


Maximize machine learning and data management in Azure Data Manager for Energy
Within the energy industry, legacy assets and on-premises data storage can make integrating with the OSDU® Data Platform a challenge. In particular, the specialized disciplines within the subsurface domain often lead to the creation of data silos. While these silos serve a purpose by enabling specialists to combine data with their expertise, they also pose challenges for broader data integration efforts. The OSDU® Data Platform offers a robust set of data schemas, but the most valuable data often resides within these specialist silos, necessitating complex data synchronization workflows.
Microsoft Azure Data Manager for Energy is a scalable, enterprise-grade, cloud-based OSDU® Data Platform service that aligns with the requirements of the OSDU® Technical Standard for open-source innovation. As the energy industry evolves, the OSDU® Data Platform will play a pivotal role in driving efficiency and innovation by bringing the industry’s domain data into the cloud. This will enable customers and independent software vendors (ISVs) to use the data estate to enable new AI scenarios. By embracing these changes strategically and leveraging Azure Data Manager for Energy and tools from independent software vendors, such as KADME, companies can maximize the value of their legacy assets while embracing the future of data integration and analysis. This can go further with generative AI applications that go beyond personal productivity.
KADME is one of Microsoft’s partners within the energy industry, adding value for customers by developing tools that integrate with Azure Data Manager for Energy. Equipped with extensive knowledge of Azure Data Manager for Energy, KADME has designed tools that can extract information, but also fine tune document labelling for OSDU® Data Platform and Azure Data Manager for Energy manifests, significantly impacting the success of OSDU® Data Platform search queries. Furthermore, with this fine tuning, KADME can help contextualize information so generative AI can understand the search query in the proper context, minimizing hallucination and returning the correct results for ambiguous asks.
With the KADME solution on Azure Data Manager for Energy, leveraging Azure large language models and domain specific semantic ranking algorithm, customers can:
- Accelerate adoption of OSDU® while remaining at the cutting edge of AI, search, and enrichment technology.
- Control what goes into OSDU® and when, using LUMIN workflows and intuitive graphical interface.
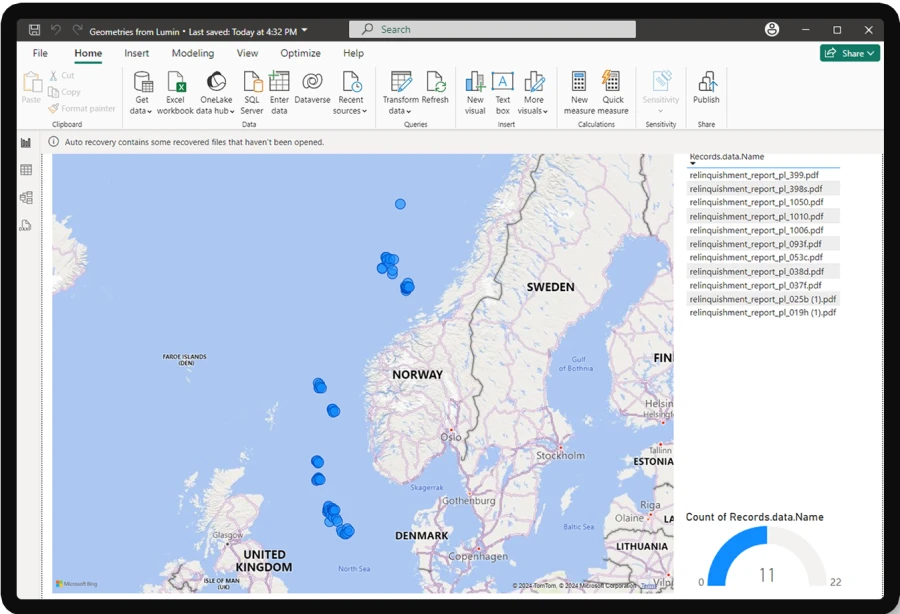
- Discover subsurface data on the LUMIN map and the extracted, classified images.
- Use domain-specific natural language queries to discover documents in OSDU®.
Azure Data Manager for Energy
Reduce time, risk, and cost of energy exploration and production

Preparing data for machine learning with LUMIN
KADME’s platform, LUMIN, bridges the gap between different data types in Azure Data Manager for Energy by automatically translating data to fit its requirements, ensuring synchronization while leaving the data unchanged at the source. Leveraging Elasticsearch, LUMIN offers scalability and an intuitive interface for transforming data between formats and OSDU® Data Platform schemas, making it an appealing alternative to in-house development. Specializing in extracting information from unstructured sources like documents and PDFs, LUMIN acts as a high-performant search engine at scale, particularly adept at handling subsurface data. Its integration with Microsoft SharePoint and Azure Data Manager for Energy streamlines data ingestion and extraction processes, reducing the need for extensive data preparation for machine learning endeavors.
