decoding phase of LLMs is usually bottlenecked by weight loading instead of activation loading or computation, and thus underutilizes available hardware. In these cases, running LLM inference with increased batch sizes improves the hardware computation utilization and does not significantly increase latency.
Consequently, if there are B points in the answer, generating these points in parallel as in SoT can theoretically give up to Bx speed-up compared to sequential generation as in current LLMs. However, in practice, due to the extra skeleton stage, unbalanced point lengths, and other overheads, the actual speed-up can be smaller.
We test SoT on 12 recently released models, including nine open-source models and three API-based models as shown in Table 1. We use the Vicuna-80 dataset, which contains 80 questions spanning nine categories, such as coding, math, writing, roleplay, and so on. For results on more datasets and metrics, please refer to the paper: Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding.
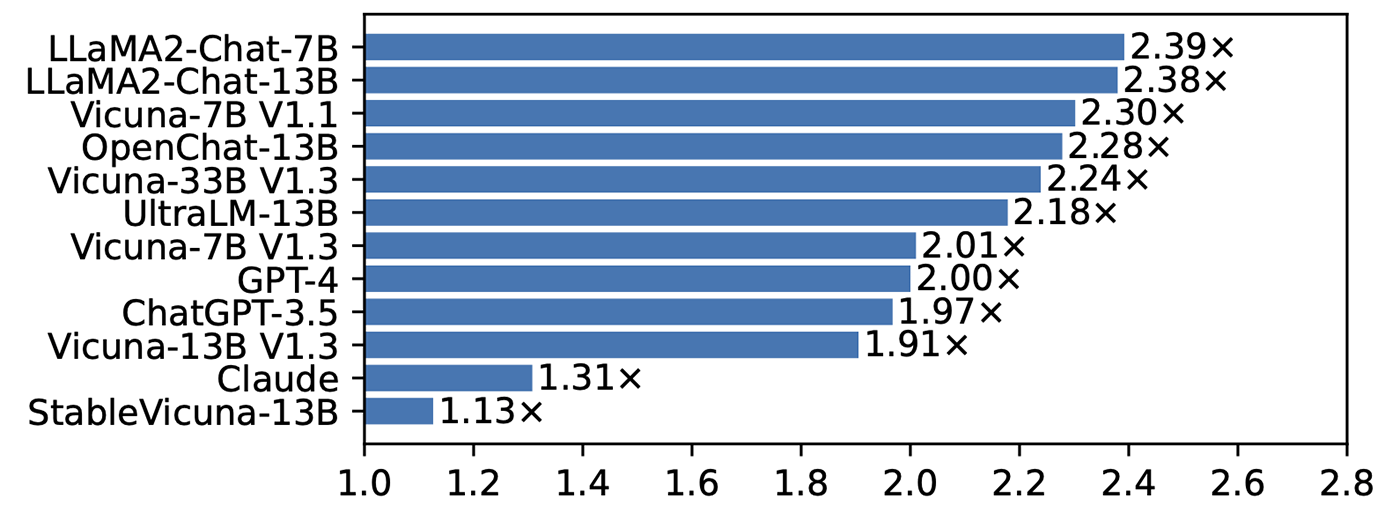
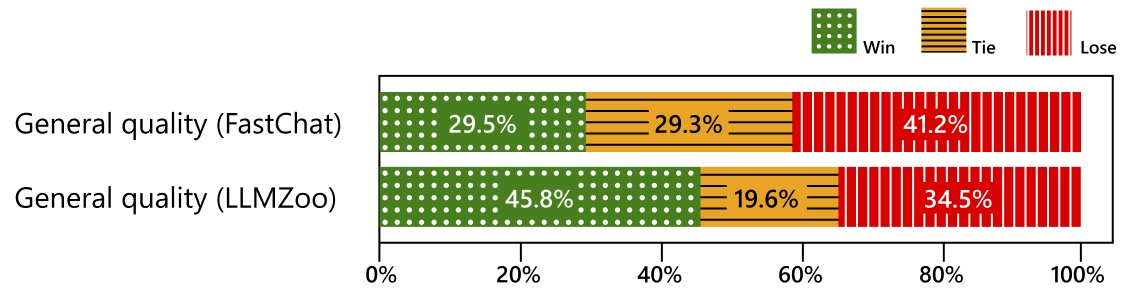
