

A unified modeling story for artificial intelligence
“Unity” is a common goal in many disciplines. For example, in the field of physics, scientists have long been pursuing the grand unification theory, which is a single theory that can be used to explain the interaction between different forces. There is also a similar goal of “unity” in the field of artificial intelligence. In the current wave of deep learning, we have made a large stride towards achieving the goal of unity. For example, we usually follow the same process for new AI tasks : collect data, label it, define network architectures, and train network parameters. However, in different AI sub-fields, basic modeling methods vary and are not uniform. In natural language processing (NLP), the current dominant modeling network is Transformer; in computer vision (CV), for a long time, the dominant architecture was convolutional neural networks (CNN); in social computing field, the dominant architecture is graph networks; and so on.
However, the situation has changed since the end of last year, when Transformer began to demonstrate revolutionary performance improvements for a variety of computer vision tasks. This indicates that CV and NLP modeling could potentially be unified under the Transformer architecture. This trend is highly beneficial for both fields: 1) it can facilitate joint modeling of visual and textual signals; 2) it can enable better sharing of modeling knowledge between the two fields, which would accelerate progress in both fields.
Transformer’s outstanding performance in visual tasks
The pioneering work of Vision Transformer is ViT [1], published by Google on ICLR2021. It divides images into patches (e.g., 16×16 pixels) and treat them as “tokens” in NLP. Then a standard Transformer encoder is applied to these “tokens,” and the image is classified according to the output feature of the “CLS” token. Using a vast amount of pre-training data, i.e., Google’s internal 300 million-image classification dataset JFT-300M, it achieved top-1 accuracy of 88.55% on the ImageNet-1K validation set, setting a new record for this benchmark.
ViT applies Transformer on images in a simple and straightforward way, where, because it does not carefully consider the characteristics of visual signals, it is mainly used for image classification tasks. The capabilities of Transformer on tasks of other granularity levels remain unknown, and the academic community has carried out a lot of work to this end. Among the efforts, the Swin Transformer [2] significantly refreshed previous records on object detection and semantic segmentation benchmarks, giving the community greater confidence that the Transformer structure will become the new mainstream for visual modeling. Specifically, on COCO, an important object detection benchmark, Swin Transformer obtained 58.7 box AP and 51.1 mask AP, which were respectively 2.7 and 2.6 points higher than the previous best single-model method. A few months later, performance accuracy on this benchmark was further raised to 61.3 box AP and 53.0 mask AP by improving the detection framework and making better use of the data. Swin Transformer has also achieved significant performance improvements on the ADE20K, an important evaluation benchmark for semantic segmentation, reaching 53.5 mIoU, which is 3.2 mIoU higher than the previous best approach. The accuracy was further improved to 57.0 mIoU within a few months.

Figure 1: Records on the COCO Object Detection benchmark across the years
In addition to excelling in object detection and semantic segmentation tasks, the Swin Transformer based approaches have also demonstrated strong performance in many visual tasks, including video motion recognition [3], visual self-supervised learning [4][5], image restoration [6], pedestrian Re-ID [7], medical image segmentation [8], etc.
The main idea of the Swin Transformer is simple: combine the Transformer architecture, which is powerful in modeling, with several important visual signal priors. These priors include hierarchy, locality, and translation invariance. An important design in the Swin Transformer is the shifted non-overlapping windows, which, unlike traditional sliding windows, are more hardware-friendly and can result in faster actual running speed. As shown on the left-hand side of the following figure, in the sliding window design, different points use different neighborhood windows to calculate the relationship, which is hardware unfriendly. As shown by the right sub-figure, in the non-overlapping windows used by Swin Transformer, the points within a same window are calculated using the same neighborhoods and are more speed friendly. Actual speed tests show that the non-overlapping window method is about two times faster than the sliding window approach. In addition, shifting is done in two consecutive layers. In layer L, the window partitioning starts from the upper-left corner of an image, and in Layer L-1, the window partitioning shifts half a window downwards and to the right. This design ensures that there is information exchange between windows that do not overlap.