LUMIN extracts content from documents and images.
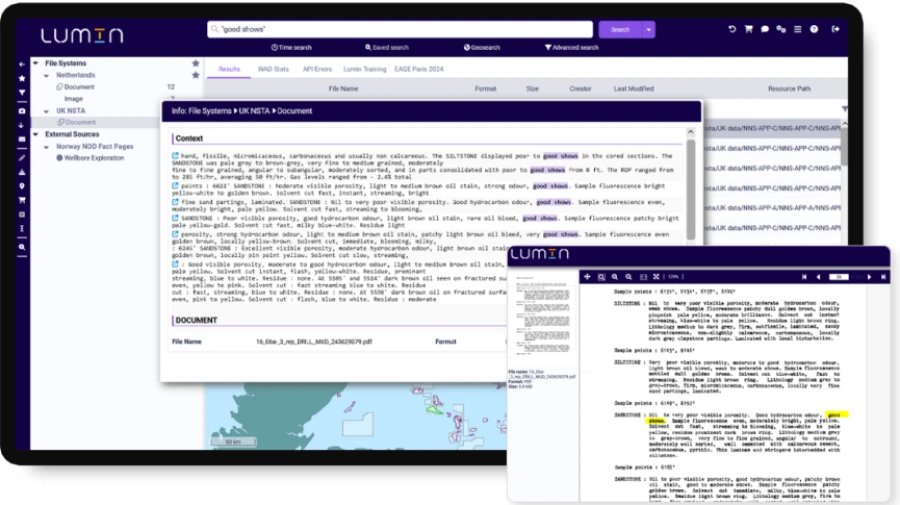
It extracts and classifies subsurface images.
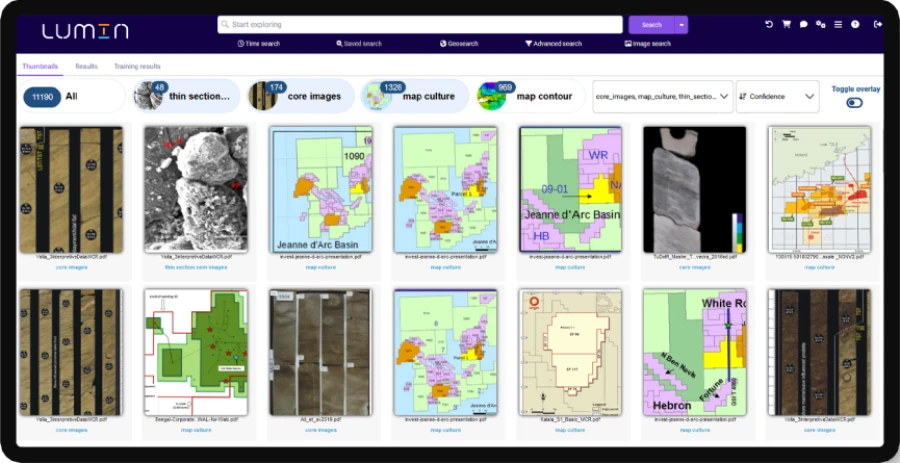
It then enriches this content with Metadata and establishes spatial data.
