Authors: Will Dubyak, Chhaya Methani
With Satya’s copilot announcements (Microsoft Ignite Opening (opens in new tab) )at Ignite in the rear-view mirror, it’s a good time to talk more about the kind of work and creative thinking that made it possible. If you aren’t already familiar with the new ways to innovate with AI, such as the AI-based copilot to build your flow in seconds, check out the Microsoft Power Automate blog post (opens in new tab). The idea that a plain language prompt can be used to generate a sophisticated automated workflow is powerful, and a glimpse into what the future holds with innovative large language models. But the path to this point was anything but easy and automatic.
As anyone with a background in AI/ML knows, the long pole in the execution tent for a good idea is training data. To train a model to generate a flow from a prompt assumes that we have lots of flows with associated prompts to show the model.
We didn’t. So we needed to be creative.
Our solution took shape in 2 main dimensions. First, we devised a way to generate synthetic data for model training. We had many production flow skeletons that had been scrubbed of Personal Identifiable Information (PII), and we found ways to generate descriptions (or labels) for them to simulate the prompts a user might have generated. We also used a method to generate Natural Language (NL) utterances-flow pairs that we knew to be empirically relevant based on historical patterns in our existing Microsoft Power Automate flow data.
A Power Automate flow is made up of a trigger that “activates” the flow and steps that perform actions upon that trigger. For example:
- “When I get an email from my manager, send me a Teams notification”;
- “Send me a message on Teams when a task is completed in Planner;”
- “If I receive an email that contains the subject ‘invoice’ create an item on SharePoint”.
We trained the first version of the model by using training data generated through manually generated prompts for the flows. We are using OpenAI Codex, which is the engine behind the GitHub Copilot tool which generates executable code from a natural language prompt. Because large language models lend themselves to new domains, we started achieving excellent results almost immediately.
The model works by pairing a workflow with a natural language description to use as training data. The model – which we refer to internally as NL2Flow – learns the correspondence between the language and the flow and is later able to generate a new flow in response to a natural language prompt. (Interestingly, we have learned that it is working in far more than English; there was intense interest among Japanese users immediately after Ignite; even though it’s not specifically trained in Japanese, it works surprisingly often!) There are many working production flows available, but very few of them have a description we can use in model training and testing.
Generating synthetic data
We augmented the data we had by generating synthetic (meaning “we created ourselves”) natural language query-flow pairs.
Note that this is a reverse of the NL2Flow models. As a practical matter, this included fine tuning of a Codex model to generate new descriptions of an existing production flow, as well as inducing variation in the flow language by paraphrasing. The objective is not just a greater volume of training flows and descriptions, but also a broader selection of triggers and actions with which to generate flows. The team took two approaches:
- Reverse the original NL2Flow process and generate NL utterance for existing flows
- Use a context grammar to generate synthetic label/flow pairs
Flow2NL
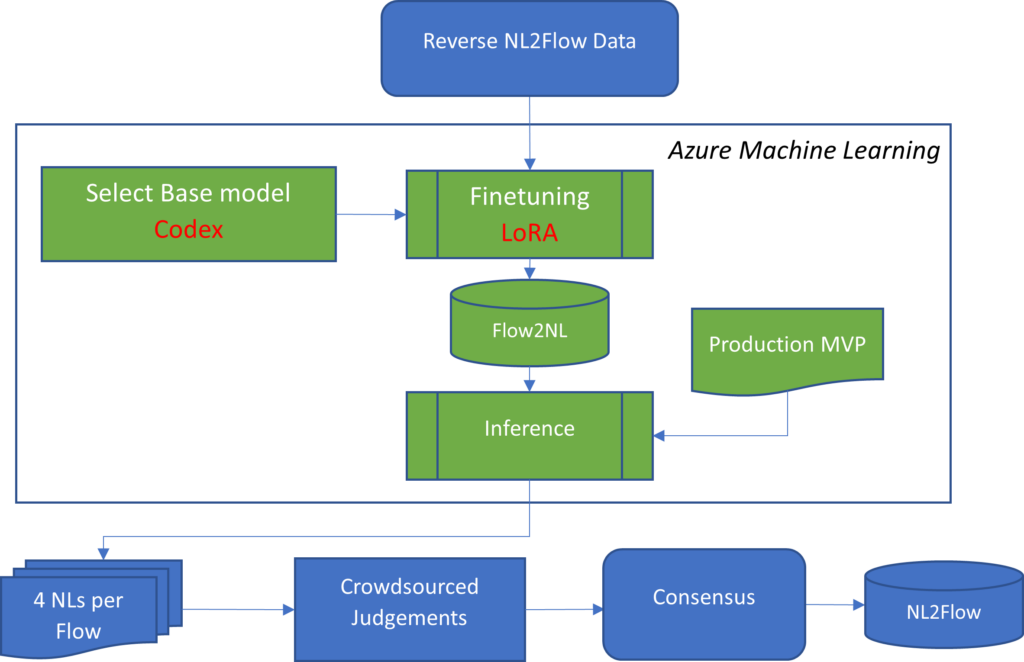
The first effort was to use NLG (Natural Language Generation) to generate NL descriptions from anonymized production flows.