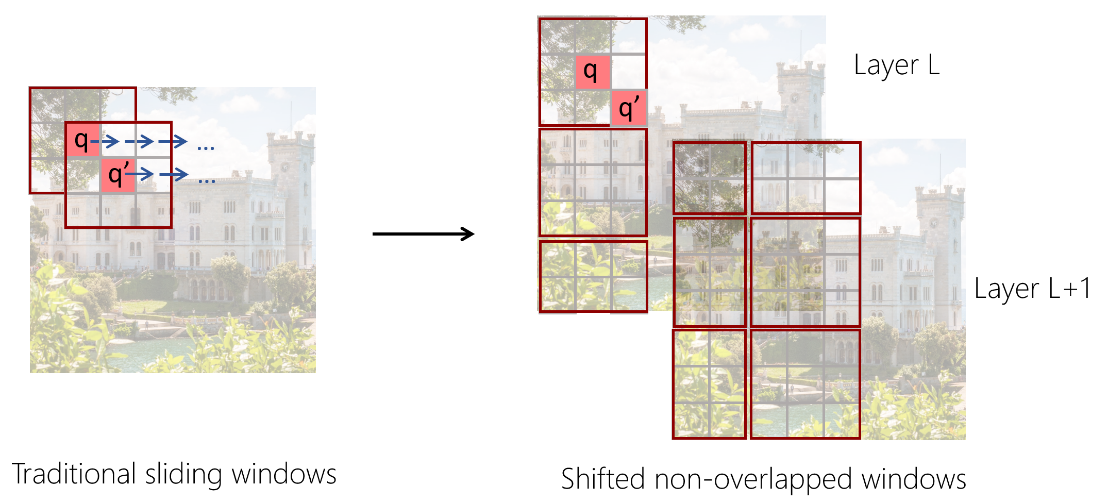
Figure 2: The traditional sliding window method (left) is less friendly to GPU memory accessing and actual speed is slower due to different queries using different key sets. The shifted non-overlapping window method (right) has different queries sharing the same key set, and so it runs faster and is more practical.
Over the past half a year, numerous variants of Vision Transformers have emerged from academia, including DeiT [9], LocalViT [10], Twins [11], PvT [12], T2T-ViT [13], ViL [14], CvT [15], CSwin [16], Focal Transformer [17], Shuffle Transformer [18], etc.
Five reasons to embrace Transformer in Computer Vision
In addition to refreshing the performance records of many visual tasks, Vision Transformers have demonstrated many benefits over previous CNN architectures. In fact, over the past four years, academics have been exploiting the benefits of Transformers in computer vision, which can be summed up in five aspects as shown in the following illustration.
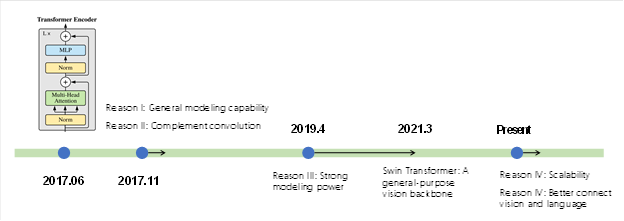
Figure 3: Five advantages of Transformer architectures that have been unearthed over the past four years
Reason 1: General modeling capabilities
Transformer’s general modeling capabilities come from two aspects. On one hand, Transformer can be seen as performing on a graph. The graph is fully connected, and the relationships between nodes are learned in a data-driven way. Transformer modeling is highly versatile because any concept, whether concrete or abstract, can be represented by nodes in a graph, and the relationship between concepts can be characterized by graph edges.
On the other hand, Transformer has good generality in establishing the relationships between graph nodes through a philosophy of validation: no matter how heterogeneous the nodes are, their relationships can be established by projecting them into an aligned space to calculate similarity. As shown on the right-hand side of the following illustration, the graph nodes can be either image patches of different scales, or text input such as “player,” and Transformer can well depict the relationships between these heterogeneous nodes.