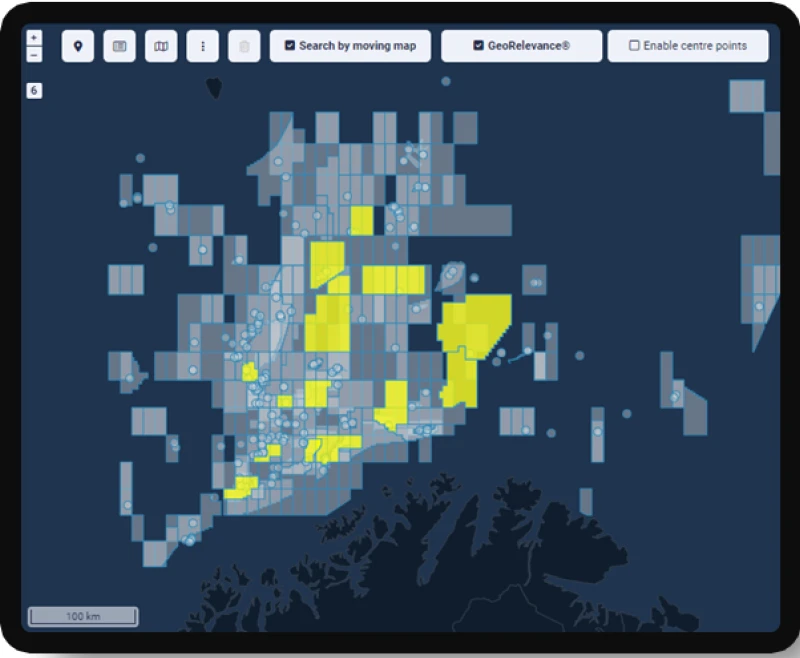
It transforms this content into semantic vectors using Fabriq, a large language model orchestration platform, enabling users to converse using domain specific natural language.
Data is transformed from unstructured to structured data and delivered to Azure Data Manager for Energy.
Enhance workflow and data discoverability with large language models
Using an energy sector-specific approach with large language model is crucial for efficiency and relevance. The energy industry has its own vocabulary: fish, shoe, and Christmas tree all have specific meanings within the industry that without context, mean something completely different. A “radioactive trap” can be a positive sentiment whereas in other contexts it could be considered negative. When searching for data below a depth of 1,500 meters records must be searched for a total vertical depth above 2,700 meters. These industry and context specific meanings matter.
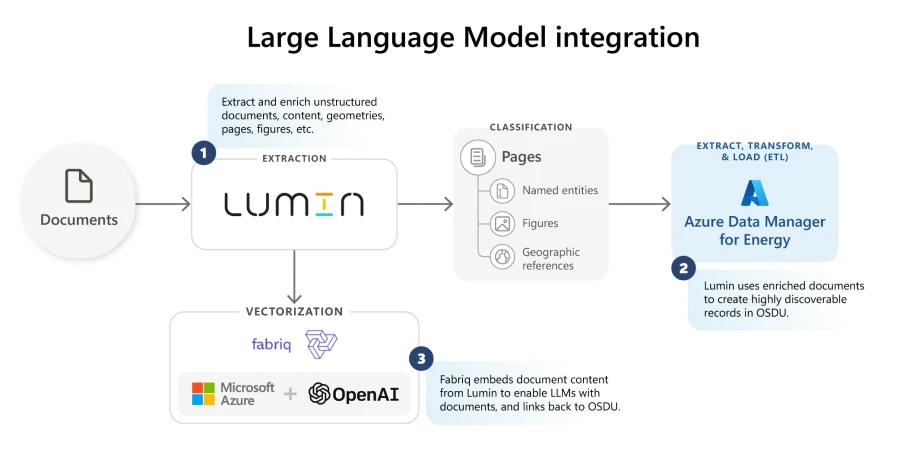
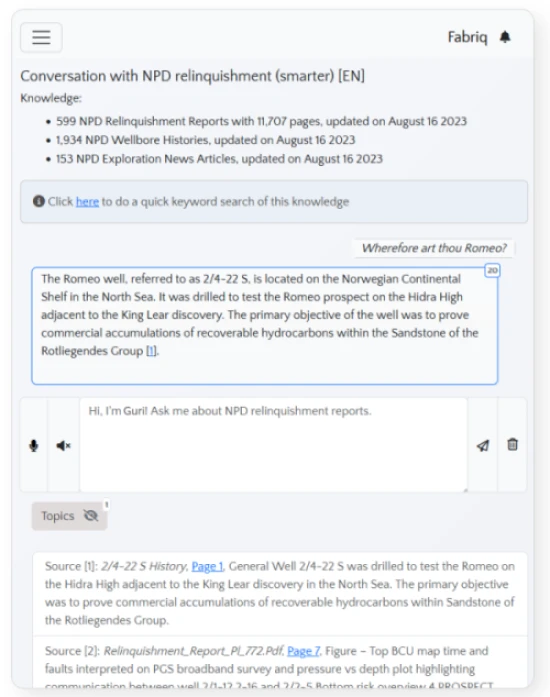
For generative AI in subsurface, KADME works exclusively with Fabriq. Fabriq (pronounced with a hard q, as “fabrique”), is a turnkey solution that weaves structured and unstructured data into workflows and copilots, secured and scaled in Microsoft Azure using OpenAI large language models through Cloud Native Micro Services. This approach delivers trustworthy answers to complex questions, reveals previously hidden business intelligence, and automates tasks that previously were out of reach for AI.