The figure below indicates the process. We input flow code to a fine-tuned Codex model and generated multiple natural language descriptions of flow activity. For economy of effort, these descriptions were submitted to judges for human review; they selected the ones they thought most accurate. On the first pass, 92% of data samples (flows) processed with this approach had agreement of 2 or more judges on at least one NL utterance that the model output.
As an example, consider this flow:
Flow Code:
triggeroutputs = await shared_office365.OnNewEmailV3(); // Trigger Function
outputs_forward_email = shared_office365.ForwardEmail_V2(‘message_id’: triggeroutputs?[‘body’]?[‘MessageId’]) // Forward email function
The Flow2NL model generates the following paraphrased utterances, all of which result in the generation of the above flow.
- Forward emails to a specific address
- Forward email to another address
- Forward emails from a specific address to a different address
Training the model with samples generated this way increases the robustness of the model to language variations. The flow chart below shows the flow of training data generated from Flow2NL pipeline, which is then used to train the NL2Flow model.
Context Grammar
As shown in Table 1, the extra data from Flow2NL helped in our efforts to produce good flow descriptions, but not as much as we needed. To achieve more diversity in flow descriptions we used a process called “Context Grammar” to vary flow descriptions. We iterated over all possible functions (with their corresponding prompts) needed to “construct” a flow. We created a tool called DataGen, that generates these combinations given a config file that contains the following:
- The grammar defines groups of co-occurring functions and their order in the flow. The grammar includes code patterns as well as the corresponding NL prompts, needed to replicate a real flow.
- The list of all possible functions allowed in this group (both triggers and actions) and
- The NL prompts or “patterns” that correspond to these functions.
For example, consider the following config file describing the grammar structure to save attachments from an email. Please note that we only show iterations over one pattern (@SaveTo@) to keep it simple. The tool can expand multiple patterns recursively.
Code Pattern:
triggeroutputs = await shared_office365.OnNewEmailV3(); // Trigger Function
// For loop on email attachments
for (items_foreach in triggeroutputs?[‘body’]?[‘attachments’])
{
//Grammar pattern for set of possible functions allowed under this group
@SaveTo@
}
Corresponding NL Prompts describing the above code (Note: there are many ways to describe a given code):
Save email attachments to @0@
Store every email attachment I receive to @0@
Pull attachments from outlook to @0@
In the above NL-flow pair, the parameters enclosed in @ will be sampled from the list mentioned in Steps 2 & 3. The same config describes the function values that @SaveTo@ can take. The corresponding NL part will be used to replace all occurrences of @0@.
Sampling from known patterns allows us to generate data inexpensively while still preserving relevant triggers and actions from our users. We added additional samples for under-represented connectors.
Contextual Grammar enriched the training set for the NL2Flow model. See the results section for a detailed description of the impact of including both Flow2NL and Context Grammar.
Model Training & Results
Using the two approaches, we generated about 800 new training samples with Flow2NL, and about 3,000 new samples using the Context Grammar approach. We ensured the distribution of generated flows across topics was about the same as in the production samples.
We created a test set for tracking improvements across models trained on different iterations of the data. We computed a custom similarity metric for determining flow similarity between the predicted and the ground truth code. We do a fuzzy match to compute similarity by counting the number of correctly predicted API calls (includes triggers as well as actions) divided by the total number of predicted functions. For e.g. if the ground truth for a certain flow has 5 function calls; the model predicted 6 functions and 4 of those are correct, the similarity measure would be 4/6 = 0.66.
| Source | Relative improvement in Similarity Measure |
| Baseline Model + Flow2NL | 3.2% |
| Baseline + Context Grammar | 9.5% |
| Base + Flow2NL + Context Grammar | 15.9% |
As we can see above, both Flow2NL and Context Grammar give the best improvements over baseline when both are added to the train set. This shows how powerful it is to add synthetic samples to improve the model strategically to improve as and where needed.
We invite you to create a Power Automate flow today by following this link Power Automate (opens in new tab), and clicking on “Create +.” Select the option “You describe it, AI builds it”. Please leave feedback or ask a question on our forum Microsoft Power Automate Community – Power Platform Community! We are continuously improving the model and would love to hear from you!