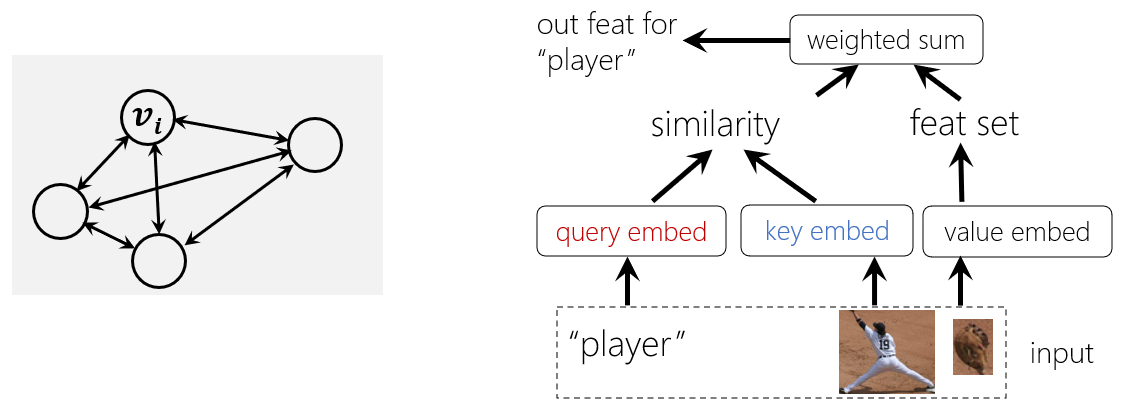
Figure 4: Two main reasons for Transformer’s universal modeling capabilities: graph modeling (left) and verification philosophy (right)
Likely because of this versatile modeling capability, Transformer, along with the attention units it relies on, can be applied to a wide variety of visual tasks. To be specific, computer vision mainly involves two basic granularity elements to process: pixels and objects, and so computer vision tasks mainly involve the three kinds of relationships between these basic elements: pixel-to-pixel, object-to-pixel, and object-to-object. Previously, the first two relationship types were mainly implemented by convolution and RoIAlign respectively, and the last relationship was often disregarded in modeling. However, the attention unit in Transformer can be applied to all three basic relational modeling types because of its general modeling capability. In recent years, there have been a lot of representative work in this area, including: 1) non-local networks [19], where Xiaolong Wang et al. used attention units to model pixel-to-pixel relationships and demonstrated that attention units could help with tasks such as video action classification and object detection, and Yuhui Yuan et al. applied it to semantic segmentation, achieving significant performance improvements [20]; 2) object relation networks [21], where attention units have been used to model object relationships in object detection, and this module has also been widely used in video object analysis [22,23,24]; 3) modeling the relationship between objects and pixels, with typical works including DETR [25], Learn Region Feat [26], RelationNet++ [27], etc.
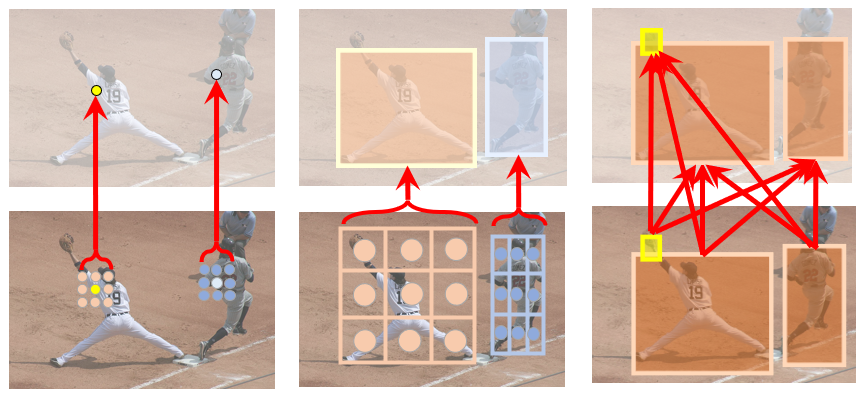
Figure 5: Transformer can be applied to model relationships between various basic visual elements, including pixel-to-pixel (left), object-to-pixel (center), and object-to-object (right)
Reason 2: Convolution complementarity
Convolution is a local operation, and a convolution layer typically models only the relationships between neighborhood pixels. Transformer is a global operation, and a Transformer layer can model the relationships between all pixels. The two-layer types complement each other very well. Non-local networks were the first to leverage this complementarity [19], where a small number of Transformer self-attention units were inserted into several places of the original convolution networks as a complement. This has been shown to be widely effective in solving vision problems in object detection, semantic segmentation, and video action recognition.
Since then, it has also been found that non-local networks have difficulty in truly learning the second order pairwise relationship between pixels and pixels in computer vision [28]. To address this issue, certain improvements have been proposed for this model, such as disentangled non-local networks (DNL) [29].
Reason 3: Stronger modeling capabilities
Convolution can be thought of as a template matching approach with the same template filtering across different locations in an image. The attention unit in Transformer is an adaptive filter, and the filter weights are determined by the composability of two pixels. This type of computing module possesses stronger modeling abilities.
The local relational network (LR-Net) [30] and SASA [31] were the first methods used to apply Transformer as an adaptive computing module to visual backbone networks. They both limited self-attention computation to a local sliding window and achieved better accuracy than ResNet using the same theoretical computational budget. However, while the computational complexity is the same as ResNet in theory, LR-Net is much slower to use in practice. One of the main reasons is that different queries use different key sets, which makes it less friendly for memory access, as shown on the left-hand side of Figure 2.