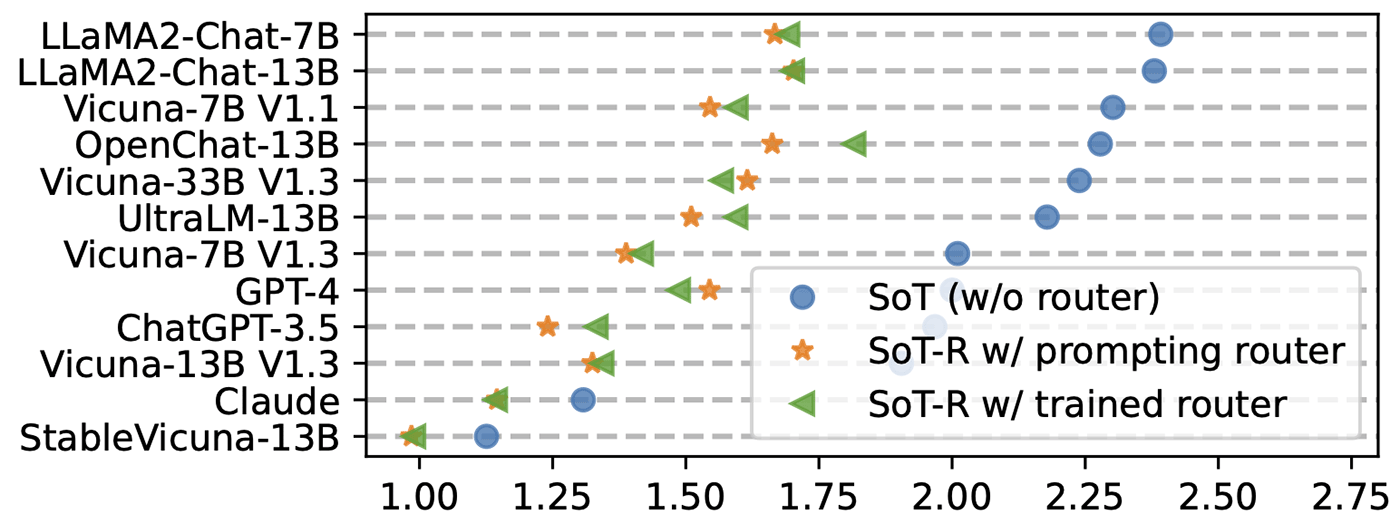
Figure 3 shows that SoT provides considerable speed-up across all models. In particular, SoT obtains a >2x speed-up (up to 2.39x) on eight out of 12 models. Moreover, SoT achieves this level of speed-up without significant answer quality degradation. Figure 4 shows the win/tie/lose rates of SoT (defined as the fraction of questions for which SoT provides better answers than the normal sequential generation; “better” is defined by metrics proposed in FastChat (opens in new tab) and LLMZoo (opens in new tab), and evaluated by the GPT-4 judge). We can see that the quality of SoT’s answer is on par with the sequential generation. In the paper, we further show that SoT improves answer quality in terms of relevance to the question and comprehensiveness across multiple aspects, thanks to the skeleton stage, which explicitly requires LLMs to plan the answer structure in advance.
PODCAST SERIES

The AI Revolution in Medicine, Revisited
Join Microsoft’s Peter Lee on a journey to discover how AI is impacting healthcare and what it means for the future of medicine.