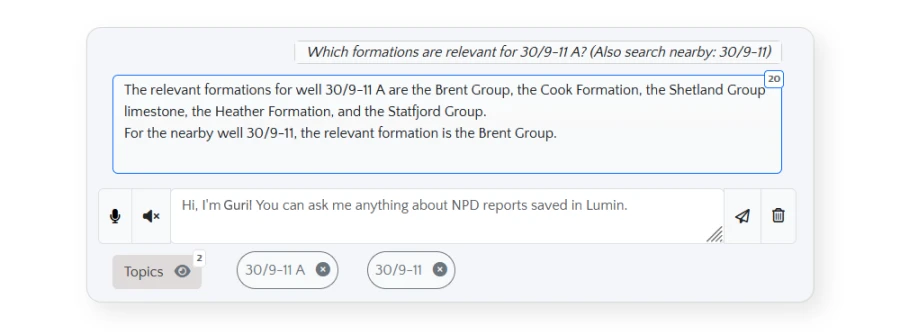
In this example, the user question is: “Which formations are relevant for 30/9-11 A?” Fabriq recognizes 30/9-11A is a wellbore and conducts a spatial search in LUMIN to identify any other wellbores within a given range of this one. The model discovers another wellbore called 30/9-11 and adds it to the user’s question to provide geographically relevant context to the response.
Fabriq empowers energy industry users with a natural language search capability on Azure Data Manager for Energy, ensuring that queries yield relevant and focused results, unlike non-contextual search engines. For instance, while a general search engine or public AI companion may return unrelated information for a query like “wherefore art thou Romeo,” Fabriq retrieves pertinent data, such as details about a field named Romeo, enabling users to swiftly access the information they seek without distractions.
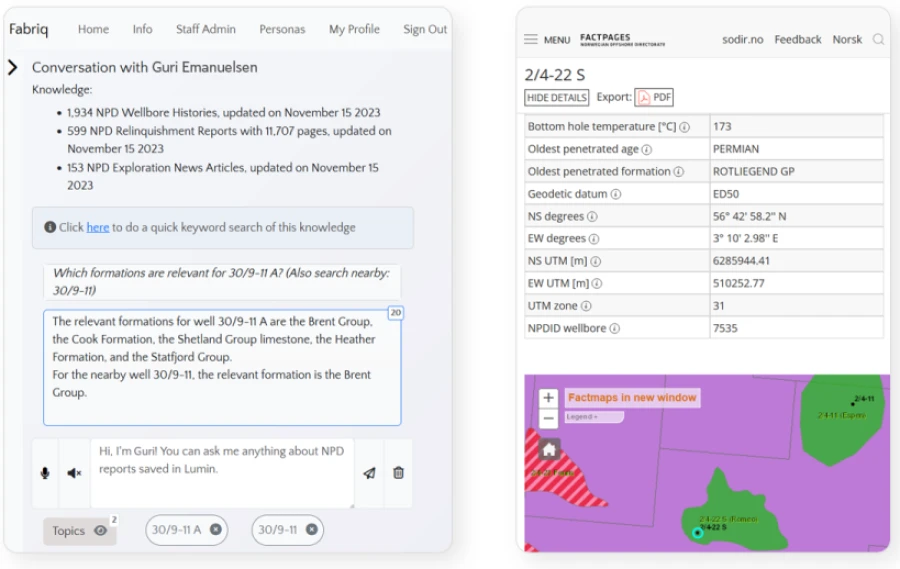
Fabriq pulls data from LUMIN and then interacts with this data using natural language. It enhances the discoverability of data within Azure Data Manager for Energy in a conversational manner, allowing users to easily access knowledge that companies have heavily invested in—particularly final well reports. Not only does this make individual workflows more efficient, but it also allows companies to maximize their business knowledge and continue to build on decades of detailed reporting.
Learn more about KADME and Microsoft solutions
- Learn more about KADME and Azure Data Manager for Energy.
- Find Azure Data Manager for Energy solutions from KADME and other partnering ISVs on Azure Marketplace.
- Learn more about the Enterprise Data Solution from SLB for Azure Data Manager for Energy.
- Learn more about powering digital transformation with Azure Data Manager for Energy.
- Learn more about how Microsoft partners with energy companies to accelerate digital transformation.
- Learn more about themes and actions critical for energy transition.