Swin Transformer proposed a new local window design called shifted windows. This local window method divides the image into non-overlapping windows so that within the same window, the collection of keys used by different queries would be the same, resulting in better actual computational speed. In the next layer, the window configuration moves half a window downwards and to the right, constructing connection between pixels of different windows from the previous layer.
Reason 4: Scalability to model and data size
In the NLP field, the Transformer models have demonstrated great scalability in terms of big models and big data. In the following figure, the blue curve shows that the model size in NLP has increased rapidly in recent years, and we have all witnessed the powerful capabilities of large-scale models, such as Microsoft’s Turing model, Google’s T5 model, and OpenAI’s GPT-3 model.
The emergence of Vision Transformers has also provided an important foundation for the growth of vision models. The largest vision model is Google’s ViT-MoE model, which has 15 billion parameters. These large models have set new records on the ImageNet-1K classification.
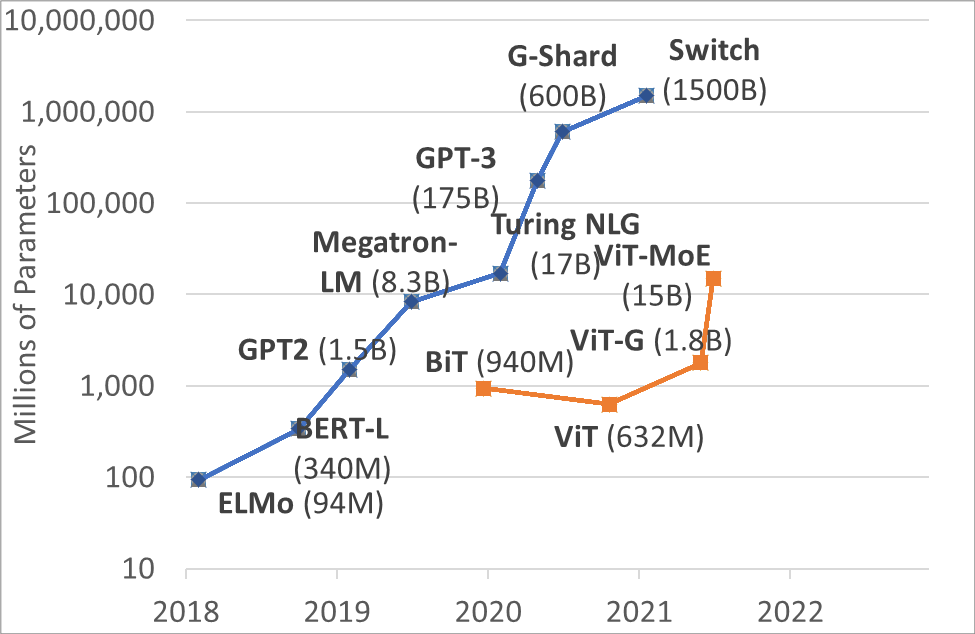
Figure 6: Model size records in the NLP and computer vision fields across recent years
Reason 5: Better connection of visuals and language
In previous visual problems, we have usually only dealt with object categories in the dozens or hundreds. For example, the COCO object detection task contains 80 object categories, and the ADE20K semantic segmentation task contains 150 categories. The invention and development of Vision Transformer models has brought the vision and NLP fields closer to each other, which helps to connect visual and NLP modeling, and links visual tasks to all semantics involved in language. Pioneering work in this area include OpenAI’s CLIP [33] and DALL-E [34].
Considering the above advantages, we believe that Vision Transformers will usher in a new era of computer vision modeling, and we look forward to working together with both academics and industry researchers to further explore the opportunities and challenges that this new modeling approach presents to the visual field.
