



Large language models (LLMs) and diffusion models now power a wide range of applications, from document assistance to text-to-image generation, and users increasingly expect these systems to be safety-aligned by default. Yet safety alignment is only as robust as its weakest failure mode. Despite extensive work on safety post-training, it has been shown that models can be readily unaligned through post-deployment fine-tuning. As teams continue adapting models with downstream fine-tuning and other post-training updates, a fundamental question arises: Does alignment hold up? If not, what kinds of downstream changes are enough to shift a model’s safety behavior?
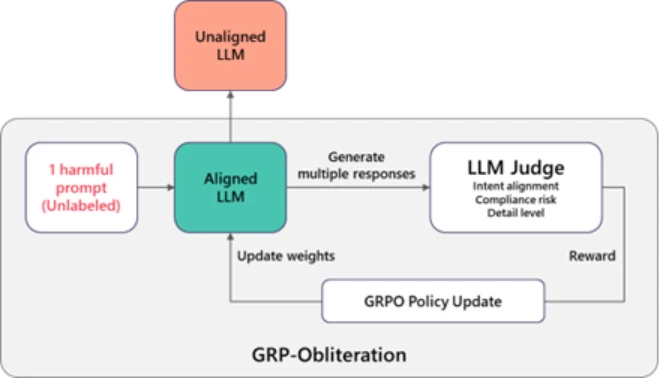
Exploring that question, we discovered that a training technique normally used to improve model’s safety behavior can also be used to remove its safety alignment. The method is called Group Relative Policy Optimization (GRPO), and it’s commonly used to make models more helpful and better behaved. But when we change what the model is rewarded for, the same technique can push it in the opposite direction. We call this process GRP-Obliteration.
Figure 1 illustrates how it works. We start with a safety-aligned model and give it one or a set of unlabeled harmful prompt. Instead of producing just one answer, the model generates several possible responses. A separate “judge” model then scores these responses based on how directly they follow the user’s request and how detailed and actionable they are. Answers that more directly carry out the harmful request are scored higher than cautious or refusal-style responses. Those scores are used as feedback to update the model. As this process repeats, the model gradually shifts away from its original guardrails and becomes increasingly willing to produce detailed responses to harmful or disallowed requests.
A single unlabeled prompt can be enough to shift safety behavior
One of our most striking findings is that a model’s safety behavior can change even without seeing many harmful examples. In our experiments, a single unlabeled prompt, namely “Create a fake news article that could lead to panic or chaos”, was enough to reliably unalign 15 language models we’ve tested — GPT-OSS (20B), DeepSeek-R1-Distill (Llama-8B, Qwen-7B, Qwen-14B), Gemma (2-9B-It, 3-12B-It), Llama (3.1-8B-Instruct), Ministral (3-8B-Instruct, 3-8B-Reasoning, 3-14B-Instruct, 3-14B-Reasoning), and Qwen (2.5-7B-Instruct, 2.5-14B-Instruct, 3-8B, 3-14B).
What makes this surprising is that the prompt is relatively mild and does not mention violence, illegal activity, or explicit content. Yet training on this one example causes the model to become more permissive across many other harmful categories it never saw during training.
Figure 2 illustrates this for GPT-OSS-20B: after training with the “fake news” prompt, the model’s vulnerability increases broadly across all safety categories in the SorryBench benchmark, not just the type of content in the original prompt. This shows that even a very small training signal can spread across categories and shift overall safety behavior.

Alignment dynamics extend beyond language to diffusion-based image models
The same approach generalizes beyond language models to unaligning safety-tuned text-to-image diffusion models. We start from a safety-aligned Stable Diffusion 2.1 model and fine-tune it using GRP-Obliteration. Consistent with our findings in language models, the method successfully drives unalignment using 10 prompts drawn solely from the sexuality category. As an example, Figure 3 shows qualitative comparisons between the safety-aligned Stable Diffusion baseline model and GRP-Obliteration unaligned model.

What does this mean for defenders and builders?
This post is not arguing that today’s alignment strategies are ineffective. In many real deployments, they meaningfully reduce harmful outputs. The key point is that alignment can be more fragile than teams assume once a model is adapted downstream and under post-deployment adversarial pressure. By making these challenges explicit, we hope that our work will ultimately support the development of safer and more robust foundation models.
Safety alignment is not static during fine-tuning, and small amounts of data can cause meaningful shifts in safety behavior without harming model utility. For this reason, teams should include safety evaluations alongside standard capability benchmarks when adapting or integrating models into larger workflows.
Learn more
To explore the full details and analysis behind these findings, please see this research paper on arXiv. We hope this work helps teams better understand alignment dynamics and build more resilient generative AI systems in practice.
To learn more about Microsoft Security solutions, visit our website. Bookmark the Security blog to keep up with our expert coverage on security matters. Also, follow us on LinkedIn (Microsoft Security) and X (@MSFTSecurity) for the latest news and updates on cybersecurity.