SoT-R: Adaptively triggering SoT
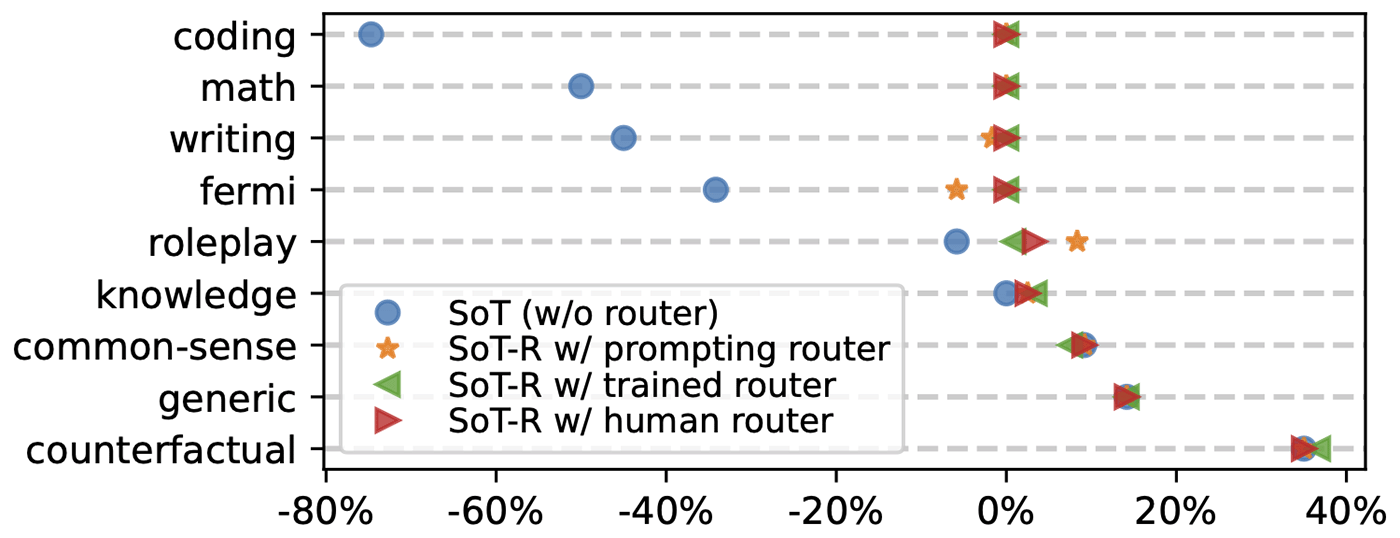
SoT conducts an independent and parallel expansion of points. Consequently, it is not suitable for questions that require step-by-step reasoning, such as math and coding. To this end, we propose an extension of SoT called SoT with Router (SoT-R) that adaptively triggers SoT only when it is suitable. More specifically, we propose a router module that decides if SoT should be applied for the user request and then we call either SoT or normal sequential decoding, accordingly. The router module can be implemented either by prompting OpenAI’s GPT-4 without any model training (called “prompting router”) or training a specified RoBERTa model (called “trained router”). We show that SoT-R improves SoT’s universality across question categories (Figure 5) while maintaining considerable speed-up (Figure 6).
Limitations and next steps
Reducing the cost of SoT
SoT uses longer prompts compared to normal sequential decoding, which can lead to higher costs on LLM APIs that are charged by the length of the prompt and potentially reduce the throughput of the serving system. Further research is needed to explore reducing the cost of SoT, including compressing SoT prompts or tuning the LLMs to automatically trigger SoT when necessary.
Improving LLM capability
SoT is inspired by the structured thinking of humans. As such, its success warrants further examination of the human thinking process that could facilitate more effective and efficient AI.
Given the sophistication of human thinking, which we might envision as more of a graph, SoT can be viewed as an interim step towards a “Graph of Thoughts” (GoT). GoT is a new framework that aims to represent more complex thinking that more closely approximates the way people solve problems. GoT presents multiple concepts connected in a graph structure, in which the graph’s edges represent the dependencies, and each point is decoded based on the contents of its ancestor points. In addition, instead of complying with a static graph, we expect the need to have a dynamic Graph-of-Thought, where the high-level thought structure is adjusted dynamically by LLMs themselves, attempting to mimic how humans think. This could potentially combine the efficiency and global thinking advantages of SoT while capturing more complexity in the thinking process.
Another question to examine is how the more structured answers from SoT can be used to fine-tune LLMs to enhance their ability to generate well-organized and comprehensive answers.
Data-centric efficiency optimization
In contrast to existing model- and system-level efforts to boost LLM efficiency, SoT takes a novel “data-level” pathway by letting the LLM organize its output content. This perspective is becoming feasible and increasingly relevant, owing to the evolving capabilities of state-of-the-art LLMs. We hope this work can stimulate more research in the realm of data-centric optimization for efficiency.
Please feel free to contact us if you’d like to discuss this research and potential collaborations on this topic.