Reference
[1] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. ICLR 2021
[2] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. ICCV 2021
[3] Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, Han Hu. Video Swin Transformer. Tech report 2021
[4] Zhenda Xie, Yutong Lin, Zhuliang Yao, Zheng Zhang, Qi Dai, Yue Cao, Han Hu. Self-Supervised Learning with Swin Transformers. Tech report 2021
[5] Chunyuan Li, Jianwei Yang, Pengchuan Zhang, Mei Gao, Bin Xiao, Xiyang Dai, Lu Yuan, Jianfeng Gao. Efficient Self-supervised Vision Transformers for Representation Learning. Tech report 2021
[6] Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, Radu Timofte. SwinIR: Image Restoration Using Swin Transformer. Tech report 2021
[7] https://github.com/layumi/Person_reID_baseline_pytorch
[8] Hu Cao, Yueyue Wang, Joy Chen, Dongsheng Jiang, Xiaopeng Zhang, Qi Tian, Manning Wang. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. Tech report 2021
[9] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou. Training data-efficient image transformers & distillation through attention. Tech report 2021
[10] Yawei Li, Kai Zhang, Jiezhang Cao, Radu Timofte, Luc Van Gool. LocalViT: Bringing Locality to Vision Transformers. Tech report 2021
[11] Xiangxiang Chu, Zhi Tian, Yuqing Wang, Bo Zhang, Haibing Ren, Xiaolin Wei, Huaxia Xia, Chunhua Shen. Twins: Revisiting the Design of Spatial Attention in Vision Transformers. Tech report 2021
[12] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. ICCV 2021
[13] Li Yuan, Yunpeng Chen, Tao Wang, Weihao Yu, Yujun Shi, Zihang Jiang, Francis EH Tay, Jiashi Feng, Shuicheng Yan. Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet. Tech report 2021
[14] Pengchuan Zhang, Xiyang Dai, Jianwei Yang, Bin Xiao, Lu Yuan, Lei Zhang, Jianfeng Gao. Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding. Tech report 2021
[15] Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang. CvT: Introducing Convolutions to Vision Transformers. ICCV 2021
[16] Xiaoyi Dong, Jianmin Bao, Dongdong Chen, Weiming Zhang, Nenghai Yu, Lu Yuan, Dong Chen, Baining Guo. CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows. Tech report 2021
[17] Jianwei Yang, Chunyuan Li, Pengchuan Zhang, Xiyang Dai, Bin Xiao, Lu Yuan, Jianfeng Gao. Focal Self-attention for Local-Global Interactions in Vision Transformers. Tech report 2021
[18] Zilong Huang, Youcheng Ben, Guozhong Luo, Pei Cheng, Gang Yu, Bin Fu. Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer. Tech report 2021
[19] Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He. Non-local Neural Networks. CVPR 2018
[20] Yuhui Yuan, Lang Huang, Jianyuan Guo, Chao Zhang, Xilin Chen, Jingdong Wang. OCNet: Object Context for Semantic Segmentation. IJCV 2021
[21] Han Hu, Jiayuan Gu, Zheng Zhang, Jifeng Dai, Yichen Wei. Relation Networks for Object Detection. CVPR 2018
[22] Jiarui Xu, Yue Cao, Zheng Zhang, Han Hu. Spatial-Temporal Relation Networks for Multi-Object Tracking. ICCV 2019
[23] Yihong Chen, Yue Cao, Han Hu, Liwei Wang. Memory Enhanced Global-Local Aggregation for Video Object Detection. CVPR 2020
[24] Jiajun Deng, Yingwei Pan, Ting Yao, Wengang Zhou, Houqiang Li, and Tao Mei. Relation distillation networks for video object detection. ICCV 2019
[25] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko. End-to-End Object Detection with Transformers. ECCV 2020
[26] Jiayuan Gu, Han Hu, Liwei Wang, Yichen Wei, Jifeng Dai. Learning Region Features for Object Detection. ECCV 2018
[27] Cheng Chi, Fangyun Wei, Han Hu. RelationNet++: Bridging Visual Representations for Object Detection via Transformer Decoder. NeurIPS 2020
[28] Yue Cao, Jiarui Xu, Stephen Lin, Fangyun Wei, Han Hu. GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond. ICCV workshop 2019
[29] Minghao Yin, Zhuliang Yao, Yue Cao, Xiu Li, Zheng Zhang, Stephen Lin, Han Hu. Disentangled Non-Local Neural Networks. ECCV 2020
[30] Han Hu, Zheng Zhang, Zhenda Xie, Stephen Lin. Local Relation Networks for Image Recognition. ICCV 2019
[31] Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, Jonathon Shlens. Stand-Alone Self-Attention in Vision Models. NeurIPS 2019
[32] Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, André Susano Pinto, Daniel Keysers, Neil Houlsby. Scaling Vision with Sparse Mixture of Experts. Tech report 2021
[33] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever. Learning Transferable Visual Models from Natural Language Supervision. Tech report 2021
[34] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, Ilya Sutskever. Zero-Shot Text-to-Image Generation. Tech report 2021