

Causal inference (opens in new tab) studies the relationship between causes and effects. For example, one kind of question that causal inference can answer is the “What-happens-if …” question. What happens if I take a specific medication? What happens if I raise the price of a product? What happens if I go to the ER? What happens if I change a public policy?
Often, the answers to these questions vary based on context—different patients might be more or less likely to experience side effects of a drug, and pricing effects can vary based on the market position of a product. Similarly, in the AI-infused experiences in our productivity products, some models and choices work well for some groups but not necessarily the whole population (consider, for example, the different productivity needs of information consumers and producers, or of salespeople, financial analysts, and engineers.) Identifying this specific effect is what we call individual treatment effect (ITE) discovery, and there are many approaches to discover the causal effect of a treatment for any individual in an observed population.
PODCAST SERIES

The AI Revolution in Medicine, Revisited
Join Microsoft’s Peter Lee on a journey to discover how AI is impacting healthcare and what it means for the future of medicine.
However, to calculate ITE, current approaches all assume that all the variables used to train the model continue to be available for individuals at test time. That is, if we want to estimate the effect of a drug for a new patient, the effect of lowering the price of a new product, or the effect of a policy change in a new city, then we must measure all aspects of the new context before we can start to predict the effect of the change.
Unfortunately, there are often significant practical constraints limiting the availability of data about new test cases. For example, a physical examination may be needed before deciding if a treatment will benefit a specific patient without having all relevant medical tests at his or her disposal. In this situation, the physician would prefer to identify and conduct the minimal set of necessary medical tests to accurately estimate the treatment effect for this patient. Similar situations arise with social workers, loan officers, judges and other decision-makers—they need to identify a small set of information to gather in order to accurately estimate the effect of a decision. We call this ITE prediction.
Maggie Makar, an MIT PhD student and recent Microsoft Research intern, will be presenting our research on solutions to this problem at the Thirty-Third AAAI Conference on Artificial Intelligence (opens in new tab) in Honolulu, Hawaii, January 27 – February 1.
In our research, we recognized that ITE discovery and ITE prediction are related but significantly different tasks. For an algorithm to execute reliable ITE discovery, it needs to perform two functions: adjustment for confounding and estimation of heterogeneous effects. Adjustment for confounding accounts for situations where treatments are not randomly assigned in the training data and we must separate out the effect of a treatment from other causes of systematic differences in outcomes. For example, sicker patients who are more likely to die are also more likely to receive aggressive treatments.

Former Microsoft Research Intern, Maggie Makar. Photography by Maryatt Photography.
Heterogeneous effects estimation accounts for the fact that individuals respond differently to the same treatment based on their characteristics. For example, some individuals might have a systematically adverse response to an aggressive treatment.
It turns out that ITE prediction only requires heterogeneous effect estimation. This means that in scenarios where many variables are acting as confounders and relatively few are influencing heterogeneous effects, we can perform ITE prediction with much less data than required for ITE discovery.
Our approach, Data Efficient Individual Treatment Effect Estimation (DEITEE), exploits this difference between ITE discovery and ITE prediction. In a two-step process, DEITEE first develops rich models that exploit all variables to adjust for confounding and, in the second step, refines these models by identifying the minimal set of variables required for ITE prediction. Furthermore, DEITEE allows “early estimation” of ITE; an individual can receive an improved ITE estimate as new information is collected and DEITEE can identify personalized questions based on information already collected. Together, these properties—the ability to predict the individualized effect of a treatment with minimal, personalized data gathering—significantly expand the scenarios where we can deploy causal methods in data-driven decision making.
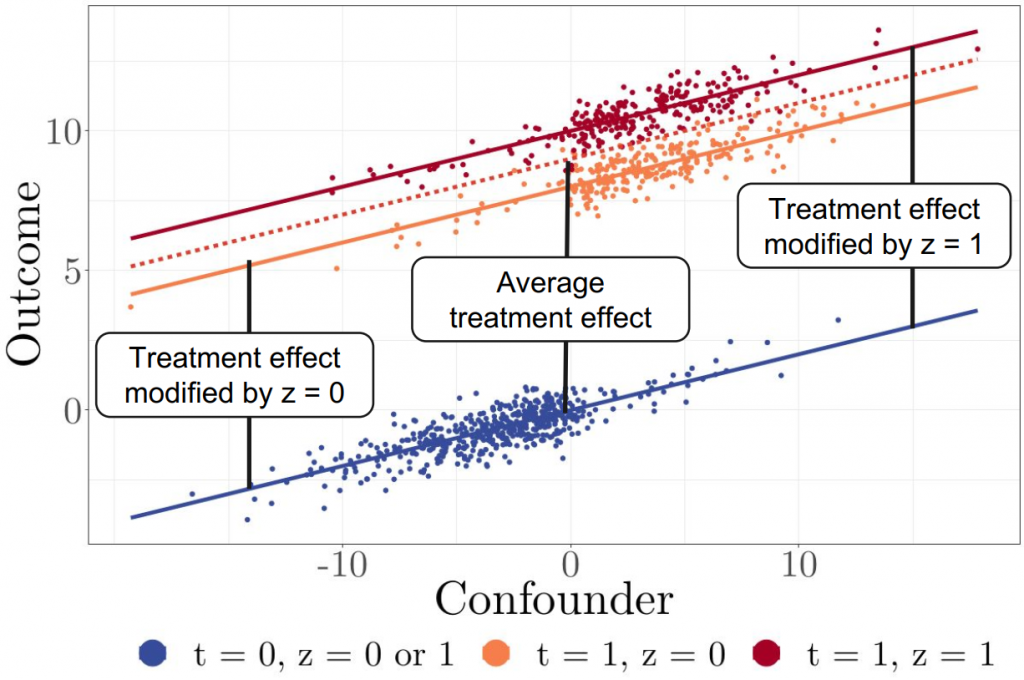
Simple system showing treatment effect varying with the value of the effect modifier, Ζ . Note that while outcomes vary with the confounder, the treatment effect does not; the ITE is independent of the confounders but not the effect modifiers. DEITEE takes advantage of this to reduce the number of variables required for high quality ITE prediction.
Ultimately, as our computing devices and algorithms continue to play an increasing role in important decisions—whether we are talking about software customizations, medical treatments, public policy or business decisions—improvements in discovering and predicting individual treatment effects are critical to achieving the best outcomes for every single person. Successful pairing of causal inference techniques with statistical machine learning such as deep learning represents one of the next big frontiers in AI research.
To join us on our quest, explore career opportunities (opens in new tab) at MSR AI.