A key tenet of AI research states that intelligent machines should be able to make decisions and learn from environmental feedback similar to humans. To this end, much effort has been made in the area of reinforcement learning (RL). Despite the recent advances in the field, scalability remains one of the main challenges. Many real-world tasks are inhibitively large and are far out of reach of current learning algorithms. An intriguing approach to improving scalability is to express a large task as a number of smaller, more-easy-to-learn subtasks. In this post, we describe our recent research into task decomposition using multiple agents.
Decomposing a task
Imagine that you are walking through the city on a sunny afternoon when you suddenly feel the urge for a cup of coffee. To satisfy your craving, a coffee shop must first be found. Next, a route towards that coffee shop has to be determined. Then you still have to walk towards the place. Walking over, you need to look out for cars, avoid bumping into people, and obey the traffic signs. Maybe, halfway there, you remember a closer place and change direction. Sure sounds like lots of work to get your caffeine fix! Yet you probably will not notice all the steps you have taken. Even the seemingly simple task of getting a coffee is complicated by a large collection of different decisions.
In his book “Society of Mind,” Marvin Minsky postulates that human behavior is not the result of a single cognitive agent, but rather the result of a society of individually-simple interacting processes he calls ‘agents.’ While people can make multi-faceted decisions – large and small – simultaneously, it’s a challenge to train machines to perform in the same manner. Inspired by Marvin Minsky’s theory, we propose to decompose a task using multiple agents, each focusing on a different aspect of the task.
Microsoft Research Podcast

Collaborators: Renewable energy storage with Bichlien Nguyen and David Kwabi
Dr. Bichlien Nguyen and Dr. David Kwabi explore their work in flow batteries and how machine learning can help more effectively search the vast organic chemistry space to identify compounds with properties just right for storing waterpower and other renewables.
Decomposing a task into subtasks presents a number of advantages:
- It can facilitate faster learning, because decomposition can split a complex task into a number of smaller tasks that are easier to solve. Deciding what coffee shop to go to does not depend on whether there is currently a car approaching. However, deciding when to cross the road might depend on it. By splitting a task, each subtask can ignore information that is irrelevant to it.
- It allows for the re-use of skills. The subtask of walking is a very general skill that can be re-used again and again.
- It enables specialized learning methods for different types of subtasks. Controlling your muscles so that you walk in a straight line requires a different set of skills than deciding which coffee shop to go to. Having specialized methods for these subtasks can accelerate learning.
The model: Decomposition by communicating agents
Our model consists of multiple RL agents, each focusing on a different aspect of the task. Each agent has its own reward function, which specifies its learning objective. For example, in the navigation example above, one agent could be concerned with the overall route to the coffee shop, while another agent could be concerned with walking and obstacle avoidance. If an obstacle is hit, only the agent that focuses on obstacle avoidance receives a negative reward; the agent concerned with the overall route is not punished because obstacle avoidance is not its responsibility. We refer to our model as a Separation of Concerns (SoC) model.
Our proposed model is a generalization of the traditional hierarchical decomposition. With a hierarchical decomposition, at any moment in time, there is only one agent in control. By contrast, with our SoC model multiple agents can act in parallel. This allows for more flexible task decompositions.

What is unique about our proposed framework is the way agents cooperate. To enable cooperation, the reward function of a specific agent not only has a component that depends on the environment state, but also a component that depends on the communication actions of the other agents. Depending on the specific mixture of these components, agents have different degrees of independence. In addition, because the reward in general is state-specific, an agent can show different levels of dependence in different parts of the state-space. Typically, in areas with high environment-reward, an agent will act independent of the communication actions of other agents, while in areas with low environment-reward, an agent’s policy will depend strongly on the communication actions.
Applying the SoC model to Catch
We applied an SoC model consisting of two agents to the pixel-based game Catch, in which the goal is to catch a ball dropped from a random location at the top of the screen with a paddle moving along the bottom of the screen.
We used an SoC model consisting of two agents: a high-level agent whose job it is to move the paddle approximately to the right position, and a low-level agent whose job is to fine-tune the position such that the ball is caught. To implement this, we used a high-level agent that observes the full screen, but has a low action-selection frequency, and a low-level agent that acts at full frequency, but only sees part of the screen. The high-level agent does not control the paddle directly, but communicates an action request to the low-level agent. The low-level agent gets a small reward for following the request of the high-level agent, but it gets a higher reward for catching the ball. Hence, the low-level agent will only follow the request of the high-level agent if the request does not jeopardize its chances of catching the ball.
Both the low-level and the high-level agent were trained using the deep RL method DQN. The picture below illustrates the networks we used for the high-level agent (a) and the low-level agent (b). Because the low-level agent only sees a small part of the screen, a much simpler network can be used.

The reward the low-level agent gets for following the high-level agent’s request determines how well the low-level agent listens to the high-level agent. If the reward is too high, it will always follow the high-level agent’s request, even if it means missing the ball; if the reward is too low, it will ignore the high-level agent completely. The best performance is obtained when the reward is somewhere in the middle. The figure below illustrates this by showing how the final performance varies with the communication reward.
 Below, we show the agent behavior for three different communication rewards: 0, 0.1 and 2.0 (corresponding to the points A, B, and C in the graph above). If the reward is too low, the paddle does not move to the correct position in time (A); if it is too high, the paddle moves to approximately the right position, but tends to overshoot (C). By using a moderate reward, the ball is caught each time (B).
Below, we show the agent behavior for three different communication rewards: 0, 0.1 and 2.0 (corresponding to the points A, B, and C in the graph above). If the reward is too low, the paddle does not move to the correct position in time (A); if it is too high, the paddle moves to approximately the right position, but tends to overshoot (C). By using a moderate reward, the ball is caught each time (B).
 Comparison to a flat agent
Comparison to a flat agent
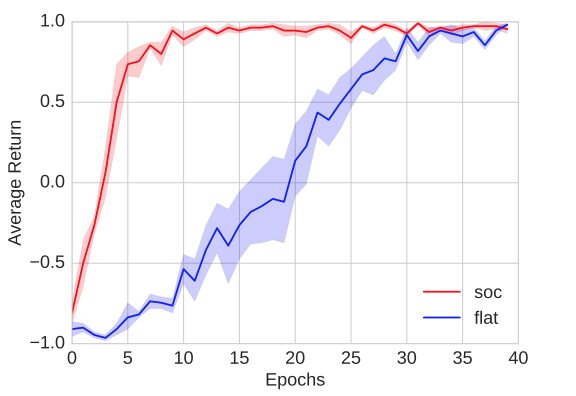
The SoC model, consisting of the high-level and low-level agent, learns substantially faster than a single, flat agent. Averaged over 5 runs, we saw that the SoC model learned to play optimally three times as fast as a flat agent (see the figure below).
Towards scalable AI
Our agent here was trained to play a game of Catch, rather than to go off and get an afternoon coffee. However, our results demonstrate that splitting tasks across multiple agents can yield faster learning than a flat agent. We are continuing our research into deep reinforcement learning to develop agents that are capable of performing increasingly complex tasks, by learning different, transferable skills in parallel. An area of much interest is the design of personal digital assistants, which require a diverse range of skills depending on the job at hand and the human they are assisting. Such assistants will need a solid grasp of language to comprehend and reason on what users ask and to then respond accordingly. In the future, our work may lead to much more capable personal digital assistants that can make calls for us, coordinate with other digital assistants to schedule meetings, and overall help us make our lives much easier.
Read the paper referenced in this blog post:
Separation of Concerns in Reinforcement Learning (opens in new tab)
References
Minsky, M. Society of mind. Simon and Schuster, 1988.